







为进一步提高模型的性能,我们将CNN在局部特征提取方面的优势与Transformer在全局信息建模方面的优势两相结合,提出了CNN-Transformer混合架构。目前,它已经成为我们研究视觉任务、发文章离不开的模型。针对CNN+transformer组合方向的研究也成为了当下计算机视觉领域研究中的大热主题。
CNN-Transformer架构凭借众所周知的优势,在视觉任务上取得了令人瞩目的效果,它不仅可以提高模型在多种计算机视觉任务中的性能,还能实现较好的延迟和精度之间的权衡。为挖掘CNN-Transformer混合架构更多的潜力,有关于它的各种变体的研究也逐步增多。
为了方便同学们了解CNN-Transformer的最新进展与研究思路,我这次就和大家分享该架构常用的8种魔改方法,包含早期层融合、模块融合、基于注意力的融合等。每种方法的代表性模型以及配套的论文代码也都整理了,希望同学们阅读后可以获得缝合模块的启发,快速涨点。
23个模型原文及开源代码需要的同学看文末
1.早期层融合
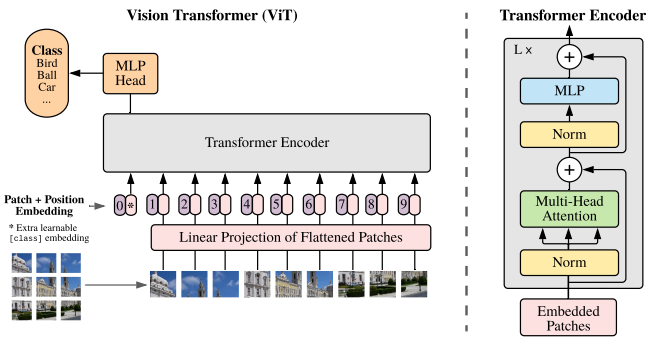
Hybrid ViT
论文:AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
用于大规模图像识别的Transformer
「简述:」Transformer架构在自然语言处理中很成功,但在计算机视觉中的应用有限。目前,注意力机制主要与卷积神经网络结合使用。我们发现,可以直接在图像补丁序列上应用纯Transformer,它在图像分类任务上表现很好。与最先进的卷积神经网络相比,Vision Transformer(ViT)在多个基准测试中取得了出色的结果,而且训练所需的计算资源大大减少。
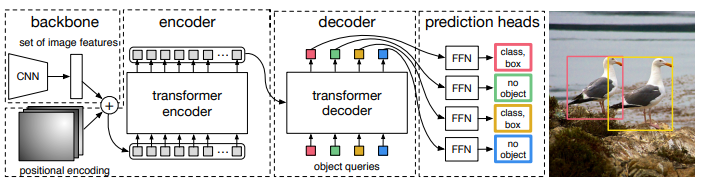
DETR
论文:End-to-End Object Detection with Transformers
使用Transformers进行端到端目标检测
「简述:」论文提出了一种新的目标检测方法,将目标检测看作是一个直接集合预测问题。这种方法简化了检测流程,不需要像非最大抑制或锚点生成这样的手动设计组件。新方法的主要成分包括一个全局损失和一个变压器编码器-解码器架构。它通过推理对象之间的关系和全局图像上下文,直接并行输出最终预测集。这个模型概念简单,不需要专门的库,在COCO数据集上的准确性和运行时性能与Faster R-CNN相当。
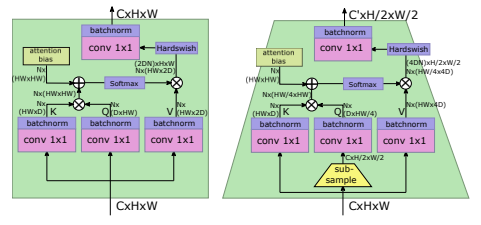
LeViT
论文:LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference
用于更快推理的 ConvNet 服装中的视觉transformer
「简述:」论文设计了一种名为LeViT的混合神经网络架构,用于快速推理图像分类。该架构结合了卷积网络和视觉Transformer的优点,并引入了一些新的方法来提高准确性和效率。作者在不同硬件平台上进行了广泛的实验,结果表明LeViT在速度/准确性权衡方面优于现有的卷积网络和视觉Transformer。
CPVT
论文:CONDITIONAL POSITIONAL ENCODINGS FOR VISION TRANSFORMERS
视觉transformer的条件位置编码
「简述:」论文提出了一种条件位置编码方案,用于视觉transformer。与先前的位置编码不同,作者的方案是动态生成的,并根据输入令牌的局部邻域进行条件化。这使得该方案可以推广到比模型在训练过程中见过的任何序列更长的输入序列,并提高了性能。作者还使用一个简单的位置编码生成器实现了该方案,并将其命名为条件位置编码视觉transformer(CPVT)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1897
1897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









