







来源:投稿 作者:livingbody
编辑:学姐
文章较长,请留意阅读时间
关注公众号【学姐带你玩AI】
回复“天气”领取完整代码
赛题背景
在自动驾驶场景中,天气和时间(黎明、早上、下午、黄昏、夜晚)会对传感器的精度造成影响,比如雨天和夜晚会对视觉传感器的精度造成很大的影响。此赛题旨在对拍摄的照片天气和时间进行分类,从而在不同的天气和时间使用不同的自动驾驶策略。

赛题任务
此赛题的数据集由云测数据提供。比赛数据集中包含3000张真实场景下行车记录仪采集的图片,其中训练集包含2600张带有天气和时间类别标签的图片,测试集包含400张不带有标签的图片。参赛者需基于Oneflow框架在训练集上进行训练,对测试集中照片的天气和时间进行分类。
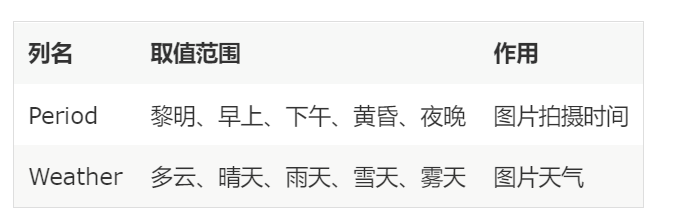
数据简介
本赛题的数据集包含2600张人工标注的天气和时间标签。
天气类别:多云、晴天、雨天、雪天和雾天5个类别
时间:黎明、早上、下午、黄昏、夜晚5个类别

下午 多云

早上 雨天
数据说明
数据集包含anno和image两个文件夹,anno文件夹中包含2600个标签json文件,image文件夹中包含3000张行车记录仪拍摄的JPEG编码照片。图片标签将字典以json格式序列化进行保存:
提交要求
参赛者使用Oneflow框架对数据集进行训练后对测试集图片进行推理后:
1.将测试集图片的目标检测和识别结果以与训练集格式保持一致的json文件序列化保存,并上传至参赛平台由参赛平台自动评测返回结果。
2.在提交时的备注附上自己的模型github仓库链接
提交示例
{ “annotations”: [ { “filename”: “test_images\00008.jpg”, “period”: “Morning”, “weather”: “Cloudy” }] }
解题思路
总体上看,该任务可以分为2个:一个是预测时间、一个是预测天气。
具体如下:
-
预测时间、天气数据标签列表生成
-
数据集划分
-
数据均衡(数据很不均衡)
-
分别预测
-
合并预测结果
数据集准备
数据下载
# 直接下载,速度超快
!wget https://awscdn.datafountain.cn/cometition_data2/Files/BDCI2021/555/train_dataset.zip
!wget https://awscdn.datafountain.cn/cometition_data2/Files/BDCI2021/555/test_dataset.zip
!wget https://awscdn.datafountain.cn/cometition_data2/Files/BDCI2021/555/submit_example.json
--2022-01-17 11:05:49-- https://awscdn.datafountain.cn/cometition_data2/Files/BDCI2021/555/train_dataset.zip
Resolving awscdn.datafountain.cn (awscdn.datafountain.cn)... 210.51.40.148, 210.51.40.156, 210.51.40.133, ...
Connecting to awscdn.datafountain.cn (awscdn.datafountain.cn)|210.51.40.148|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 419324853 (400M) [application/octet-stream]
Saving to: ‘train_dataset.zip’
train_dataset.zip 100%[===================>] 399.90M 102MB/s in 4.3s
2022-01-17 11:05:54 (94.0 MB/s) - ‘train_dataset.zip’ saved [419324853/419324853]
--2022-01-17 11:05:54-- https://awscdn.datafountain.cn/cometition_data2/Files/BDCI2021/555/test_dataset.zip
Resolving awscdn.datafountain.cn (awscdn.datafountain.cn)... 210.51.40.156, 210.51.40.150, 210.51.40.133, ...
Connecting to awscdn.datafountain.cn (awscdn.datafountain.cn)|210.51.40.156|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 62269247 (59M) [application/octet-stream]
Saving to: ‘test_dataset.zip’
test_dataset.zip 100%[===================>] 59.38M 65.4MB/s in 0.9s
2022-01-17 11:05:55 (65.4 MB/s) - ‘test_dataset.zip’ saved [62269247/62269247]
--2022-01-17 11:05:55-- https://awscdn.datafountain.cn/cometition_data2/Files/BDCI2021/555/submit_example.json
Resolving awscdn.datafountain.cn (awscdn.datafountain.cn)... 210.51.40.156, 210.51.40.148, 210.51.40.150, ...
Connecting to awscdn.datafountain.cn (awscdn.datafountain.cn)|210.51.40.156|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 593 [application/octet-stream]
Saving to: ‘submit_example.json’
submit_example.json 100%[===================>] 593 --.-KB/s in 0s
2022-01-17 11:05:56 (187 MB/s) - ‘submit_example.json’ saved [593/593]
数据解压缩
# 解压缩数据集
!unzip -qoa test_dataset.zip
!unzip -qoa train_dataset.zip
按时间制作标签
注意事项:虽然数据描述说时间** Period 为 黎明、早上、下午、黄昏、夜晚**,但是经过遍历发现只有4类。。。。。,故如下制作标签
# 标签修改
%cd ~
import json
import os
train = {}
with open('train.json', 'r') as f:
train = json.load(f)
period_list = {'Dawn': 0, 'Dusk': 1, 'Morning': 2, 'Afternoon': 3}
f_period=open('train_period.txt','w')
for item in train["annotations"]:
label = period_list[item['period']]
file_name=os.path.join(item['filename'].split('\\')[0], item['filename'].split('\\')[1])
f_period.write(file_name +' '+ str(label) +'\n')
f_period.close()
print("写入train_period.txt完成!!!")
/home/aistudio
写入train_period.txt完成!!!
数据集划分并数据均衡
# 数据分析
%cd ~
import pandas as pd
from matplotlib import pyplot as plt
%matplotlib inline
data=pd.read_csv('train_period.txt', header=None, sep=' ')
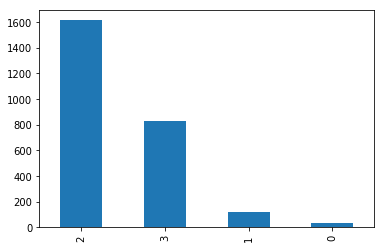
print(data[1].value_counts())
data[1].value_counts().plot(kind="bar")
/home/aistudio
2 1613
3 829
1 124
0 34
Name: 1, dtype: int64
<matplotlib.axes._subplots.AxesSubplot at 0x7feffe438b50>
# 训练集、测试集划分
import pandas as pd
import os
from sklearn.model_selection import train_test_split
def split_dataset(data_file):
# 展示不同的调用方式
data = pd.read_csv(data_file, header=None, sep=' ')
train_dataset, eval_dataset = train_test_split(data, test_size=0.2, random_state=42)
print(f'train dataset len: {train_dataset.size}')
print(f'eval dataset len: {eval_dataset.size}')
train_filename='train_' + data_file.split('.')[0]+'.txt'
eval_filename='eval_' + data_file.split('.')[0]+'.txt'
train_dataset.to_csv(train_filename, index=None, header=None, sep=' ')
eval_dataset.to_csv(eval_filename, index=None, header=None, sep=' ')
data_file='train_period.txt'
split_dataset(data_file)
train dataset len: 4160
eval dataset len: 1040
# pip更新或安装包后需要重启notebook
!pip install -U scikit-learn
# 数据均衡用
!pip install -U imblearn
# 数据均衡
import pandas as pd
from collections import Counter
from imblearn.over_sampling import SMOTE
import numpy as np
def upsampleing(filename):
print(50 * '*')
data = pd.read_csv(filename, header=None, sep=' ')
print(data[1].value_counts())
# 查看各个标签的样本量
print(Counter(data[1]))
print(50 * '*')
# 数据均衡
X = np.array(data[0].index.tolist()).reshape(-1, 1)
y = data[1]
ros = SMOTE(random_state=0)
X_resampled, y_resampled = ros.fit_resample(X, y)
print(Counter(y_resampled))
print(len(y_resampled))
print(50 * '*')
img_list=[]
for i in range(len(X_resampled)):
img_list.append(data.loc[X_resampled[i]][0].tolist()[0])
dict_weather={'0':img_list, '1':y_resampled.values}
newdata=pd.DataFrame(dict_weather)
print(len(newdata))
new_filename=filename.split('.')[0]+'_imblearn'+'.txt'
newdata.to_csv(new_filename, header=None, index=None, sep=' ')
filename='train_train_period.txt'
upsampleing(filename)
filename='eval_train_period.txt'
upsampleing(filename)
**************************************************
2 1304
3 653
1 95
0 28
Name: 1, dtype: int64
Counter({2: 1304, 3: 653, 1: 95, 0: 28})
**************************************************
Counter({2: 1304, 3: 1304, 1: 1304, 0: 1304})
5216
**************************************************
5216
**************************************************
2 309
3 176
1 29
0 6
Name: 1, dtype: int64
Counter({2: 309, 3: 176, 1: 29, 0: 6})
**************************************************
Counter({2: 309, 3: 309, 1: 309, 0: 309})
1236
**************************************************
1236
按天气分制作标签
import json
import os
train = {}
with open('train.json', 'r') as f:
train = json.load(f)
weather_list = {'Cloudy': 0, 'Rainy': 1, 'Sunny': 2}
f_weather=open('train_weather.txt','w')
for item in train["annotations"]:
label = weather_list[item['weather']]
file_name=os.path.join(item['filename'].split('\\')[0], item['filename'].split('\\')[1])
f_weather.write(file_name +' '+ str(label) +'\n')
f_weather.close()
print("写入train_weather.txt完成!!!")
写入train_weather.txt完成!!!
数据集划分并均衡
import pandas as pd
from matplotlib import pyplot as plt
data=pd.read_csv('train_weather.txt', header=None, sep=' ')
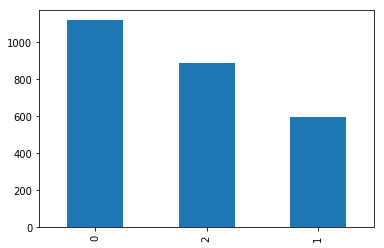
print(data[1].value_counts())
data[1].value_counts().plot(kind="bar")
0 1119
2 886
1 595
Name: 1, dtype: int64
<matplotlib.axes._subplots.AxesSubplot at 0x7feffe82d190>
# 训练集、测试集划分
import pandas as pd
import os
from sklearn.model_selection import train_test_split
def split_dataset(data_file):
# 展示不同的调用方式
data = pd.read_csv(data_file, header=None, sep=' ')
train_dataset, eval_dataset = train_test_split(data, test_size=0.2, random_state=42)
print(f'train dataset len: {train_dataset.size}')
print(f'eval dataset len: {eval_dataset.size}')
train_filename='train_' + data_file.split('.')[0]+'.txt'
eval_filename='eval_' + data_file.split('.')[0]+'.txt'
train_dataset.to_csv(train_filename, index=None, header=None, sep=' ')
eval_dataset.to_csv(eval_filename, index=None, header=None, sep=' ')
data_file='train_weather.txt'
split_dataset(data_file)
train dataset len: 4160
eval dataset len: 1040
# 数据均衡
import pandas as pd
from collections import Counter
from imblearn.over_sampling import SMOTE
import numpy as np
def upsampleing(filename):
print(50 * '*')
data = pd.read_csv(filename, header=None, sep=' ')
print(data[1].value_counts())
# 查看各个标签的样本量
print(Counter(data[1]))
print(50 * '*')
# 数据均衡
X = np.array(data[0].index.tolist()).reshape(-1, 1)
y = data[1]
ros = SMOTE(random_state=0)
X_resampled, y_resampled = ros.fit_resample(X, y)
print(Counter(y_resampled))
print(len(y_resampled))
print(50 * '*')
img_list=[]
for i in range(len(X_resampled)):
img_list.append(data.loc[X_resampled[i]][0].tolist()[0])
dict_weather={'0':img_list, '1':y_resampled.values}
newdata=pd.DataFrame(dict_weather)
print(len(newdata))
new_filename=filename.split('.')[0]+'_imblearn'+'.txt'
newdata.to_csv(new_filename, header=None, index=None, sep=' ')
filename='train_train_weather.txt'
upsampleing(filename)
filename='eval_train_weather.txt'
upsampleing(filename)
**************************************************
0 892
2 715
1 473
Name: 1, dtype: int64
Counter({0: 892, 2: 715, 1: 473})
**************************************************
Counter({0: 892, 2: 892, 1: 892})
2676
**************************************************
2676
**************************************************
0 227
2 171
1 122
Name: 1, dtype: int64
Counter({0: 227, 2: 171, 1: 122})
**************************************************
Counter({0: 227, 2: 227, 1: 227})
681
**************************************************
681
环境准备
飞桨图像识别套件PaddleClas是飞桨为工业界和学术界所准备的一个图像识别任务的工具集,助力使用者训练出更好的视觉模型和应用落地。此次计划使用端到端的PaddleClas图像分类套件来快速完成分类。此次使用PaddleClas框架完成比赛。
# git 下载PaddleClas
!git clone https://gitee.com/paddlepaddle/PaddleClas.git --depth=1
fatal: destination path 'PaddleClas' already exists and is not an empty directory.
# 安装
%cd ~/PaddleClas/
!pip install -U pip
!pip install -r requirements.txt
!pip install -e ./
%cd ~
模型训练 and 评估
时间训练
以PaddleClas/ppcls/configs/ImageNet/VisionTransformer/ViT_small_patch16_224.yaml 为基础进行修改
# global configs
Global:
checkpoints: null
pretrained_model: null
output_dir: ./output/
device: gpu
save_interval: 1
eval_during_train: True
eval_interval: 1
epochs: 120
print_batch_step: 10
use_visualdl: False
# used for static mode and model export
image_shape: [3, 224, 224]
save_inference_dir: ./inference
# model architecture
Arch:
name: ViT_small_patch16_224
class_num: 1000
# loss function config for traing/eval process
Loss:
Train:
- CELoss:
weight: 1.0
Eval:
- CELoss:
weight: 1.0
Optimizer:
name: Momentum
momentum: 0.9
lr:
name: Piecewise
learning_rate: 0.1
decay_epochs: [30, 60, 90]
values: [0.1, 0.01, 0.001, 0.0001]
regularizer:
name: 'L2'
coeff: 0.0001
# data loader for train and eval
DataLoader:
Train:
dataset:
name: ImageNetDataset
image_root: ./dataset/ILSVRC2012/
cls_label_path: ./dataset/ILSVRC2012/train_list.txt
transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- RandCropImage:
size: 224
- RandFlipImage:
flip_code: 1
- NormalizeImage:
scale: 1.0/255.0
mean: [0.5, 0.5, 0.5]
std: [0.5, 0.5, 0.5]
order: ''
sampler:
name: DistributedBatchSampler
batch_size: 64
drop_last: False
shuffle: True
loader:
num_workers: 4
use_shared_memory: True
Eval:
dataset:
name: ImageNetDataset
image_root: ./dataset/ILSVRC2012/
cls_label_path: ./dataset/ILSVRC2012/val_list.txt
transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 256
- CropImage:
size: 224
- NormalizeImage:
scale: 1.0/255.0
mean: [0.5, 0.5, 0.5]
std: [0.5, 0.5, 0.5]
order: ''
sampler:
name: DistributedBatchSampler
batch_size: 64
drop_last: False
shuffle: False
loader:
num_workers: 4
use_shared_memory: True
Infer:
infer_imgs: docs/images/whl/demo.jpg
batch_size: 10
transforms:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 256
- CropImage:
size: 224
- NormalizeImage:
scale: 1.0/255.0
mean: [0.5, 0.5, 0.5]
std: [0.5, 0.5, 0.5]
order: ''
- ToCHWImage:
PostProcess:
name: Topk
topk: 5
class_id_map_file: ppcls/utils/imagenet1k_label_list.txt
Metric:
Train:
- TopkAcc:
topk: [1, 5]
Eval:
- TopkAcc:
topk: [1, 5]
# 覆盖配置
%cd ~
!cp -f ~/ViT_small_patch16_224.yaml ~/ppcls/configs/ImageNet/VisionTransformer/ViT_small_patch16_224.yaml
/home/aistudio
# 开始训练
%cd ~/PaddleClas/
!python3 tools/train.py \
-c ./ppcls/configs/ImageNet/VisionTransformer/ViT_base_patch16_224.yaml \
-o Arch.pretrained=True \
-o Global.pretrained_model=./output/ViT_base_patch16_224/epoch_21 \
-o Global.device=gpu
/home/aistudio/PaddleClas
# 模型评估
%cd ~/PaddleClas/
!python tools/eval.py \
-c ./ppcls/configs/ImageNet/VisionTransformer/ViT_base_patch16_224.yaml \
-o Global.pretrained_model=./output/ViT_base_patch16_224/best_model
/home/aistudio/PaddleClas
[2022/01/18 00:16:10] root INFO:
===========================================================
== PaddleClas is powered by PaddlePaddle ! ==
===========================================================
== ==
== For more info please go to the following website. ==
== ==
== https://github.com/PaddlePaddle/PaddleClas ==
===========================================================
[2022/01/18 00:16:10] root INFO: Arch :
[2022/01/18 00:16:10] root INFO: class_num : 4
[2022/01/18 00:16:10] root INFO: name : ViT_base_patch16_224
[2022/01/18 00:16:10] root INFO: DataLoader :
[2022/01/18 00:16:10] root INFO: Eval :
[2022/01/18 00:16:10] root INFO: dataset :
[2022/01/18 00:16:10] root INFO: cls_label_path : /home/aistudio/eval_train_period_imblearn.txt
[2022/01/18 00:16:10] root INFO: image_root : /home/aistudio/
[2022/01/18 00:16:10] root INFO: name : ImageNetDataset
[2022/01/18 00:16:10] root INFO: transform_ops :
[2022/01/18 00:16:10] root INFO: DecodeImage :
[2022/01/18 00:16:10] root INFO: channel_first : False
[2022/01/18 00:16:10] root INFO: to_rgb : True
[2022/01/18 00:16:10] root INFO: ResizeImage :
[2022/01/18 00:16:10] root INFO: resize_short : 256
[2022/01/18 00:16:10] root INFO: CropImage :
[2022/01/18 00:16:10] root INFO: size : 224
[2022/01/18 00:16:10] root INFO: NormalizeImage :
[2022/01/18 00:16:10] root INFO: mean : [0.5, 0.5, 0.5]
[2022/01/18 00:16:10] root INFO: order :
[2022/01/18 00:16:10] root INFO: scale : 1.0/255.0
[2022/01/18 00:16:10] root INFO: std : [0.5, 0.5, 0.5]
[2022/01/18 00:16:10] root INFO: loader :
[2022/01/18 00:16:10] root INFO: num_workers : 4
[2022/01/18 00:16:10] root INFO: use_shared_memory : True
[2022/01/18 00:16:10] root INFO: sampler :
[2022/01/18 00:16:10] root INFO: batch_size : 128
[2022/01/18 00:16:10] root INFO: drop_last : False
[2022/01/18 00:16:10] root INFO: name : DistributedBatchSampler
[2022/01/18 00:16:10] root INFO: shuffle : False
[2022/01/18 00:16:10] root INFO: Train :
[2022/01/18 00:16:10] root INFO: dataset :
[2022/01/18 00:16:10] root INFO: cls_label_path : /home/aistudio/train_train_period_imblearn.txt
[2022/01/18 00:16:10] root INFO: image_root : /home/aistudio
[2022/01/18 00:16:10] root INFO: name : ImageNetDataset
[2022/01/18 00:16:10] root INFO: transform_ops :
[2022/01/18 00:16:10] root INFO: DecodeImage :
[2022/01/18 00:16:10] root INFO: channel_first : False
[2022/01/18 00:16:10] root INFO: to_rgb : True
[2022/01/18 00:16:10] root INFO: RandCropImage :
[2022/01/18 00:16:10] root INFO: size : 224
[2022/01/18 00:16:10] root INFO: RandFlipImage :
[2022/01/18 00:16:10] root INFO: flip_code : 1
[2022/01/18 00:16:10] root INFO: NormalizeImage :
[2022/01/18 00:16:10] root INFO: mean : [0.5, 0.5, 0.5]
[2022/01/18 00:16:10] root INFO: order :
[2022/01/18 00:16:10] root INFO: scale : 1.0/255.0
[2022/01/18 00:16:10] root INFO: std : [0.5, 0.5, 0.5]
[2022/01/18 00:16:10] root INFO: loader :
[2022/01/18 00:16:10] root INFO: num_workers : 4
[2022/01/18 00:16:10] root INFO: use_shared_memory : True
[2022/01/18 00:16:10] root INFO: sampler :
[2022/01/18 00:16:10] root INFO: batch_size : 160
[2022/01/18 00:16:10] root INFO: drop_last : False
[2022/01/18 00:16:10] root INFO: name : DistributedBatchSampler
[2022/01/18 00:16:10] root INFO: shuffle : True
[2022/01/18 00:16:10] root INFO: Global :
[2022/01/18 00:16:10] root INFO: checkpoints : None
[2022/01/18 00:16:10] root INFO: device : gpu
[2022/01/18 00:16:10] root INFO: epochs : 120
[2022/01/18 00:16:10] root INFO: eval_during_train : True
[2022/01/18 00:16:10] root INFO: eval_interval : 1
[2022/01/18 00:16:10] root INFO: image_shape : [3, 224, 224]
[2022/01/18 00:16:10] root INFO: output_dir : ./output/
[2022/01/18 00:16:10] root INFO: pretrained_model : ./output/ViT_base_patch16_224/best_model
[2022/01/18 00:16:10] root INFO: print_batch_step : 10
[2022/01/18 00:16:10] root INFO: save_inference_dir : ./inference
[2022/01/18 00:16:10] root INFO: save_interval : 1
[2022/01/18 00:16:10] root INFO: use_visualdl : False
[2022/01/18 00:16:10] root INFO: Infer :
[2022/01/18 00:16:10] root INFO: PostProcess :
[2022/01/18 00:16:10] root INFO: class_id_map_file : ppcls/utils/imagenet1k_label_list.txt
[2022/01/18 00:16:10] root INFO: name : Topk
[2022/01/18 00:16:10] root INFO: topk : 5
[2022/01/18 00:16:10] root INFO: batch_size : 10
[2022/01/18 00:16:10] root INFO: infer_imgs : docs/images/whl/demo.jpg
[2022/01/18 00:16:10] root INFO: transforms :
[2022/01/18 00:16:10] root INFO: DecodeImage :
[2022/01/18 00:16:10] root INFO: channel_first : False
[2022/01/18 00:16:10] root INFO: to_rgb : True
[2022/01/18 00:16:10] root INFO: ResizeImage :
[2022/01/18 00:16:10] root INFO: resize_short : 256
[2022/01/18 00:16:10] root INFO: CropImage :
[2022/01/18 00:16:10] root INFO: size : 224
[2022/01/18 00:16:10] root INFO: NormalizeImage :
[2022/01/18 00:16:10] root INFO: mean : [0.5, 0.5, 0.5]
[2022/01/18 00:16:10] root INFO: order :
[2022/01/18 00:16:10] root INFO: scale : 1.0/255.0
[2022/01/18 00:16:10] root INFO: std : [0.5, 0.5, 0.5]
[2022/01/18 00:16:10] root INFO: ToCHWImage : None
[2022/01/18 00:16:10] root INFO: Loss :
[2022/01/18 00:16:10] root INFO: Eval :
[2022/01/18 00:16:10] root INFO: CELoss :
[2022/01/18 00:16:10] root INFO: weight : 1.0
[2022/01/18 00:16:10] root INFO: Train :
[2022/01/18 00:16:10] root INFO: CELoss :
[2022/01/18 00:16:10] root INFO: weight : 1.0
[2022/01/18 00:16:10] root INFO: Metric :
[2022/01/18 00:16:10] root INFO: Eval :
[2022/01/18 00:16:10] root INFO: TopkAcc :
[2022/01/18 00:16:10] root INFO: topk : [1, 2]
[2022/01/18 00:16:10] root INFO: Train :
[2022/01/18 00:16:10] root INFO: TopkAcc :
[2022/01/18 00:16:10] root INFO: topk : [1, 2]
[2022/01/18 00:16:10] root INFO: Optimizer :
[2022/01/18 00:16:10] root INFO: lr :
[2022/01/18 00:16:10] root INFO: decay_epochs : [10, 22, 30]
[2022/01/18 00:16:10] root INFO: learning_rate : 0.01
[2022/01/18 00:16:10] root INFO: name : Piecewise
[2022/01/18 00:16:10] root INFO: values : [0.01, 0.001, 0.0001, 1e-05]
[2022/01/18 00:16:10] root INFO: momentum : 0.9
[2022/01/18 00:16:10] root INFO: name : Momentum
[2022/01/18 00:16:10] root INFO: regularizer :
[2022/01/18 00:16:10] root INFO: coeff : 0.0001
[2022/01/18 00:16:10] root INFO: name : L2
[2022/01/18 00:16:10] root INFO: train with paddle 2.2.1 and device CUDAPlace(0)
W0118 00:16:10.219051 1924 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W0118 00:16:10.224006 1924 device_context.cc:465] device: 0, cuDNN Version: 7.6.
[2022/01/18 00:16:21] root INFO: [Eval][Epoch 0][Iter: 0/10]CELoss: 0.68425, loss: 0.68425, top1: 0.79688, top2: 0.92969, batch_cost: 6.03284s, reader_cost: 5.55918, ips: 21.21719 images/sec
[2022/01/18 00:16:30] root INFO: [Eval][Epoch 0][Avg]CELoss: 1.24542, loss: 1.24542, top1: 0.47006, top2: 0.73463
天气训练
配置文件为:
** PaddleClas/ppcls/configs/ImageNet/VisionTransformer/ViT_base_patch16_224_weather.yaml**
# global configs
Global:
checkpoints: null
pretrained_model: null
output_dir: ./output_weather/
device: gpu
save_interval: 1
eval_during_train: True
eval_interval: 1
epochs: 120
print_batch_step: 10
use_visualdl: False
# used for static mode and model export
image_shape: [3, 224, 224]
save_inference_dir: ./inference_weather
# model architecture
Arch:
name: ViT_base_patch16_224
class_num: 3
# loss function config for traing/eval process
Loss:
Train:
- CELoss:
weight: 1.0
Eval:
- CELoss:
weight: 1.0
Optimizer:
name: Momentum
momentum: 0.9
lr:
name: Piecewise
learning_rate: 0.01
decay_epochs: [10, 22, 30]
values: [0.01, 0.001, 0.0001, 0.00001]
regularizer:
name: 'L2'
coeff: 0.0001
# data loader for train and eval
DataLoader:
Train:
dataset:
name: ImageNetDataset
image_root: /home/aistudio
cls_label_path: /home/aistudio/train_train_weather_imblearn.txt
transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- RandCropImage:
size: 224
- RandFlipImage:
flip_code: 1
- NormalizeImage:
scale: 1.0/255.0
mean: [0.5, 0.5, 0.5]
std: [0.5, 0.5, 0.5]
order: ''
sampler:
name: DistributedBatchSampler
batch_size: 160
drop_last: False
shuffle: True
loader:
num_workers: 4
use_shared_memory: True
Eval:
dataset:
name: ImageNetDataset
image_root: /home/aistudio/
cls_label_path: /home/aistudio/eval_train_weather_imblearn.txt
transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 256
- CropImage:
size: 224
- NormalizeImage:
scale: 1.0/255.0
mean: [0.5, 0.5, 0.5]
std: [0.5, 0.5, 0.5]
order: ''
sampler:
name: DistributedBatchSampler
batch_size: 128
drop_last: False
shuffle: False
loader:
num_workers: 4
use_shared_memory: True
Infer:
infer_imgs: docs/images/whl/demo.jpg
batch_size: 10
transforms:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 256
- CropImage:
size: 224
- NormalizeImage:
scale: 1.0/255.0
mean: [0.5, 0.5, 0.5]
std: [0.5, 0.5, 0.5]
order: ''
- ToCHWImage:
PostProcess:
name: Topk
topk: 5
class_id_map_file: ppcls/utils/imagenet1k_label_list.txt
Metric:
Train:
- TopkAcc:
topk: [1, 2]
Eval:
- TopkAcc:
topk: [1, 2]
# 覆盖配置
%cd ~
!cp -f ~/ViT_small_patch16_224_weather.yaml ~/ppcls/configs/ImageNet/VisionTransformer/ViT_small_patch16_224_weather.yaml
/home/aistudio
cp: cannot stat 'PaddleClas/ppcls/configs/ImageNet/VisionTransformer/ViT_small_patch16_224_weather.yaml': No such file or directory
# 模型训练
%cd ~/PaddleClas/
!python3 tools/train.py \
-c ./ppcls/configs/ImageNet/VisionTransformer/ViT_base_patch16_224_weather.yaml \
-o Arch.pretrained=True \
-o Global.device=gpu
# 模型评估
%cd ~/PaddleClas/
!python tools/eval.py \
-c ./ppcls/configs/ImageNet/VisionTransformer/ViT_base_patch16_224_weather.yaml \
-o Global.pretrained_model=./output_weather/ViT_base_patch16_224/best_model
/home/aistudio/PaddleClas
[2022/01/18 00:17:24] root INFO:
===========================================================
== PaddleClas is powered by PaddlePaddle ! ==
===========================================================
== ==
== For more info please go to the following website. ==
== ==
== https://github.com/PaddlePaddle/PaddleClas ==
===========================================================
[2022/01/18 00:17:24] root INFO: Arch :
[2022/01/18 00:17:24] root INFO: class_num : 3
[2022/01/18 00:17:24] root INFO: name : ViT_base_patch16_224
[2022/01/18 00:17:24] root INFO: DataLoader :
[2022/01/18 00:17:24] root INFO: Eval :
[2022/01/18 00:17:24] root INFO: dataset :
[2022/01/18 00:17:24] root INFO: cls_label_path : /home/aistudio/eval_train_weather_imblearn.txt
[2022/01/18 00:17:24] root INFO: image_root : /home/aistudio/
[2022/01/18 00:17:24] root INFO: name : ImageNetDataset
[2022/01/18 00:17:24] root INFO: transform_ops :
[2022/01/18 00:17:24] root INFO: DecodeImage :
[2022/01/18 00:17:24] root INFO: channel_first : False
[2022/01/18 00:17:24] root INFO: to_rgb : True
[2022/01/18 00:17:24] root INFO: ResizeImage :
[2022/01/18 00:17:24] root INFO: resize_short : 256
[2022/01/18 00:17:24] root INFO: CropImage :
[2022/01/18 00:17:24] root INFO: size : 224
[2022/01/18 00:17:24] root INFO: NormalizeImage :
[2022/01/18 00:17:24] root INFO: mean : [0.5, 0.5, 0.5]
[2022/01/18 00:17:24] root INFO: order :
[2022/01/18 00:17:24] root INFO: scale : 1.0/255.0
[2022/01/18 00:17:24] root INFO: std : [0.5, 0.5, 0.5]
[2022/01/18 00:17:24] root INFO: loader :
[2022/01/18 00:17:24] root INFO: num_workers : 4
[2022/01/18 00:17:24] root INFO: use_shared_memory : True
[2022/01/18 00:17:24] root INFO: sampler :
[2022/01/18 00:17:24] root INFO: batch_size : 128
[2022/01/18 00:17:24] root INFO: drop_last : False
[2022/01/18 00:17:24] root INFO: name : DistributedBatchSampler
[2022/01/18 00:17:24] root INFO: shuffle : False
[2022/01/18 00:17:24] root INFO: Train :
[2022/01/18 00:17:24] root INFO: dataset :
[2022/01/18 00:17:24] root INFO: cls_label_path : /home/aistudio/train_train_weather_imblearn.txt
[2022/01/18 00:17:24] root INFO: image_root : /home/aistudio
[2022/01/18 00:17:24] root INFO: name : ImageNetDataset
[2022/01/18 00:17:24] root INFO: transform_ops :
[2022/01/18 00:17:24] root INFO: DecodeImage :
[2022/01/18 00:17:24] root INFO: channel_first : False
[2022/01/18 00:17:24] root INFO: to_rgb : True
[2022/01/18 00:17:24] root INFO: RandCropImage :
[2022/01/18 00:17:24] root INFO: size : 224
[2022/01/18 00:17:24] root INFO: RandFlipImage :
[2022/01/18 00:17:24] root INFO: flip_code : 1
[2022/01/18 00:17:24] root INFO: NormalizeImage :
[2022/01/18 00:17:24] root INFO: mean : [0.5, 0.5, 0.5]
[2022/01/18 00:17:24] root INFO: order :
[2022/01/18 00:17:24] root INFO: scale : 1.0/255.0
[2022/01/18 00:17:24] root INFO: std : [0.5, 0.5, 0.5]
[2022/01/18 00:17:24] root INFO: loader :
[2022/01/18 00:17:24] root INFO: num_workers : 4
[2022/01/18 00:17:24] root INFO: use_shared_memory : True
[2022/01/18 00:17:24] root INFO: sampler :
[2022/01/18 00:17:24] root INFO: batch_size : 160
[2022/01/18 00:17:24] root INFO: drop_last : False
[2022/01/18 00:17:24] root INFO: name : DistributedBatchSampler
[2022/01/18 00:17:24] root INFO: shuffle : True
[2022/01/18 00:17:24] root INFO: Global :
[2022/01/18 00:17:24] root INFO: checkpoints : None
[2022/01/18 00:17:24] root INFO: device : gpu
[2022/01/18 00:17:24] root INFO: epochs : 120
[2022/01/18 00:17:24] root INFO: eval_during_train : True
[2022/01/18 00:17:24] root INFO: eval_interval : 1
[2022/01/18 00:17:24] root INFO: image_shape : [3, 224, 224]
[2022/01/18 00:17:24] root INFO: output_dir : ./output_weather/
[2022/01/18 00:17:24] root INFO: pretrained_model : ./output_weather/ViT_base_patch16_224/best_model
[2022/01/18 00:17:24] root INFO: print_batch_step : 10
[2022/01/18 00:17:24] root INFO: save_inference_dir : ./inference
[2022/01/18 00:17:24] root INFO: save_interval : 1
[2022/01/18 00:17:24] root INFO: use_visualdl : False
[2022/01/18 00:17:24] root INFO: Infer :
[2022/01/18 00:17:24] root INFO: PostProcess :
[2022/01/18 00:17:24] root INFO: class_id_map_file : ppcls/utils/imagenet1k_label_list.txt
[2022/01/18 00:17:24] root INFO: name : Topk
[2022/01/18 00:17:24] root INFO: topk : 5
[2022/01/18 00:17:24] root INFO: batch_size : 10
[2022/01/18 00:17:24] root INFO: infer_imgs : docs/images/whl/demo.jpg
[2022/01/18 00:17:24] root INFO: transforms :
[2022/01/18 00:17:24] root INFO: DecodeImage :
[2022/01/18 00:17:24] root INFO: channel_first : False
[2022/01/18 00:17:24] root INFO: to_rgb : True
[2022/01/18 00:17:24] root INFO: ResizeImage :
[2022/01/18 00:17:24] root INFO: resize_short : 256
[2022/01/18 00:17:24] root INFO: CropImage :
[2022/01/18 00:17:24] root INFO: size : 224
[2022/01/18 00:17:24] root INFO: NormalizeImage :
[2022/01/18 00:17:24] root INFO: mean : [0.5, 0.5, 0.5]
[2022/01/18 00:17:24] root INFO: order :
[2022/01/18 00:17:24] root INFO: scale : 1.0/255.0
[2022/01/18 00:17:24] root INFO: std : [0.5, 0.5, 0.5]
[2022/01/18 00:17:24] root INFO: ToCHWImage : None
[2022/01/18 00:17:24] root INFO: Loss :
[2022/01/18 00:17:24] root INFO: Eval :
[2022/01/18 00:17:24] root INFO: CELoss :
[2022/01/18 00:17:24] root INFO: weight : 1.0
[2022/01/18 00:17:24] root INFO: Train :
[2022/01/18 00:17:24] root INFO: CELoss :
[2022/01/18 00:17:24] root INFO: weight : 1.0
[2022/01/18 00:17:24] root INFO: Metric :
[2022/01/18 00:17:24] root INFO: Eval :
[2022/01/18 00:17:24] root INFO: TopkAcc :
[2022/01/18 00:17:24] root INFO: topk : [1, 2]
[2022/01/18 00:17:24] root INFO: Train :
[2022/01/18 00:17:24] root INFO: TopkAcc :
[2022/01/18 00:17:24] root INFO: topk : [1, 2]
[2022/01/18 00:17:24] root INFO: Optimizer :
[2022/01/18 00:17:24] root INFO: lr :
[2022/01/18 00:17:24] root INFO: decay_epochs : [10, 22, 30]
[2022/01/18 00:17:24] root INFO: learning_rate : 0.01
[2022/01/18 00:17:24] root INFO: name : Piecewise
[2022/01/18 00:17:24] root INFO: values : [0.01, 0.001, 0.0001, 1e-05]
[2022/01/18 00:17:24] root INFO: momentum : 0.9
[2022/01/18 00:17:24] root INFO: name : Momentum
[2022/01/18 00:17:24] root INFO: regularizer :
[2022/01/18 00:17:24] root INFO: coeff : 0.0001
[2022/01/18 00:17:24] root INFO: name : L2
[2022/01/18 00:17:24] root INFO: train with paddle 2.2.1 and device CUDAPlace(0)
W0118 00:17:24.490124 2035 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W0118 00:17:24.495002 2035 device_context.cc:465] device: 0, cuDNN Version: 7.6.
[2022/01/18 00:17:35] root INFO: [Eval][Epoch 0][Iter: 0/6]CELoss: 0.17755, loss: 0.17755, top1: 0.97656, top2: 1.00000, batch_cost: 5.94345s, reader_cost: 5.49357, ips: 21.53630 images/sec
[2022/01/18 00:17:39] root INFO: [Eval][Epoch 0][Avg]CELoss: 0.54770, loss: 0.54770, top1: 0.83700, top2: 0.95154
预测
时间模型导出
# 模型导出
%cd ~/PaddleClas/
!python tools/export_model.py -c ./ppcls/configs/ImageNet/VisionTransformer/ViT_base_patch16_224.yaml -o Global.pretrained_model=./output/ViT_base_patch16_224/best_model
/home/aistudio/PaddleClas
[2022/01/18 00:34:27] root INFO:
===========================================================
== PaddleClas is powered by PaddlePaddle ! ==
===========================================================
== ==
== For more info please go to the following website. ==
== ==
== https://github.com/PaddlePaddle/PaddleClas ==
===========================================================
[2022/01/18 00:34:27] root INFO: Arch :
[2022/01/18 00:34:27] root INFO: class_num : 4
[2022/01/18 00:34:27] root INFO: name : ViT_base_patch16_224
[2022/01/18 00:34:27] root INFO: DataLoader :
[2022/01/18 00:34:27] root INFO: Eval :
[2022/01/18 00:34:27] root INFO: dataset :
[2022/01/18 00:34:27] root INFO: cls_label_path : /home/aistudio/eval_train_period_imblearn.txt
[2022/01/18 00:34:27] root INFO: image_root : /home/aistudio/
[2022/01/18 00:34:27] root INFO: name : ImageNetDataset
[2022/01/18 00:34:27] root INFO: transform_ops :
[2022/01/18 00:34:27] root INFO: DecodeImage :
[2022/01/18 00:34:27] root INFO: channel_first : False
[2022/01/18 00:34:27] root INFO: to_rgb : True
[2022/01/18 00:34:27] root INFO: ResizeImage :
[2022/01/18 00:34:27] root INFO: resize_short : 256
[2022/01/18 00:34:27] root INFO: CropImage :
[2022/01/18 00:34:27] root INFO: size : 224
[2022/01/18 00:34:27] root INFO: NormalizeImage :
[2022/01/18 00:34:27] root INFO: mean : [0.5, 0.5, 0.5]
[2022/01/18 00:34:27] root INFO: order :
[2022/01/18 00:34:27] root INFO: scale : 1.0/255.0
[2022/01/18 00:34:27] root INFO: std : [0.5, 0.5, 0.5]
[2022/01/18 00:34:27] root INFO: loader :
[2022/01/18 00:34:27] root INFO: num_workers : 4
[2022/01/18 00:34:27] root INFO: use_shared_memory : True
[2022/01/18 00:34:27] root INFO: sampler :
[2022/01/18 00:34:27] root INFO: batch_size : 128
[2022/01/18 00:34:27] root INFO: drop_last : False
[2022/01/18 00:34:27] root INFO: name : DistributedBatchSampler
[2022/01/18 00:34:27] root INFO: shuffle : False
[2022/01/18 00:34:27] root INFO: Train :
[2022/01/18 00:34:27] root INFO: dataset :
[2022/01/18 00:34:27] root INFO: cls_label_path : /home/aistudio/train_train_period_imblearn.txt
[2022/01/18 00:34:27] root INFO: image_root : /home/aistudio
[2022/01/18 00:34:27] root INFO: name : ImageNetDataset
[2022/01/18 00:34:27] root INFO: transform_ops :
[2022/01/18 00:34:27] root INFO: DecodeImage :
[2022/01/18 00:34:27] root INFO: channel_first : False
[2022/01/18 00:34:27] root INFO: to_rgb : True
[2022/01/18 00:34:27] root INFO: RandCropImage :
[2022/01/18 00:34:27] root INFO: size : 224
[2022/01/18 00:34:27] root INFO: RandFlipImage :
[2022/01/18 00:34:27] root INFO: flip_code : 1
[2022/01/18 00:34:27] root INFO: NormalizeImage :
[2022/01/18 00:34:27] root INFO: mean : [0.5, 0.5, 0.5]
[2022/01/18 00:34:27] root INFO: order :
[2022/01/18 00:34:27] root INFO: scale : 1.0/255.0
[2022/01/18 00:34:27] root INFO: std : [0.5, 0.5, 0.5]
[2022/01/18 00:34:27] root INFO: loader :
[2022/01/18 00:34:27] root INFO: num_workers : 4
[2022/01/18 00:34:27] root INFO: use_shared_memory : True
[2022/01/18 00:34:27] root INFO: sampler :
[2022/01/18 00:34:27] root INFO: batch_size : 160
[2022/01/18 00:34:27] root INFO: drop_last : False
[2022/01/18 00:34:27] root INFO: name : DistributedBatchSampler
[2022/01/18 00:34:27] root INFO: shuffle : True
[2022/01/18 00:34:27] root INFO: Global :
[2022/01/18 00:34:27] root INFO: checkpoints : None
[2022/01/18 00:34:27] root INFO: device : gpu
[2022/01/18 00:34:27] root INFO: epochs : 120
[2022/01/18 00:34:27] root INFO: eval_during_train : True
[2022/01/18 00:34:27] root INFO: eval_interval : 1
[2022/01/18 00:34:27] root INFO: image_shape : [3, 224, 224]
[2022/01/18 00:34:27] root INFO: output_dir : ./output/
[2022/01/18 00:34:27] root INFO: pretrained_model : ./output/ViT_base_patch16_224/best_model
[2022/01/18 00:34:27] root INFO: print_batch_step : 10
[2022/01/18 00:34:27] root INFO: save_inference_dir : ./inference
[2022/01/18 00:34:27] root INFO: save_interval : 1
[2022/01/18 00:34:27] root INFO: use_visualdl : False
[2022/01/18 00:34:27] root INFO: Infer :
[2022/01/18 00:34:27] root INFO: PostProcess :
[2022/01/18 00:34:27] root INFO: class_id_map_file : ppcls/utils/imagenet1k_label_list.txt
[2022/01/18 00:34:27] root INFO: name : Topk
[2022/01/18 00:34:27] root INFO: topk : 5
[2022/01/18 00:34:27] root INFO: batch_size : 10
[2022/01/18 00:34:27] root INFO: infer_imgs : docs/images/whl/demo.jpg
[2022/01/18 00:34:27] root INFO: transforms :
[2022/01/18 00:34:27] root INFO: DecodeImage :
[2022/01/18 00:34:27] root INFO: channel_first : False
[2022/01/18 00:34:27] root INFO: to_rgb : True
[2022/01/18 00:34:27] root INFO: ResizeImage :
[2022/01/18 00:34:27] root INFO: resize_short : 256
[2022/01/18 00:34:27] root INFO: CropImage :
[2022/01/18 00:34:27] root INFO: size : 224
[2022/01/18 00:34:27] root INFO: NormalizeImage :
[2022/01/18 00:34:27] root INFO: mean : [0.5, 0.5, 0.5]
[2022/01/18 00:34:27] root INFO: order :
[2022/01/18 00:34:27] root INFO: scale : 1.0/255.0
[2022/01/18 00:34:27] root INFO: std : [0.5, 0.5, 0.5]
[2022/01/18 00:34:27] root INFO: ToCHWImage : None
[2022/01/18 00:34:27] root INFO: Loss :
[2022/01/18 00:34:27] root INFO: Eval :
[2022/01/18 00:34:27] root INFO: CELoss :
[2022/01/18 00:34:27] root INFO: weight : 1.0
[2022/01/18 00:34:27] root INFO: Train :
[2022/01/18 00:34:27] root INFO: CELoss :
[2022/01/18 00:34:27] root INFO: weight : 1.0
[2022/01/18 00:34:27] root INFO: Metric :
[2022/01/18 00:34:27] root INFO: Eval :
[2022/01/18 00:34:27] root INFO: TopkAcc :
[2022/01/18 00:34:27] root INFO: topk : [1, 2]
[2022/01/18 00:34:27] root INFO: Train :
[2022/01/18 00:34:27] root INFO: TopkAcc :
[2022/01/18 00:34:27] root INFO: topk : [1, 2]
[2022/01/18 00:34:27] root INFO: Optimizer :
[2022/01/18 00:34:27] root INFO: lr :
[2022/01/18 00:34:27] root INFO: decay_epochs : [10, 22, 30]
[2022/01/18 00:34:27] root INFO: learning_rate : 0.01
[2022/01/18 00:34:27] root INFO: name : Piecewise
[2022/01/18 00:34:27] root INFO: values : [0.01, 0.001, 0.0001, 1e-05]
[2022/01/18 00:34:27] root INFO: momentum : 0.9
[2022/01/18 00:34:27] root INFO: name : Momentum
[2022/01/18 00:34:27] root INFO: regularizer :
[2022/01/18 00:34:27] root INFO: coeff : 0.0001
[2022/01/18 00:34:27] root INFO: name : L2
[2022/01/18 00:34:27] root INFO: train with paddle 2.2.1 and device CUDAPlace(0)
W0118 00:34:27.483398 3428 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W0118 00:34:27.488457 3428 device_context.cc:465] device: 0, cuDNN Version: 7.6.
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
return (isinstance(seq, collections.Sequence) and
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmpg1ueymey.py:8
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmpg1ueymey.py:11
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmp64fnbu8d.py:8
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmp64fnbu8d.py:11
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmp_h9tn_a7.py:8
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmp_h9tn_a7.py:11
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmpjl9_2_tk.py:8
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmpjl9_2_tk.py:11
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmpql2k50z9.py:8
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmpql2k50z9.py:11
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmpknifbg79.py:8
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmpknifbg79.py:11
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmpiv1rr45m.py:8
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmpiv1rr45m.py:11
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmpa99vj9b7.py:8
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmpa99vj9b7.py:11
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmp5tt116i3.py:8
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmp5tt116i3.py:11
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmpo6kgrf5v.py:8
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmpo6kgrf5v.py:11
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmp919bum5s.py:8
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmp919bum5s.py:11
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmpbiilsbhv.py:8
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:341: UserWarning: /tmp/tmpbiilsbhv.py:11
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
开始预测
编辑 PaddleClas/deploy/python/predict_cls.py,按提交格式输出预测结果到文件。
def main(config):
cls_predictor = ClsPredictor(config)
image_list = get_image_list(config["Global"]["infer_imgs"])
batch_imgs = []
batch_names = []
cnt = 0
# 保存到文件
f=open('/home/aistudio/result.txt', 'w')
for idx, img_path in enumerate(image_list):
img = cv2.imread(img_path)
if img is None:
logger.warning(
"Image file failed to read and has been skipped. The path: {}".
format(img_path))
else:
img = img[:, :, ::-1]
batch_imgs.append(img)
img_name = os.path.basename(img_path)
batch_names.append(img_name)
cnt += 1
if cnt % config["Global"]["batch_size"] == 0 or (idx + 1
) == len(image_list):
if len(batch_imgs) == 0:
continue
batch_results = cls_predictor.predict(batch_imgs)
for number, result_dict in enumerate(batch_results):
filename = batch_names[number]
clas_ids = result_dict["class_ids"]
scores_str = "[{}]".format(", ".join("{:.2f}".format(
r) for r in result_dict["scores"]))
label_names = result_dict["label_names"]
f.write("{} {}\n".format(filename, clas_ids[0]))
print("{}:\tclass id(s): {}, score(s): {}, label_name(s): {}".
format(filename, clas_ids, scores_str, label_names))
batch_imgs = []
batch_names = []
if cls_predictor.benchmark:
cls_predictor.auto_logger.report()
return
# 覆盖预测文件
!cp -f ~/predict_cls.py ~/deploy/python/predict_cls.py
# 开始预测
%cd /home/aistudio/PaddleClas/deploy
!python3 python/predict_cls.py -c configs/inference_cls.yaml -o Global.infer_imgs=/home/aistudio/test_images -o Global.inference_model_dir=../inference/ -o PostProcess.Topk.class_id_map_file=None
%cd ~
!mv result.txt result_period.txt
/home/aistudio
mv: cannot stat 'result.txt': No such file or directory
天气模型导出
# 模型导出
%cd ~/PaddleClas/
!python tools/export_model.py -c ./ppcls/configs/ImageNet/VisionTransformer/ViT_base_patch16_224_weather.yaml -o Global.pretrained_model=./output_weather/ViT_base_patch16_224/best_model
天气预测
# 开始预测
%cd /home/aistudio/PaddleClas/deploy
!python3 python/predict_cls.py -c configs/inference_cls.yaml -o Global.infer_imgs=/home/aistudio/test_images -o Global.inference_model_dir=../inference_weather/ -o PostProcess.Topk.class_id_map_file=None
%cd ~
!mv result.txt result_weather.txt
/home/aistudio
合并并提交
预测结果合并
period_list = { 0:'Dawn', 1:'Dusk', 2:'Morning', 3:'Afternoon'}
weather_list = {0:'Cloudy', 1:'Rainy', 2:'Sunny'}
import pandas as pd
import json
data_period= pd.read_csv('result_period.txt', header=None, sep=' ')
data_weather= pd.read_csv('result_weather.txt', header=None, sep=' ')
annotations_list=[]
for i in range(len(data_period)):
temp={}
temp["filename"]="test_images"+"\\"+data_weather.loc[i][0]
temp["period"]=period_list[data_period.loc[i][1]]
temp["weather"]=weather_list[data_weather.loc[i][1]]
annotations_list.append(temp)
myresult={}
myresult["annotations"]=annotations_list
with open('result.json','w') as f:
json.dump(myresult, f)
print("结果生成完毕")
结果生成完毕
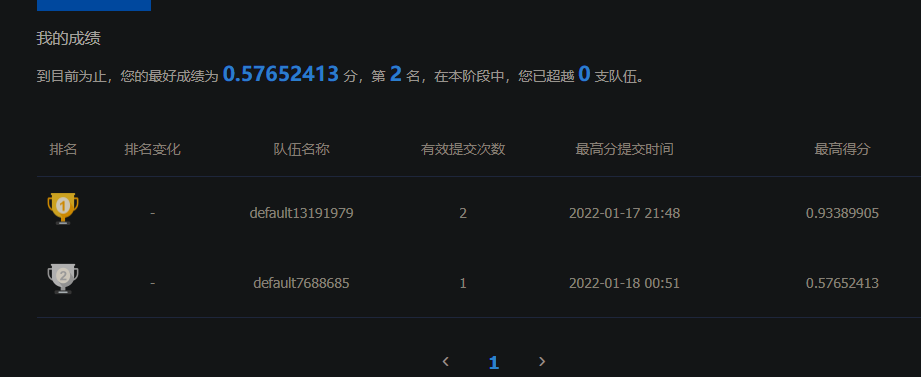
提交并获取成绩 下载result.json并提交,即可获得成绩
其他注意事项
生成版本时提示存在无效软链接无法保存 ,可以在终端 PaddleClas 下运行下列代码清理即可。
for a in `find . -type l`
do
stat -L $a >/dev/null 2>/dev/null
if [ $? -gt 0 ]
then
rm $a
fi
done
关注公众号【学姐带你玩AI】
回复“天气”领取完整代码















 3748
3748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









