






终终终于来了,依稀记得一年前就被对于LLM在进行复杂推理时,其模型网络内部隐状态表征与形式化推理过程的本质反复困扰着...虽然只是冰山一角吧,但也是很难得看到在这一方向的探索。
近期,核心来自Meta团队成员发表了标题为“…字数超了,请大家自行搜索…”的论文,主要锁定研究LLM在数学推理过程中其模型背后的原理,并揭示了LLM在解决简单(小学)数学问题时的隐状态推理过程。
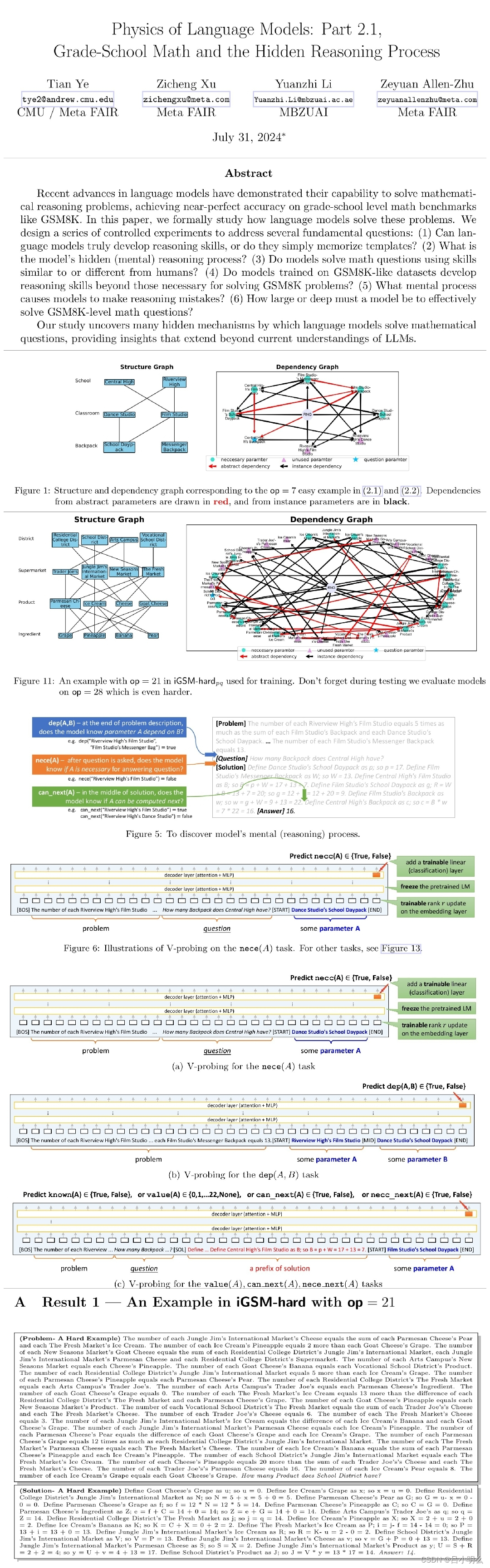
文章创新性的提出了一种层次化类别图结构的数学问题合成机制,依赖图控制参数间关系的方式来尝试使得合成的数据分布更加美丽,这里我相信也给了大家面向未来更复杂推理问题的数据构造提供了一些思路和指引,相信不管对于未来复杂推理类问题通过self-play方式模拟真实环境反馈还是通过这种先验的抽象化结构合成,我想都会成为未来我们AIer需要面临的挑战和机遇,不过我还是更倾向于类self-play+RL方式 ;)
文中的方法通过合成的大量分布看似smooth&nice的数据样本,作者们从头pre-train了模型,以避免采用开放数据集下pre-train模型带来的后续评估干扰,原因也比较简单,这里不再赘述,大家感兴趣可以自行啃下原文,或者看到后面的研究结论,相信大家也就明晰了呢,ps:这篇paper确实难啃,感觉是我是过去一年内难啃的top...
如下正文↓
向大伙列一些我感兴趣的一些心得,想法和阐释:
Ⅰ. 模型确实可以学习到一些复杂而抽象的数学概念及推理模式,而不是硬性的记住训练模板 · 这一点思路已经被前人采用不同角度大量验证过了,不过本文中由于采用了从头pre-training的方式,应该会更有说服力 (对,在这等着呢 ;)
Ⅱ. 模型看似像人一样,可以快速找到最短推理路径,避免被其他推理过程中的干扰参数项所影响,表明在问题提出后, 模型已经提前规划了必要参数的完整列表(尊重原文表述,其实即推理路径) · 这里我感觉也是比较符合直觉与理性的,主要还是取决于用于训练的过程性数据采样以及训练目标的设定,如果再进一步思考,我想本质上应该是RL中探索与利用的过程性平衡在捣鬼吧 :),也许改变文中PT或SFT的ground truth模式为online训练模式可能会带来不一样的惊艳~
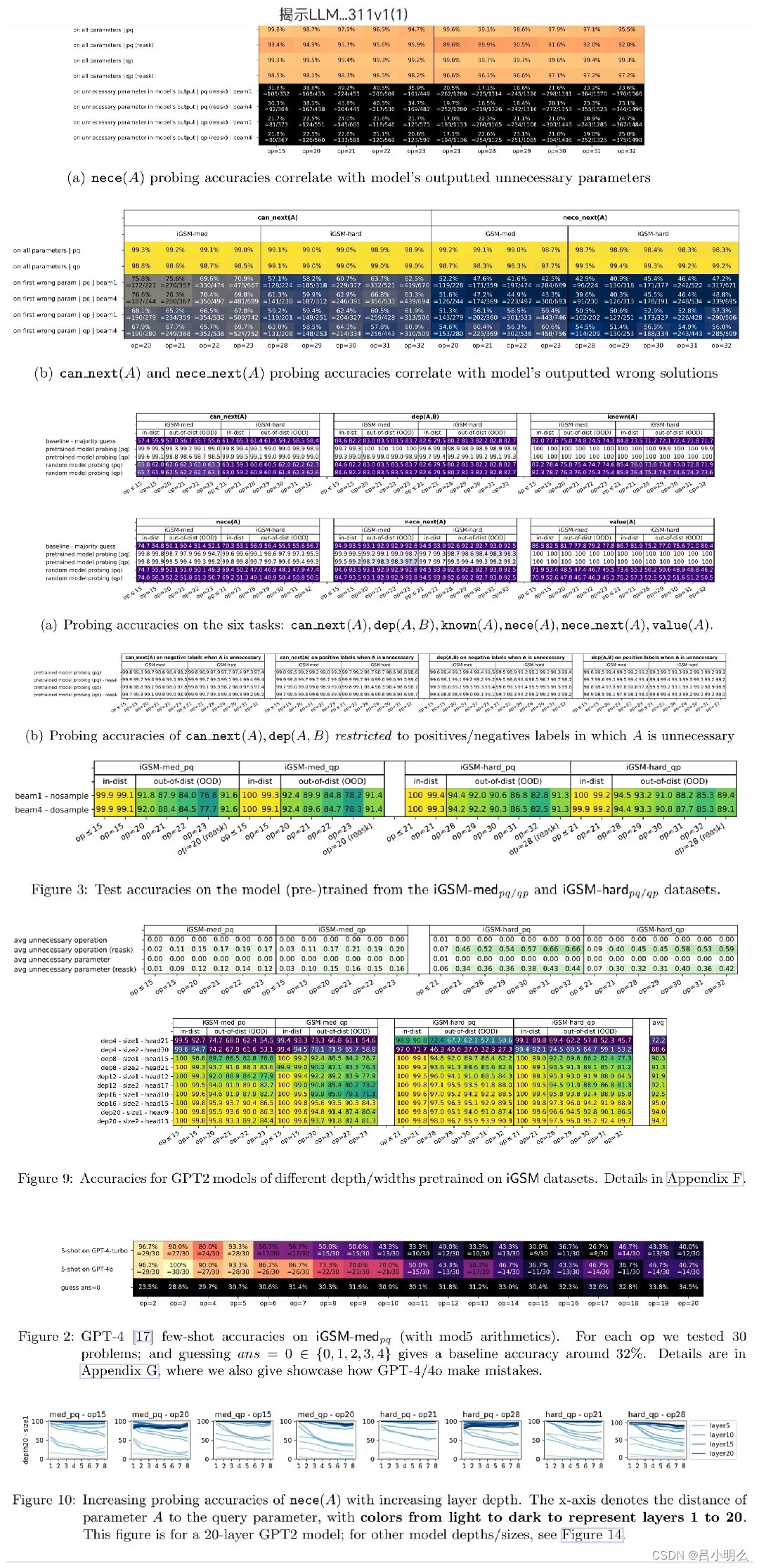
Ⅲ. 与Ⅱ看似又相反,论文通过一种近线性模型精度探测方法,发现模型在推理前,都会预处理问题表述中的全局数学概念/全参数依赖图(原表述),类似不同于人类的演绎推理,正如如原论文所说, 这一发现对未来的探索将会很有用,同时这可能是LLM获得超出学习其训练前数据所需的技能的第一个证据,即是AGI中的G的初步信号...也许呢...我认为也许这亦是一种模型泛化能力层次化的自然迁移与过滤,也许这也是模型在经历了大规模的数据样本下直觉上对数学上的一种感性而非理性的决策,恩,还是回到Ⅱ的探索与利用的过程性平衡...
除了上述研究内容外,文中还验证了模型推理错误来自于隐性推理过程中的理性错误而非随机错误,以及模型的深度对复杂推理的意义,因字数和时间原因,本篇笔记先不提及,后续有机会再续~
















 375
375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









