







SOLO神经网络学习

在博客的最开始,先简单谈谈图像处理的几大目标。
首先是最基本的目标分类(Object Classification),输出结果“图像中是气球”;
然后目标检测(Object detection)是在图像分类的基础上,给出每个气球的位置与标签;
语义分割的目标是将目标与背景分离开,不同的目标之间也分离开,但是同类目标之间不做识别;
而实例分割则达到将每个物体分离并识别的效果。
当然,实例分割并不就完全比语义分割高级,语义分割能够处理不可数物体,而实例分割目前只能处理可数物体,这是其尚未解决的问题。
实例分割最热门的论文与算法当属Mask R-CNN,属于开山鼻祖一类的,有兴趣的同学可以去搜一搜,Mask R-CNN是基于Faster R-CNN添加了分割模块实现的,精度很高,但是相对的也很复杂,计算量不小。
而本文的SOLO算法(Segmenting Objects by Locations)也是实例分割算法的一种,评价类似于“实例分割算法领域的YOLO算法”。下面我将结合其论文原文《SOLO: Segmenting Objects by Locations》和网上一些解读来学习下这篇论文。
Abstract
按作者的原话,他们提出了一种简单的令人尴尬的方法来实现实例分割。
作者引入了一个“实例类别”的概念,即根据实例的位置和大小为实例中的每个像素分配类别,从而将实例分割转化为一个单次分类问题(是不是听起来跟YOLO的思想十分接近)。
Introduction
最近的实例分割方法可以分为两类,即自顶向下和自底向上式。
前一种方法,即“detect-then-segment”,首先检测边界框,然后分割每个边界框中的实例mask。
后一种方法学习一个亲缘关系,通过推离属于不同实例的像素和拉近同一实例的像素,分配一个嵌入向量给每个像素,然后通过一个分组后处理来分离实例。
这两个方法都是逐步且间接的,要么严重依赖于精确的BBox检测,要么依赖于逐像素嵌入学习和分组处理。
而作者的做法是直接分割实例mask,使用全实例mask注释来监督,而不是利用Box中的mask或额外的像素成对关系。
这里作者提出了一个问题:图像中实例之间的根本差异是什么?他们通过对MS COCO数据集进行分析后发现,98.3%的对象中心距离大于30像素,剩下1.7%的对象中,40.5%的对象大小比例大于1.5倍。
也就是说,图像中的实例要么中心位置不同,要么大小比例不同(否则就完全重叠了,很好理解,这种极端情况可以不考虑)。
那么我们也可以想到作者的思路了,那就是利用中心位置和物体大小直接区分实例。
作者引入“实例类别”的概念来区分对象实例,即量化的中心位置和对象大小,然后根据位置分割对象,故而命名为SOLO。
Locations
将图像分为 S × S S\times S S×S的网格(YOLO直呼内行),根据对象中心的坐标,将对象实例分配给其中一个网格单元,作为其中心位置类。
每个输出通道负责一个中心位置类别,相应的通道映射预测属于该位置的对象的实例mask。DeepMask和TensorMask以密集滑动窗口的方式运行,并在固定的局部补丁中分割对象,但是其输出依赖于anchor box的位置和尺寸,SOLO则没有这个问题。
实例位置类别与实例中心位置很接近,所以接下来将每个像素分类到其实例位置类别中,相当于预测每个像素在潜在空间中的目标中心。
将位置预测任务转化为分类任务的重要性在于,分类任务下,使用固定数目的通道去模拟大数量的实例更加直接简单,同时不需要依赖分组或嵌入式学习。
Sizes
作者采用了特征金字塔(FPN)来区分不同大小的实例,将不同大小的对象分配到不同的特征映射级别。这样所有的实例都能有规律地分开,从而能够通过“实例类别”来分类对象。
注意这里的FPN是为了检测图像中不同大小的物体设计的,也是本算法的核心组件之一。
SOLO只需要解决两个像素级分类任务,因此可能可以借用一些最近在语义分割方面的进展来改进SOLO。
SOLO方法解读
界定问题
SOLO框架的核心思想是将实例分割重新定义为练个同时进行的类别感知的预测问题。具体来说,SOLO算法将图像分为 S × S S\times S S×S的网格,如果某一对象的中心落在一个网格单元中,该网格单元负责(1)预测语义类别;(2)分割该实例。
语义类别
对于每个网格,SOLO预测C维输出来表示对象属于某语义类别的概率。这些概率以网格单元为条件,如果网格划分为 S × S S\times S S×S个,那么输出空间就是 S × S × C S\times S\times C S×S×C。
这样设计是基于如下的假设: S × S S\times S S×S网格的每个单元必须属于一个单独的实例,因此只属于一个语义类别。
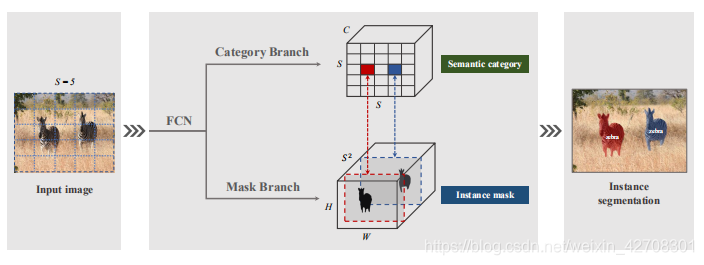
实例Mask
在预测语义类别的同时,每个确定的网格单元将生成相应的实例mask。对于输入图像 I I I,如果我们将其划分为 S × S S\times S S×S的网格,则预计的mask最多为 S 2 S^2 S2个。
作者在一个三维张量的第三个通道中对这些masks进行显式编码。实例mask输出将具有 H I × W I × S 2 H_{I}\times W_{I}\times S^2 HI×WI×S2个维度。第 k k k个通道负责分割网格 ( i , j ) (i,j) (i,j)上的实例,其中 k = i ⋅ S + j k=i\cdot S+j k=i⋅S+j。至此,语义类别和类别未知的mask建立起了一一对应的关系。
在网络开始时,直接向网络提供标准化像素坐标,具体来说,作者创建了一个具有与包含像素坐标的输入相同大小的张量,并将其归一化。然后,将这个张量连接到输入特征,并传递给下层。
通过简单地让卷积访问它自己的输入坐标,可以给传统的FCN模型添加空间功能。如果原始特征张量大小为 H × W × D H\times W\times D H×W×D,则新的张量大小为 H × W × ( D + 2 ) H\times W\times (D+2) H×W×(D+2),其中最后两个通道为 x − y x-y x−y像素坐标。
形成实例分割
在SOLO中,类别预测和相应的mask通过他们的参考网格单元自然关联,即 k = i ⋅ S + j k=i\cdot S+j k=i⋅S+j。在此基础上,可以直接对每个网格形成最终的实例分割结果。原始实例分割结果是通过收集所有网格结果生成的,最后,用非极大值抑制(NMS)算法得到最终的实例分割结果,不需要其他后处理操作。
网络结构
SOLO网络的骨干是卷积网络,使用FPN在固定通道数量(通常256-d)下给特征金字塔每层生成不同大小的特征映射。这些映射被用作每个预测端的输入:语义类别和实例mask。不同端的权重在不同level上共享,不同的金字塔中网格数可能有所不同。只有最后一个卷积层是不共享的。
SOLO学习
标记分配
对于类别预测分支,网络需要给出每个 S × S S\times S S×S网格的对象类别概率。具体来说,网格 ( i , j ) (i,j) (i,j)如果落在任何ground truth mask的中心区域则视为正样本,否则为负样本。
作者采用了类似中心采样的方法来处理mask的类别区分。给定质心 ( c x , c y ) (c_x,c_y) (cx,cy),ground truth mask的宽高 w , h w,h w,h,则中心区域通过一个常比例系数 ϵ \epsilon ϵ来控制: ( c x , c y , ϵ w , ϵ h ) \left ( c_x,c_y,\epsilon w,\epsilon h \right ) (cx,cy,ϵw,ϵh)。作者设 ϵ = 0.2 \epsilon=0.2 ϵ=0.2,每个ground mask truth包含平均3个正样本。
除了实例类别的标签外,作者还给每个正样本设置了一个二进制分割mask。一共有 S 2 S^2 S2个网格,所以每张图片也就有 S 2 S^2 S2个输出mask。每个正样本,对应的目标二进制mask将被标注。
损失函数
SOLO的损失函数定义如下: L = L c a t e + λ L m a s k L=L_{cate}+\lambda L_{mask} L=Lcate+λLmask
其中, L c a t e L_{cate} Lcate是用于语义分类的传统焦点损失函数, L m a s k L_{mask} Lmask是mask预测的损失: L m a s k = 1 N p o s ∑ k 1 { P i , j ∗ > 0 } d m a s k ( m k , m k ∗ ) L_{mask}=\frac{1}{N_{pos}}\sum_{k}\mathbb{1}_{\left \{ P_{i,j}^*> 0 \right \}}d_{mask}(m_k,m_k^*) Lmask=Npos1k∑1{Pi,j∗>0}dmask(mk,mk∗)
如果按从左到右、从上到下索引单元格,则这里的 i = [ k / S ] , j = k m o d S i=[k/S],j=kmodS i=[k/S],j=kmodS。 N p o s N_{pos} Npos表示正样本个数, p ∗ p^* p∗和 m ∗ m^* m∗分别表示类别目标和mask目标。 1 \mathbb{1} 1是指示函数,如果 p i , j ∗ > 1 p_{i,j}^*>1 pi,j∗>1则为1,否则为0。
作者比较了不同计算 d m a s k ( ⋅ , ⋅ ) d_{mask}(\cdot,\cdot) dmask(⋅,⋅)的方法:Binary Cross Entropy,Focal Loss和Dice Loss,最终选中了Dice Loss。 λ \lambda λ设定为3。
Dice Loss定义如下: L D i c e = 1 − D ( p , q ) L_{Dice}=1-D(p,q) LDice=1−D(p,q)
其中 D D D是骰子系数,定义如下: D ( p , q ) = 2 ∑ x , y ( p x , y ⋅ q x , y ) ∑ x , y p x , y 2 + ∑ x , y q x , y 2 D(p,q)=\frac{2\sum_{x,y}\left ( p_{x,y}\cdot q_{x,y} \right )}{\sum_{x,y}p_{x,y}^{2}+\sum_{x,y}q_{x,y}^{2}} D(p,q)=∑x,ypx,y2+∑x,yqx,y22∑x,y(px,y⋅qx,y)
其中 p x , y p_{x,y} px,y和 q x , y q_{x,y} qx,y分别为预测soft mask p p p和ground truth mask q q q在点 ( x , y ) (x,y) (x,y)的像素值。
推理
给定一个输入图像,通过骨干网络和FPN,获取单元格 ( i , j ) (i,j) (i,j)上的类别分数 p i , j p_{i,j} pi,j与相应的mask m k m_k mk, k = i ⋅ S + j k=i\cdot S+j k=i⋅S+j。
首先使用置信度0.1的阈值过滤信度较低的预测,然后选择500个得分最高的mask,并将他们提供给NMS操作。另外,使用0.5的阈值来将预测的soft masks转换为二进制掩码。
Maskness
计算每个预测出的mask的maskness,maskness定义为预测掩码的质量和置信度, m a s k n e s s = 1 N f ∑ i N f p i maskness=\frac{1}{N_f}\sum _{i}^{N_f}p_i maskness=Nf1∑iNfpi。这里, N f N_f Nf是预测 s o f t m a s k p soft mask p softmaskp的前景像素数,即值大于阈值0.5的像素。每个预测的分类得分乘以maskness,作为最终的置信度得分。
Decoupled SOLO
SOLO head的output是由网格数决定的,比如 S = 20 S=20 S=20时,输出的是一个 S 2 = 400 S^2=400 S2=400的通道数的特征图。但是,这种预测有些多余,因为在大多数情况下,图像中的目标是稀疏的,不会每个网格内都有物体中心。因此,作者进一步提出了一种等效的并且更有效的SOLO变种,称为Decoupled SOLO。以下简称D-SOLO。
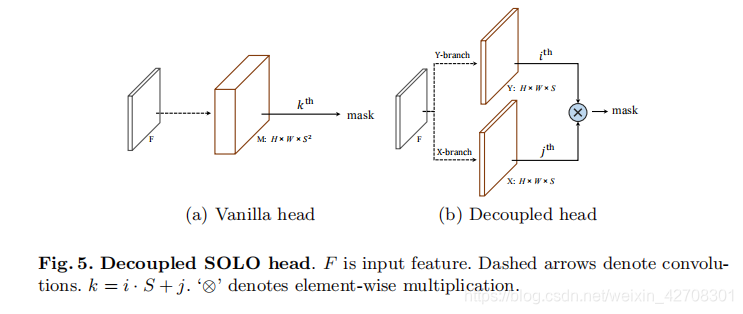
D-SOLO中,原始输出张量
M
∈
R
H
×
W
×
S
2
M\in R^{H\times W\times S^2}
M∈RH×W×S2被两个输出张量
X
∈
R
H
×
W
×
S
X\in R^{H\times W\times S}
X∈RH×W×S和
Y
∈
R
H
×
W
×
S
Y\in R^{H\times W\times S}
Y∈RH×W×S取代,分别对应两个轴。因此,输出空间从
H
×
W
×
S
2
H\times W\times S^2
H×W×S2降低到
H
×
W
×
2
S
H\times W\times 2S
H×W×2S。对于一个位于网格位置
(
i
,
j
)
(i,j)
(i,j)的对象,该对象的预测掩膜被定义为两个通道映射的元素的乘积:
m k = x j ⨂ y j m_k=x_j\bigotimes y_j mk=xj⨂yj
这么计算的原理是,由于水平和垂直位置类别分别是独立的,一个像素属于位置类别 ( i , j ) (i,j) (i,j)的概率是其属于第 i i i行和第 j j j列的联合概率。

















 2524
2524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









