










来源:投稿 作者:橡皮
编辑:学姐

[Paper]:https://arxiv.org/pdf/2303.00601.pdf
[Code]:https://github.com/nomewang/M3DM
0.背景:
工业异常检测旨在发现产品的异常区域,在工业质量检测中发挥着重要作用。在工业场景中,很容易获得大量的正常示例,但缺陷示例很少。
大多数现有的工业异常检测方法都是基于2D图像的。然而,在工业产品的质量检查中,人类检查员利用3D形状和颜色特征来确定它是否是缺陷产品,其中3D形状信息对于判断是重要和必要的。
无监督异常检测的核心思想是找出异常和正态表示之间的区别。目前2D工业异常检测方法可分为两类:
(1)基于重构的方法。图像重建任务被广泛用于异常检测方法中,以学习正常表示。基于重建的方法对于单模态输入(2D图像或3D点云)很容易实现。但对于多模态输入,很难找到重建目标。
(2)基于预训练特征提取器的方法。利用特征提取器的直观方法是将提取的特征映射到正态分布,并将分布外的特征作为异常。
1.主要贡献:
提出了M3DM,这是一种新的具有混合特征融合的多模态工业异常检测方法,它优于MVTec-3D AD上最先进的检测和分割精度。
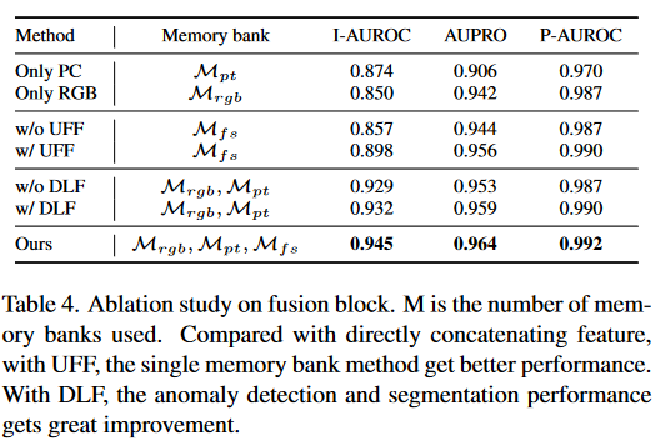
提出了具有逐片对比损失的无监督特征融合(UFF),以鼓励多模态特征之间的交互。
设计了决策层融合(DLF),利用多个内存库进行稳健决策。
探索了 Point Transformer 在多模态异常检测中的可行性,并提出了点特征对齐(PFA)操作,将Point Transformer 特征对齐到2D平面,以实现高性能的3D异常检测。
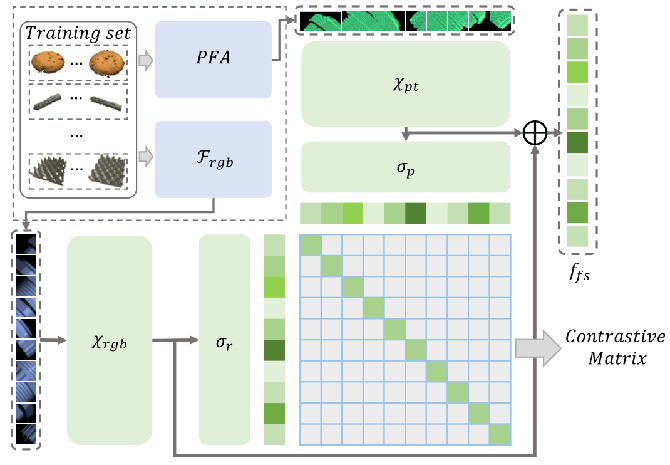
2.网络介绍: M3DM
Multi-3D-Memory(M3DM)的流程包含三个重要部分:

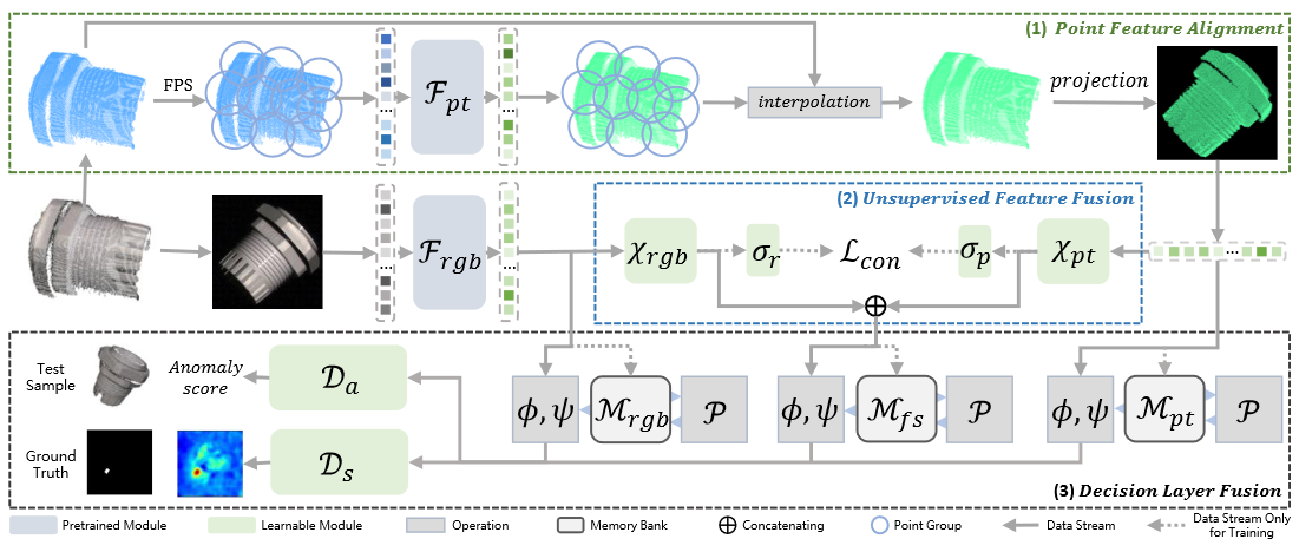
3.1方法细节:原理概览
我们的Multi-3D-Memory(M3DM)方法以3D点云和RGB图像为输入,进行3D异常检测和分割。我们提出了一种混合融合方案,以促进跨域信息交互,同时保持每个域的原始信息。使用两个预训练的特征提取器,用于RGB的 DINO 和用于点云的 PointMAE ,分别提取颜色和3D表示。
M3DM由三个重要部分组成:
(1)点特征对齐(第3.2节中的PFA):为了解决颜色特征和 3D 特征的位置信息不匹配问题,我们提出了点特征对齐,将3D特征与2D空间对齐,这有助于简化多模态交互,提高检测性能。
(2) 无监督特征融合(第3.3节中的UFF):由于多模态特征之间的交互可以生成有助于异常检测的新表征,我们提出了一个无监督特征聚变模块,以帮助统一多模态特征的分布,并学习它们之间的内在联系。
(3) 决策层融合(第3.4节中的DLF):尽管UFF有助于提高检测性能,但我们发现信息丢失是不可避免的,并建议决策层融合利用多个内存库进行最终决策。
3.2方法细节:Point Feature Alignment 点特征对齐
点特征提取。我们使用 Point Transformer ()来提取点云特征。输入点云 p 是具有 N 个点的点位置序列。在最远点采样(FPS)之后,点云被分为 M 组,每组有 S 个点。然后,将每组中的点编码为特征向量,并将 M 个向量输入到 Point Transformer 中。其输出 g 是 M 个点特征,然后将其组织为点特征组:每组都有一个单点特征,可以将其视为中心点的特征。
点特征插值。由于在最远点采样(FPS)之后,点中心点在空间中分布不均匀,这导致点特征的密度不平衡。我们建议将特征插值回原始点云。给定与 M 个群中心点 相关的 M 个点特征
,我们使用反距离权重将特征插值到输入点云中的每个点
(j∈{1,2,…,N})。该过程可以描述为:
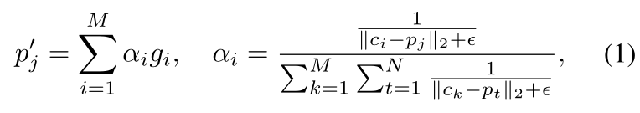

3.3方法细节:Unsupervised Feature Fusion 无监督特征融合
多模态特征之间的交互可以创建有助于工业异常检测的新信息。为了了解训练数据中存在的两种模态之间内在关系,设计了无监督特征融合(UFF)模块。提出了一种逐片对比损失来训练特征融合模块:给定RGB特征 和点云特征
,目的是鼓励来自同一位置的不同模态的特征具有更多的对应信息,而不同位置的特征具有更少的对应信息。

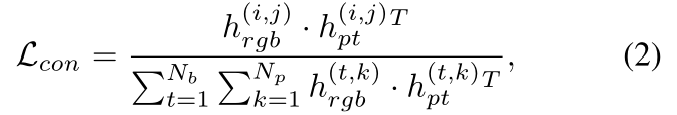
其中是批量大小,而
是非零补丁号。UFF是一个统一的模块,使用MVTec-3D AD的所有类别的训练数据进行训练。
在推理阶段,将MLP层输出连接为表示为 的融合补丁特征:
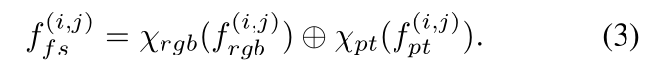
3.4方法细节: Decision Layer Fusion 决策层融合
工业异常的一部分只出现在单个领域(例如,马铃薯的突出部分),多模态特征之间的对应关系可能不是非常明显。此外,尽管特征融合促进了多模态特征之间的交互,但我们仍然发现在融合过程中丢失了一些信息。
为了解决上述问题,提出利用多个存储库来存储原始颜色特征、位置特征和融合特征。我们将这三种存储器组分别表示为、
和
。参考 PatchCore 来构建这三个内存库,在推理过程中,每个内存库都用于预测异常分数和分割图。然后,使用两个可学习的一类支持向量机(OCSVM)
和
来对异常分数a和分割图 S 做出最终决策。上述过程称之为决策层融合(DLF),可以描述为:
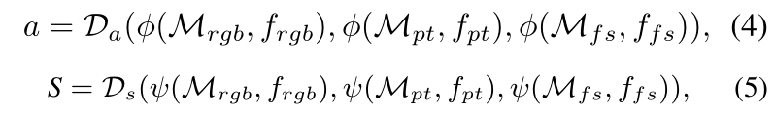
其中φ,ψ是引入的分数函数,可以公式化为:
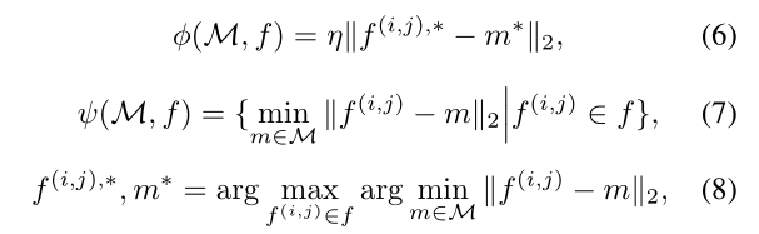

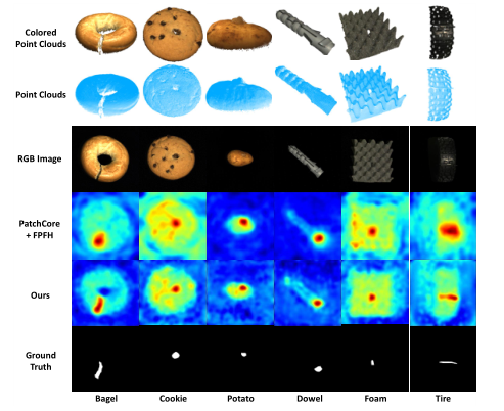
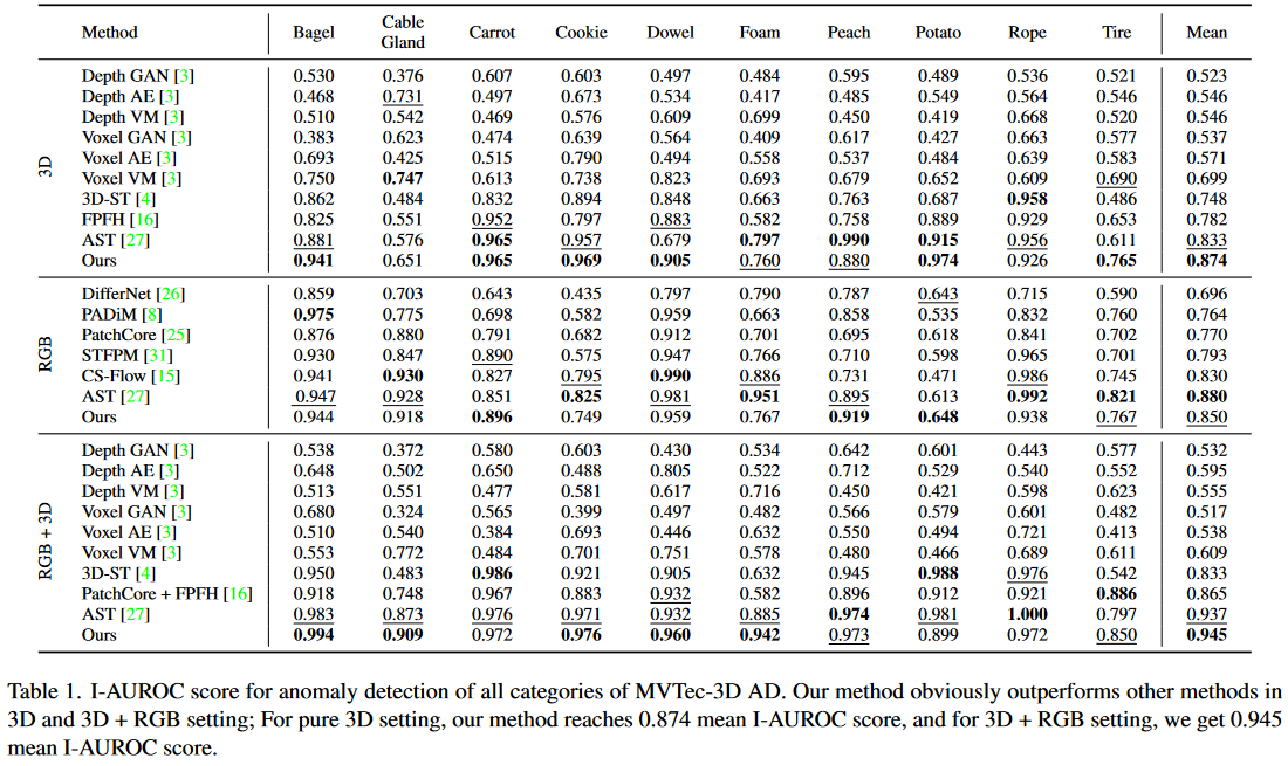
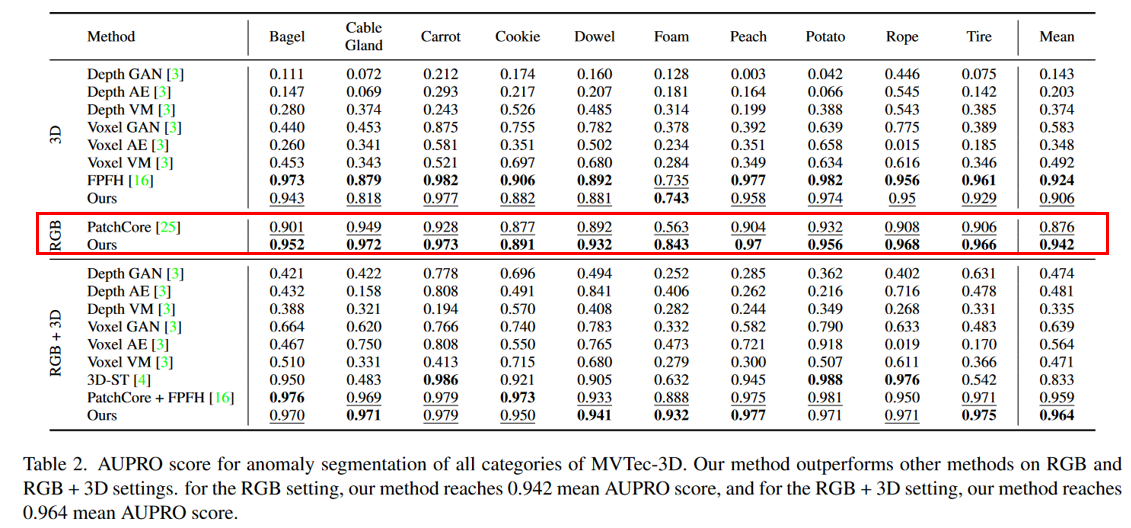
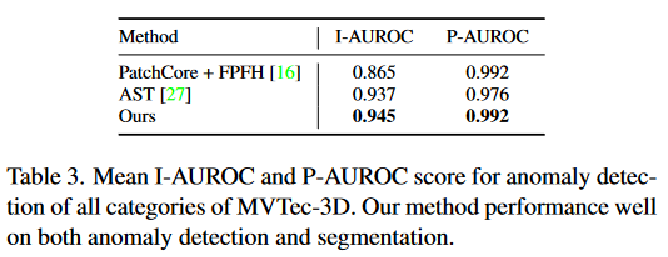
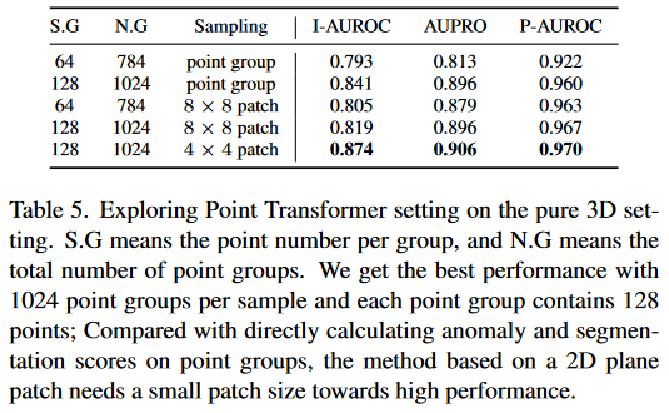
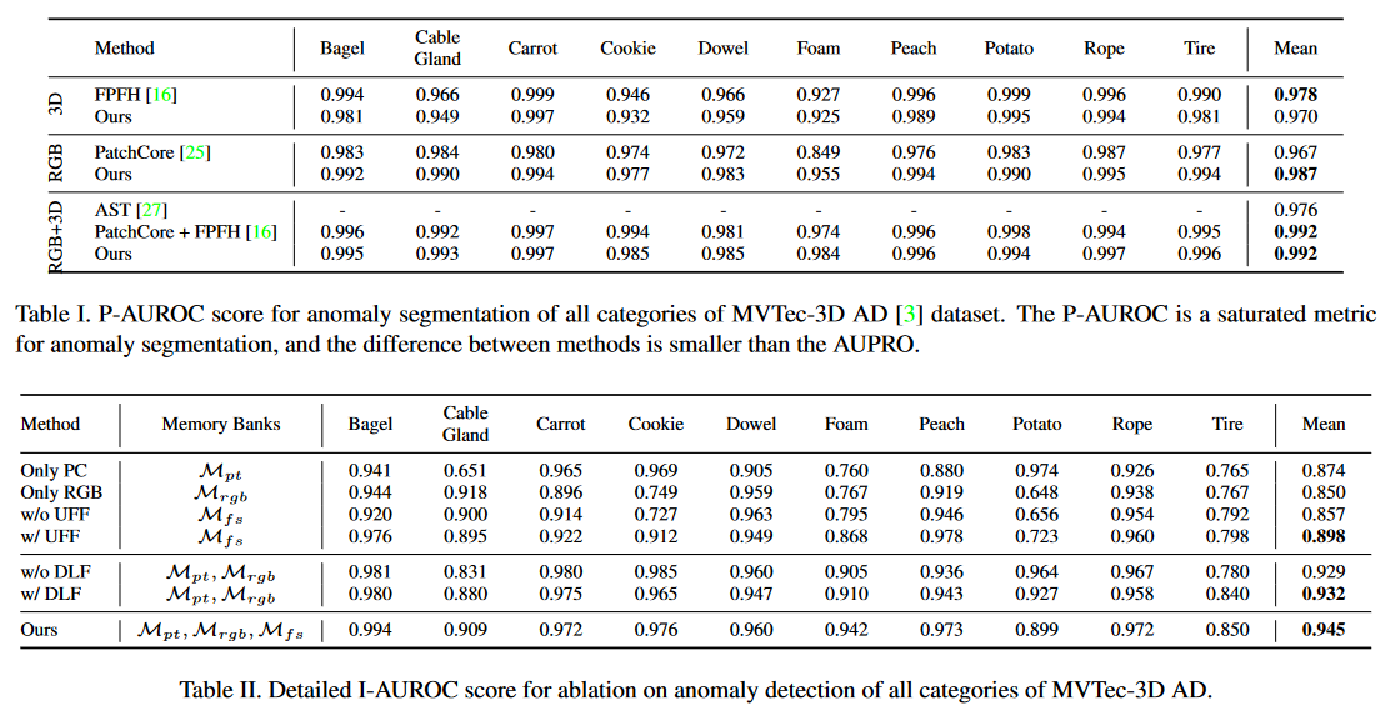
实验结果:

关注下方《学姐带你玩AI》🚀🚀🚀
回复“CVPR”免费领取500+篇顶会论文合集
码字不易,欢迎大家点赞评论收藏!

















 8549
8549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









