import re
import requests
url ='https://book.zongheng.com/chapter/867252/57628310.html'
res_str = requests.get(url=url).text
# print(res_str)
title = re.findall(r'name="keywords" content="(.*?)"/>',res_str)[0]
book_content= re.findall(r'<p>(.*?)</p>',res_str)# print(book_content)print(title)for c in book_content[:-1]:print(c)
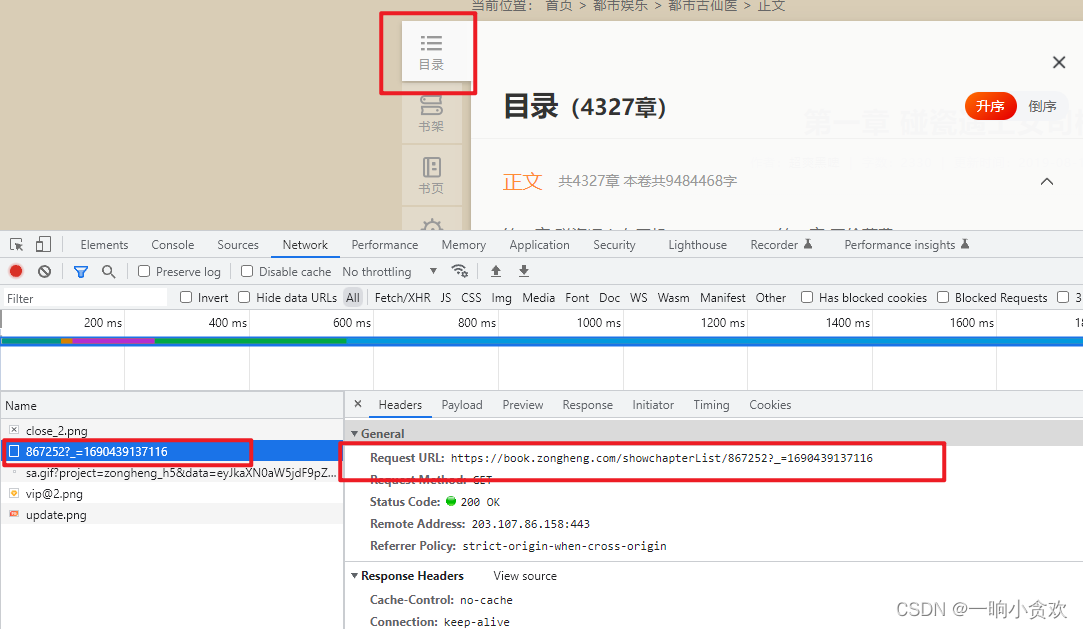
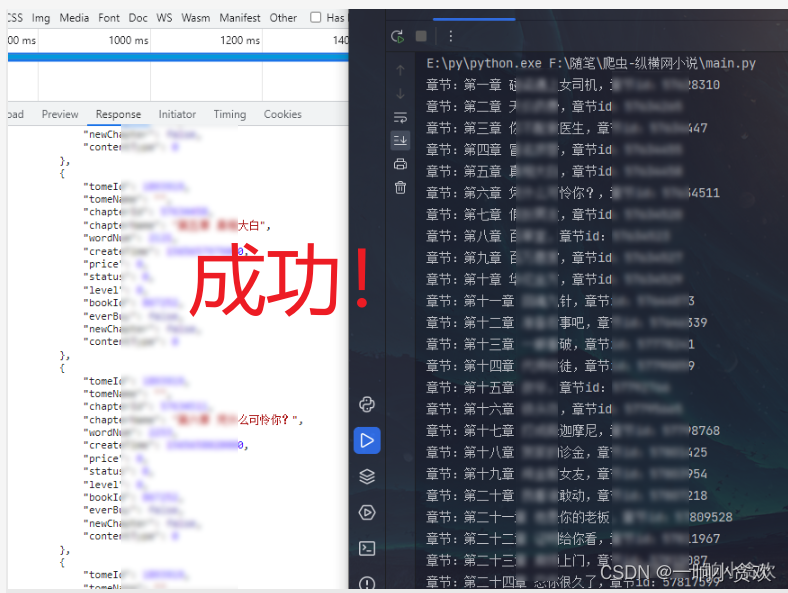
第三步,获取所有章节:
点击【目录】,查看章节来源的URL
由此发现,每一本书都有自己的 id,参数为:【_】下划线
代码 3 (获取所有章节的页码数+数据清洗——完整版在最后)
book_id ='1690437685919'
data = requests.get("https://book.zongheng.com/showchapterList/867252?_={book_id}").text
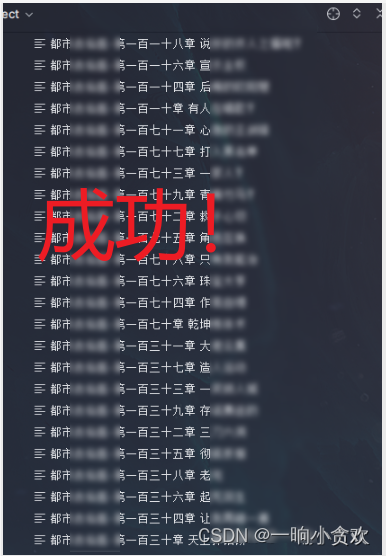
data = json.loads(data)# print(data)for i in data['data']['showTomeViewList'][0]['chapterViewList']:print(f'章节:{i["chapterName"]},章节id:{i["chapterId"]}')
与代码2进行合并,形成完整版代码:
完整版代码:
book_id = ‘1690437685919’,这里可以替换自己喜欢的bookid
import json
import requests
book_id ='1690437685919'
data = requests.get("https://book.zongheng.com/showchapterList/867252?_={book_id}").text
data = json.loads(data)# print(data)for i in data['data']['showTomeViewList'][0]['chapterViewList']:withopen(f"./结果/xxxx-{i['chapterName']}",'w',encoding='utf-8')as f:print(f'章节:{i["chapterName"]},章节id:{i["chapterId"]}')
url =f'https://book.zongheng.com/chapter/867252/{i["chapterId"]}.html'
res_str = requests.get(url=url).text
# print(res_str)
title = re.findall(r'name="keywords" content="(.*?)"/>',res_str)[0]
book_content= re.findall(r'<p>(.*?)</p>',res_str)# print(book_content)print(title)for c in book_content[:-1]:# print(c)
f.write(c+'\n')



























 1941
1941











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











