









 文章讲述了如何使用Numba加速代码,特别是针对GPU编程时的一系列注意事项,包括空间分配、ID处理、numpy函数使用和错误调试。作者分享了一维和二维矩阵计算的示例,并记录了遇到的一个常见错误及其解决方案。
文章讲述了如何使用Numba加速代码,特别是针对GPU编程时的一系列注意事项,包括空间分配、ID处理、numpy函数使用和错误调试。作者分享了一维和二维矩阵计算的示例,并记录了遇到的一个常见错误及其解决方案。
上周使用GPU加速了一个算法,效果特别惊艳,由于算法代码本身没有太大参考价值,所以这里只记录了一些心得体会,以便后续遇到问题进行参考排查
numba加速代码编写注意事项
numba加速代码编写一定要注意:
1、开辟空间,里面所有计算操作要返回的值需要开辟空间;
2、ID号,搞清楚要用一维矩阵进行计算还是二维矩阵进行计算,一维矩阵计算需搞清楚最关键的ID号对应的线程号,二维矩阵则要搞清楚两个ID分别对应的实际意义;
3、在进行GPU内部的函数中,numpy的一些操作是不支持的,尽量在外部定义好,或者搞清楚numpy函数的实际意义,然后用最原始的代码写出来,在CPU上测试等价然后放到GPU中进行测试,这样避免运行时候出错,却找不到原因;
4、在GPU运行的函数中返回的结果变量尽量不要使用切片包装传入,如果要用切片包装可以把变量及整体线程ID号带入实际函数内部。先测试直接输出或改写内部变量值再输出,看看能否正确输出,如果不能正确输出,则是否ID搞错了。(我上周写的代码中这里坑住我了)
如果运行出错不要慌,一般会有提示,根据提示想想原因,或者采用注释法排查问题,一句句代码保留出来进行测试运行,总能找到根本原因及解决办法;
GPU加速效果太惊艳了,编写过程也是很恼火,但看到了最终成果,中间编写的恼火过程可以忽略不计。
贴一个Demo程序,方便了解一般编写规则
一维矩阵GPU计算
from numba import cuda
import numpy as np
import math
from time import time
# # 定义一个简单的设备函数
# @cuda.jit(device=True)
# def square(x):
# return x * x
# 定义一个简单的设备函数
@cuda.jit(device=True)
def add(a,b):
return a+b
@cuda.jit
def gpu_add(a, b, result, n):
idx = cuda.threadIdx.x + cuda.blockDim.x * cuda.blockIdx.x
if idx < n :
result[idx] = add(a[idx] , b[idx])
# result[idx] = a[idx] + b[idx]
def main():
n = 20000000
x = np.arange(n).astype(np.int32)
y = 2 * x
# 拷贝数据到设备端
x_device = cuda.to_device(x)
y_device = cuda.to_device(y)
# 在显卡设备上初始化一块用于存放GPU计算结果的空间
gpu_result = cuda.device_array(n)
cpu_result = np.empty(n)
threads_per_block = 1024
blocks_per_grid = math.ceil(n / threads_per_block)
start = time()
gpu_add[blocks_per_grid, threads_per_block](x_device, y_device, gpu_result, n)
cuda.synchronize()
print("gpu vector add time " + str(time() - start))
start = time()
cpu_result = np.add(x, y)
print("cpu vector add time " + str(time() - start))
if (np.array_equal(cpu_result, gpu_result.copy_to_host())):
print("result correct!")
if __name__ == "__main__":
main()
二维矩阵GPU计算
import numpy as np
from numba import cuda
# 使用Numba的@cuda.jit装饰器来编写CUDA加速的函数
@cuda.jit
def multiply_array(arr, result):
i, j = cuda.grid(2)
if i < arr.shape[0] and j < arr.shape[1]:
result[i, j] = arr[i, j] * 2 # 将数组中的每个元素乘以2
# 生成一个随机的二维数组
arr = np.random.rand(3, 3)
# 将数据传入设备中
d_arr = cuda.to_device(arr)
# 创建一个与输入数组形状相同的结果数组
result = np.empty_like(arr)
# 将结果数组传入设备中
d_result = cuda.to_device(result)
# 定义线程块和线程网格的大小
threads_per_block = (16, 16)
blocks_per_grid_x = (arr.shape[0] + threads_per_block[0] - 1) // threads_per_block[0]
blocks_per_grid_y = (arr.shape[1] + threads_per_block[1] - 1) // threads_per_block[1]
blocks_per_grid = (blocks_per_grid_x, blocks_per_grid_y)
# 在设备上执行加速计算
multiply_array[blocks_per_grid, threads_per_block](d_arr, d_result)
# 将结果拷贝回本地
d_result.copy_to_host(result)
print("Original array:")
print(arr)
print("Result array:")
print(result)
记录一个调试错误,如下图
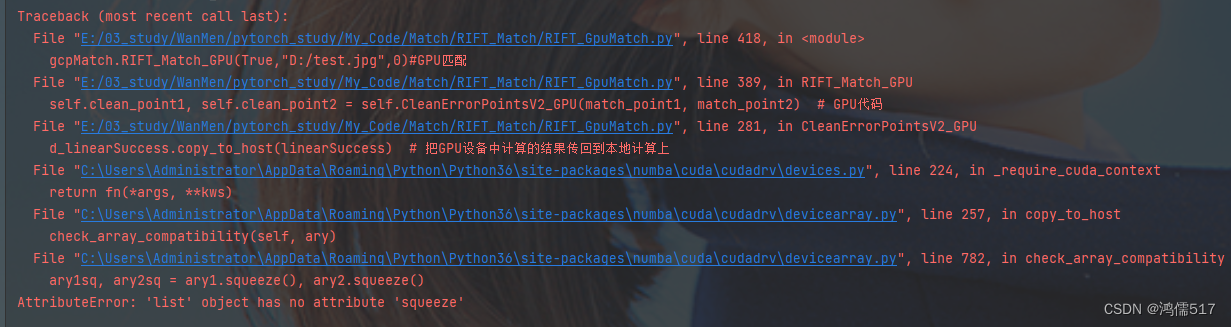
“AttributeError: ‘list’ object has no attribute ‘squeeze’”
该错误是说list没有’squeeze’方法,仔细检查GPU核函数好像没有调用’squeeze’方法,经过调查发现传入GPU设备的代码是list,将初始化方法list变为numpy即可,猜想GPU计算的时候会自动调numpy的’squeeze’方法
更改前:
linearSuccess =[0]* AllNumber # 初始化CPU变量
d_linearSuccess = cuda.to_device(linearSuccess)#变量传入GPU设备
...
更改后:
linearSuccess = np.zeros([AllNumber]) # 初始化CPU变量
d_linearSuccess = cuda.to_device(linearSuccess)#变量传入GPU设备
...


















 631
631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









