







目录
前言
Selective Kernel Networks(SKNet)
来源:CVPR2019
官方代码:https://github.com/implus/SKNet
什么是感受野?感受野(receptive field)是指在网络的前向传播过程中,每个神经元对输入数据的区域大小。换句话说,它表示了神经元在输入空间中接收信息的范围。在图像处理任务中,神经元的感受野大小通常与输入图像的像素大小有关。较小的感受野可以捕获局部细节,而较大的感受野则可以捕获更大范围的整体结构和语境信息。因此,设计合适大小的感受野对于不同的任务和网络架构至关重要。SKAttention能够根据输入动态选择不同大小的卷积核。这种设计使得网络可以根据输入自适应地调整其感受野,从而更有效地捕获不同尺度的特征。这在处理诸如图像分类和对象检测等任务中特别有用,这些任务中输入特征的尺度和大小可能有很大的变化。
一、SKNet结构
SKNet结构如图一所示。SK卷积由Split,Select和Split三个操作来实现。Split操作:使用多个不同大小的卷积核对输入特征进行卷积操作(每次卷积操作即一组CBR),得到多个尺度的特征表示,再将这些特征表示拼接起来;Fuse操作:由两个全连接层、一个全局平均池化及Relu激活函数组成,首先对多个分支元素求和,即相同形状的张量中的对应元素进行相加。然后进行全局平均池化,压缩为具有相同通道数的特征向量,捕捉全局信息。接着先降维再升维,得到 K 个尺度对应的通道描述符,并将升维后的特征向量重塑为与输入的大小相同,重塑后的特征向量按照第 0 维度(K 维度)进行堆叠,形成一个新的张量,通过 softmax 函数将每个尺度对应的权重进行归一化处理,使得它们的总和为 1。Selecte操作:将每个尺度的权重与对应的之前卷积之后的结果加权求和,得到不同的分支权重组合,影响融合后的层级V的有效感受野大小。

精读:Split操作:目的:为了捕获多尺度的特征信息,Split操作首先将输入特征通过不同大小的卷积核处理。常见的配置可能包括使用3x3、5x5等不同尺寸的卷积核。
实现:每个卷积后接批归一化(Batch Normalization)和ReLU激活函数,形成一组卷积-批归一化-激活(CBR)单元。这些不同尺度的特征图接着被拼接在一起,形成一个更丰富的特征表示。
Fuse 操作:目的:为了综合多尺度的信息并生成每个尺度的重要性权重,Fuse操作处理拼接后的特征,通过全局信息来指导选择操作。
实现:求和:首先将所有分支的特征图进行逐元素相加。全局平均池化:接着对求和后的结果进行全局平均池化,从而压缩特征至一个全局描述符。降维与升维:通过两个全连接层(通常先降维后升维),处理池化后的特征,生成每个尺度的通道描述符。重塑与归一化:将通道描述符重塑成原始输入的尺寸,并通过softmax进行归一化,生成每个尺度的权重。
Select 操作:目的:根据Fuse操作生成的尺度权重,动态选择并融合不同尺度的特征。
实现:将每个尺度的权重应用于对应的卷积输出(从Split操作得到),通过加权求和的方式,结合这些特征。这样,网络可以侧重于当前最有效的特征尺度,从而优化处理结果。
二、SKNet计算流程
对于任意给定的特征映射![]() ,默认情况下我们首先进行两个变换
,默认情况下我们首先进行两个变换![]() :X→
:X→![]() ∈
∈![]() 和
和![]() :X→
:X→![]() ∈
∈![]() ,核大小分别为3×3和5×5,将其分为
,核大小分别为3×3和5×5,将其分为![]() 和
和![]() ,并将
,并将![]() 和
和![]() 按元素求和,得到U:
按元素求和,得到U:
![]()
然后通过全局平均池化![]() 将(B,C,H,W)压缩到(B,C),单个特征向量
将(B,C,H,W)压缩到(B,C),单个特征向量![]() :
:
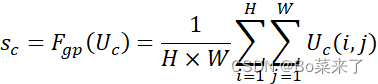
然后经过全连接层![]() 进行降维和升维:
进行降维和升维:
![]()
接下来通过Softmax得到各个特征尺度的权重,并在Select中将其与卷积后的结果加权求和。
三、SKNet参数
利用thop库的profile函数计算FLOPs和Param。Input:(512,7,7)。
| Module | FLOPs | Param |
| SKAttention | 1079555584 | 22192192 |
四、代码详解
import torch
from torch import nn
from collections import OrderedDict
class SKAttention(nn.Module):
#通道数channel, 卷积核尺度kernels, 降维系数reduction, 分组数group, 降维后的通道数L
def __init__(self, channel=512, kernels=[1, 3, 5, 7], reduction=16, group=1, L=32):
super().__init__()
self.d = max(L, channel // reduction)
self.convs = nn.ModuleList([])
#有几个kernels,就有几个尺度, 每个尺度对应的卷积层由Conv-bn-relu实现
for k in kernels:
self.convs.append(
nn.Sequential(OrderedDict([
('conv', nn.Conv2d(channel, channel, kernel_size=k, padding=k // 2, groups=group)),
('bn', nn.BatchNorm2d(channel)),
('relu', nn.ReLU())
]))
)
self.fc = nn.Linear(channel, self.d)
self.fcs = nn.ModuleList([])
# 将降维后的通道数L通过K个全连接层得到K个尺度对应的通道描述符表示, 然后基于K个通道描述符计算注意力权重
for i in range(len(kernels)):
self.fcs.append(nn.Linear(self.d, channel))
self.softmax = nn.Softmax(dim=0)
def forward(self, x):
B, C, H, W = x.size()
# 存放多尺度的输出
conv_outs=[]
## Split: 将输入特征x通过K个卷积层得到K个尺度的特征
for conv in self.convs:
scale = conv(x)
conv_outs.append(scale)
feats=torch.stack(conv_outs,0) # torch.stack()函数用于在新创建的维度上对输入的张量序列进行拼接, (B,C,H,W)-->(K,B,C,H,W), K为尺度数
## Fuse: 首先将多尺度的信息进行相加,sum()默认在第一个维度进行求和
U=sum(conv_outs) # (K,B,C,H,W)-->sum-->(B,C,H,W)
# 全局平均池化操作: (B,C,H,W)-->mean-->(B,C,H)-->mean-->(B,C) 【mean操作等价于全局平均池化的操作】
S=U.mean(-1).mean(-1)
# 降低通道数,提高计算效率: (B,C)-->(B,d)
Z=self.fc(S)
# 将紧凑特征Z通过K个全连接层得到K个尺度对应的通道描述符表示, 然后基于K个通道描述符计算注意力权重
weights=[]
for fc in self.fcs:
weight=fc(Z) #恢复预输入相同的通道数: (B,d)-->(B,C)
weights.append(weight.view(B,C,1,1)) # (B,C)-->(B,C,1,1)
scale_weight=torch.stack(weights,0) #将K个通道描述符在0个维度上拼接: (K,B,C,1,1)
scale_weight=self.softmax(scale_weight) #在第0个维度上执行softmax,获得每个尺度的权重: (K,B,C,1,1)
## Select
V=(scale_weight*feats).sum(0) # 将每个尺度的权重与对应的特征进行加权求和,第一步是加权,第二步是求和:(K,B,C,1,1) * (K,B,C,H,W) = (K,B,C,H,W)-->sum-->(B,C,H,W)
return V
if __name__ == '__main__':
from torchsummary import summary
from thop import profile
model = SKAttention(channel=512, reduction=8)
# summary(model, (512, 7, 7), device='cpu', batch_size=1)
flops, params = profile(model, inputs=(torch.randn(1, 512, 7, 7),))
print(f"FLOPs: {flops}, Params: {params}")















 2581
2581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









