









在写论文时,一些通用性模块可以在不同的网络结构中重复使用,这简化了模型设计的过程,帮助我们加快了实验的迭代速度。
比如在视觉任务中,即插即用的特征融合模块可以无缝集成到现有网络中,以灵活、简单的方式提升神经网络的性能。这类模块通过专注于数据的关键点和模式,帮助模型更有效地学习特征,从而提高在各种视觉任务中的准确度和效率。
以南航提出的AFF模块、港大等提出的即插即用轻量级模块AdaptFormer为例:
-
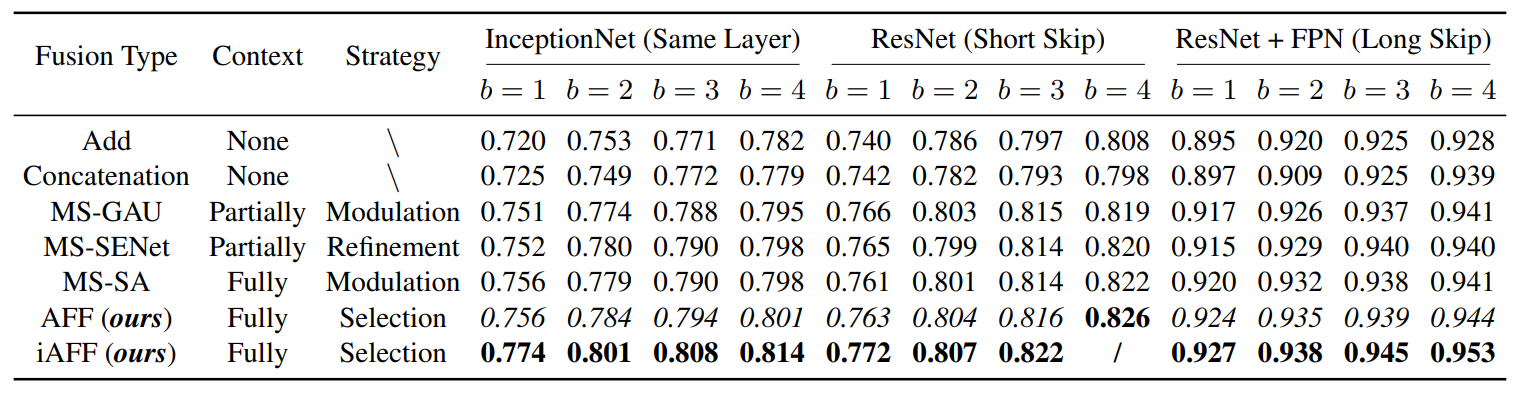
AFF模块:一种即插即用的新注意力特征融合机制AFF,仅使用了35.1M的参数量就能达到性能优于SKNet、SENet等方法的效果。
-
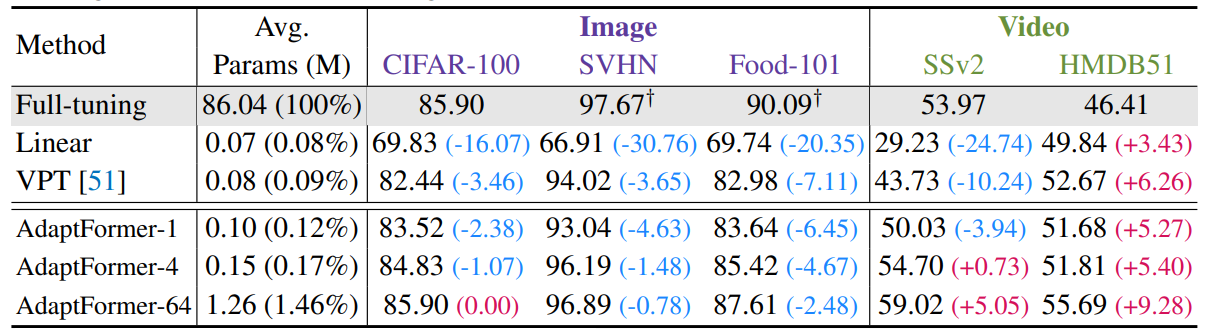
AdaptFormer:核心是一种轻量级模块,微调不到0.2%,就能提高ViT的迁移能力,而不需要更新其原始的预训练参数。
为方便各位理解和运用,我这次精挑细选了8个即插即用特征融合模块。这些模块的来源文章以及代码我都整理了,并简单罗列了创新点,更详细的工作细节建议各位仔细阅读原文。
论文原文以及开源代码需要的同学看文末
Attentional Feature Fusion
方法:论文提出了一种统一的、普遍适用的特征融合方案,名为注意力特征融合,用于处理现代网络体系结构中的特征融合。为了更好地融合具有不一致语义和尺度的特征,作者提出了一种多尺度通道注意力模块。此外,作者还发现初始特征图的集成可能成为一个瓶颈,通过添加另一层注意力来缓解这个问题,称之为迭代注意力特征融合。
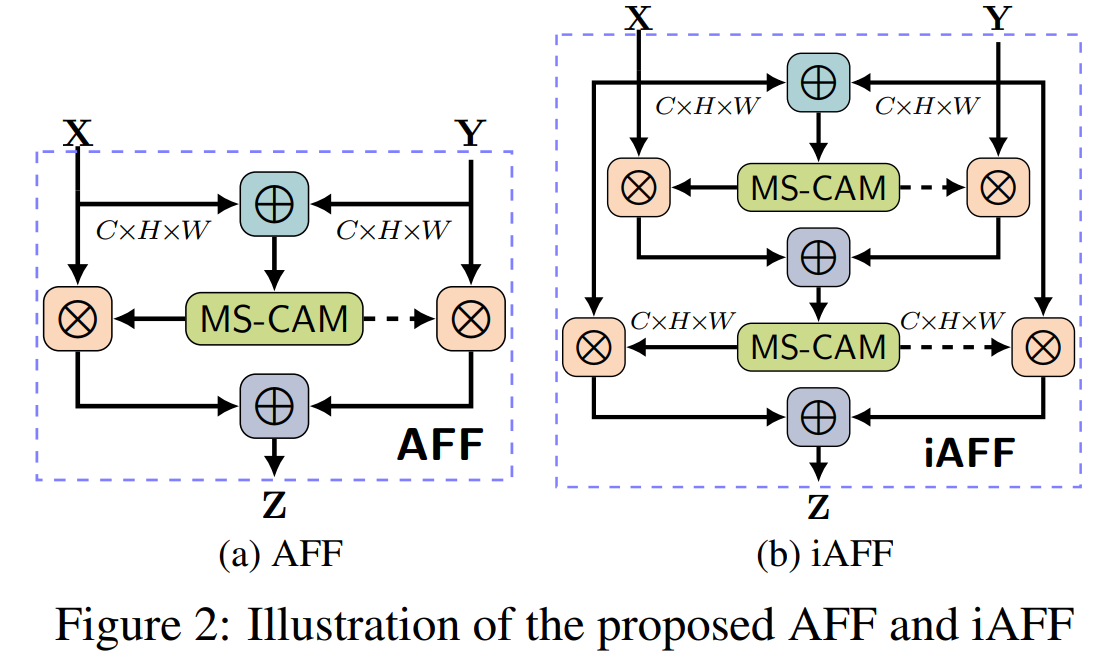
创新点:
-
提出了一种统一且通用的方案,即注意力特征融合,适用于大多数常见场景,包括由短路连接和长路连接引起的特征融合以及在Inception层内部的特征融合。
-
提出了一种多尺度通道注意力模块,用于更好地融合具有不一致语义和尺度的特征。通过在通道维度上聚合多尺度的上下文信息,可以同时强调分布更广泛的大对象和分布更局部的小对象,从而有助于网络在极端尺度变化下识别和检测对象。
-
提出了迭代注意力特征融合方法,通过在输入特征中添加另一个注意力模块来改善初始融合质量,并通过逐步改进初始融合来提高性能。通过简单地将现有的特征融合运算符替换为提出的迭代注意力特征融合模块,可以提高各种网络的性能。
AdaptFormer: Adapting Vision Transformers for Scalable Visual Recognition
方法:论文提出了一种名为AdaptFormer的有效的适应Transformer的方法,可以高效地将预训练的ViTs适应到许多不同的图像和视频任务中。与现有的完全微调模型相比,AdaptFormer引入了轻量级模块,仅添加了不到2%的额外参数到ViT中,而且在不更新原始预训练参数的情况下,显著优于现有的100%完全微调模型在动作识别基准上的表现。
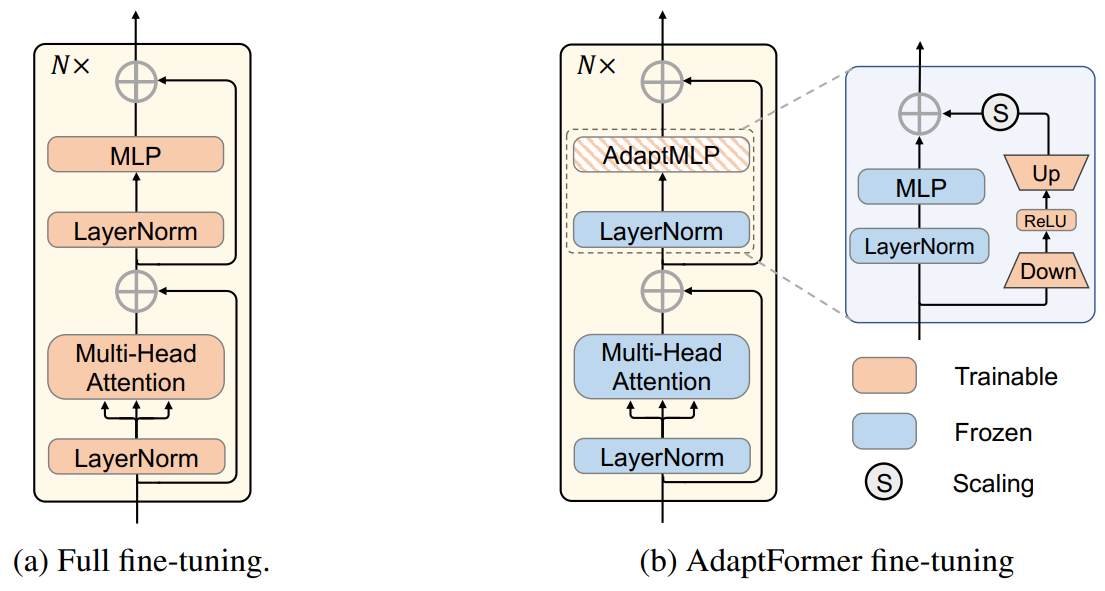
创新点:
-
AdaptMLP模块:作者引入了AdaptMLP模块,用于将预训练的ViT骨干网络适应于多个下游视觉识别任务。AdaptMLP模块包括两个子分支,一个与原始网络的MLP层相同,另一个是额外引入的轻量级模块用于任务特定的微调。AdaptMLP模块只引入少量参数,使得ViT的可迁移性得到提高,相比于全微调方法,在动作识别任务上能够取得更好的性能。
-
平行设计:作者发现平行设计对于特征集成是一种有效的方式。平行设计通过一个独立的分支保留原始特征,并通过元素级缩放求和聚合更新的上下文信息。因此,作者选择了平行设计作为默认设置,因为它在性能上具有优势。平行设计与全微调相比,在参数开销较小的情况下,能够获得更好的性能。
DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention
方法:论文提出了一种细节增强注意力网络(DEA-Net)来解决单一图像去雾问题,其中包含细节增强卷积(DEConv)和内容引导注意力(CGA)两个部分。CGA通过为每个通道分配唯一的空间重要性映射(SIM)来关注特征中编码的更有用的信息,并提出了一个CGAFusion,即插即用的特征融合模块。通过结合上述组件,DEA-Net能够恢复高质量的无雾图像,实验证明其在PSNR指数上超过最先进的方法,并且只使用了3.653 M个参数。
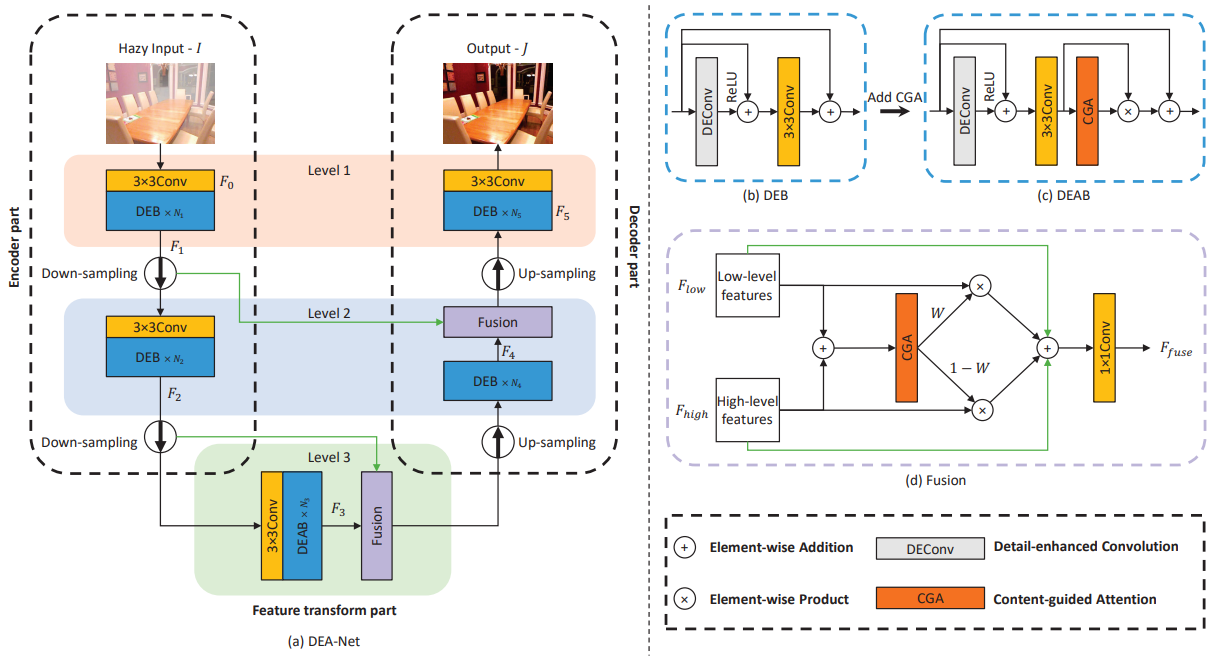
创新点:
-
设计了一种细节增强卷积(DEConv)层,通过并行部署多个普通卷积和差异卷积来提取特征,增强了表示和泛化能力,同时不引入额外的参数和计算成本。
-
提出了一种内容引导注意力(CGA)机制,可以生成通道特定的空间重要性图(SIMs),并将通道注意力和空间注意力进行融合,以实现信息交互和有效的梯度流动。
-
提出了基于CGA的混合融合方案,可以自适应地融合编码器部分的低级特征和相应的高级特征,通过学习到的空间权重对特征进行调节。
CFNet: Cascade Fusion Network for Dense Prediction
方法:论文提出了一种名为CFNet的新的架构,用于密集预测任务。与通常使用轻量级融合模块来融合由重型分类主干提取的多尺度特征的FPN及其变种不同,CFNet通过引入多级级联阶段来学习基于提取的高分辨率特征的多尺度表示。通过将特征集成操作插入到主干中,可以有效利用整个主干的大部分来有效地融合多尺度特征。
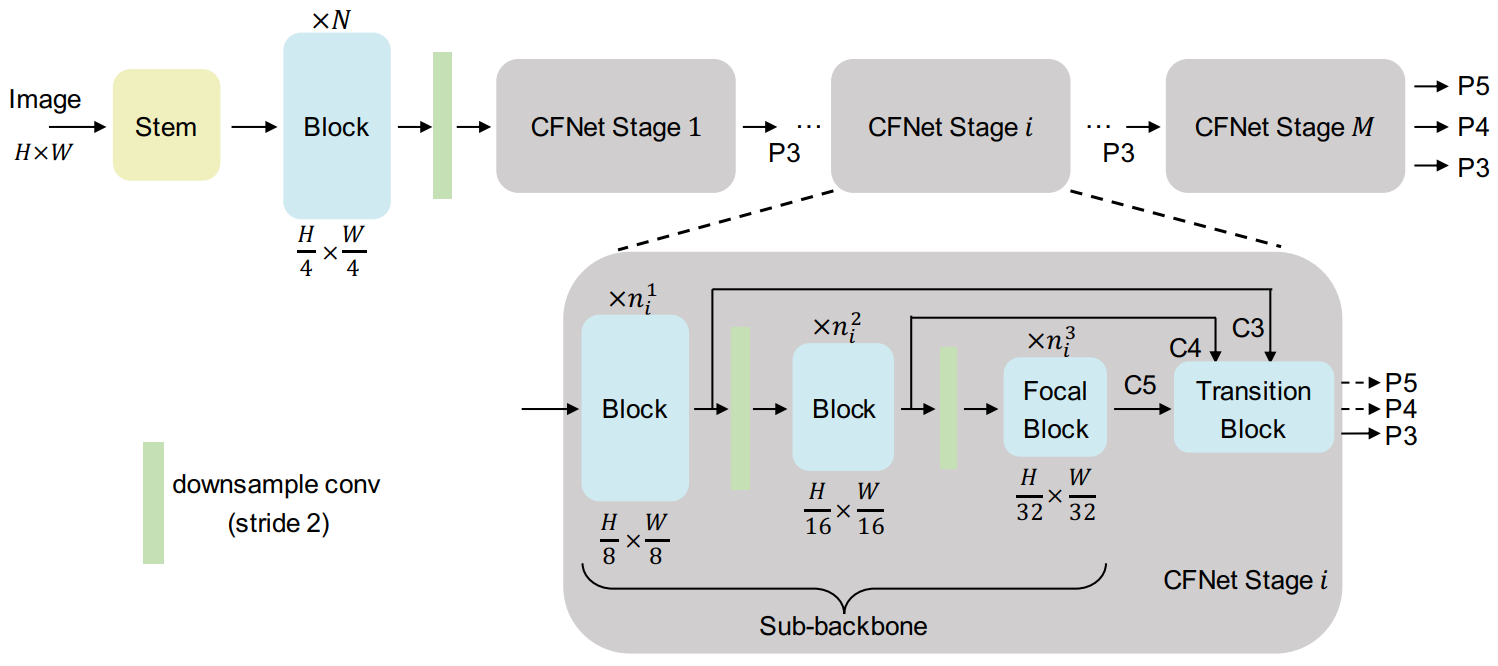
创新点:
-
CFNet引入了级联阶段的创新架构,以学习基于高分辨率特征的多尺度表示。
-
CFNet通过将特征集成操作插入到主干中,有效利用了整个主干的大部分来融合多尺度特征。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“特征即插”获取全部论文+代码
码字不易,欢迎大家点赞评论收藏















 948
948











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









