






卷积运算
卷积核可以定义,一般为随机的
通道是1,步长是1,计算如下:
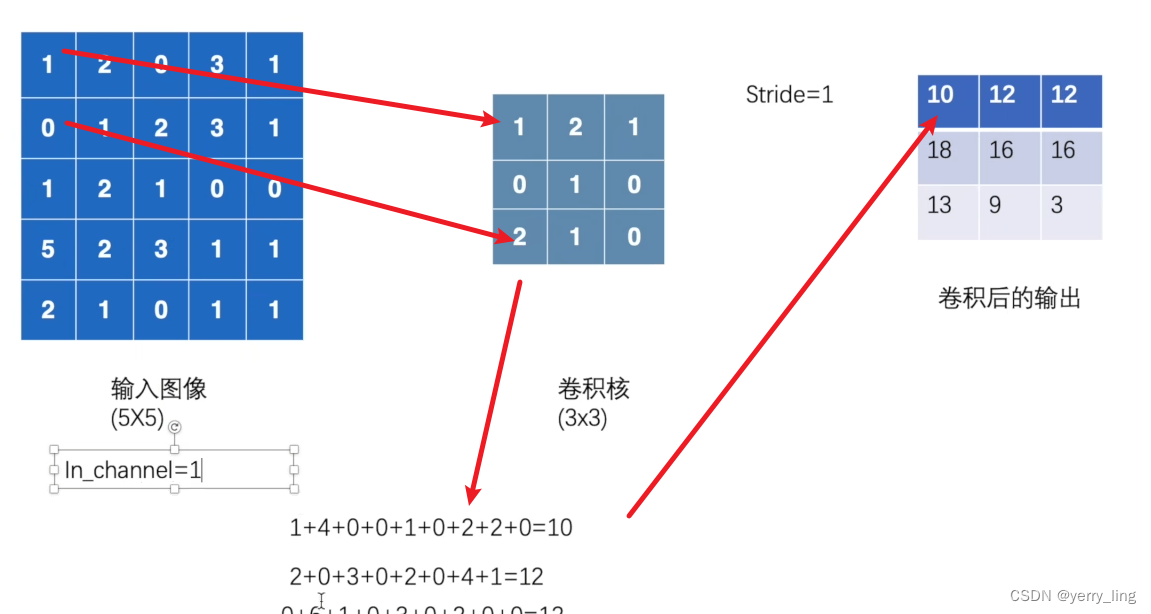
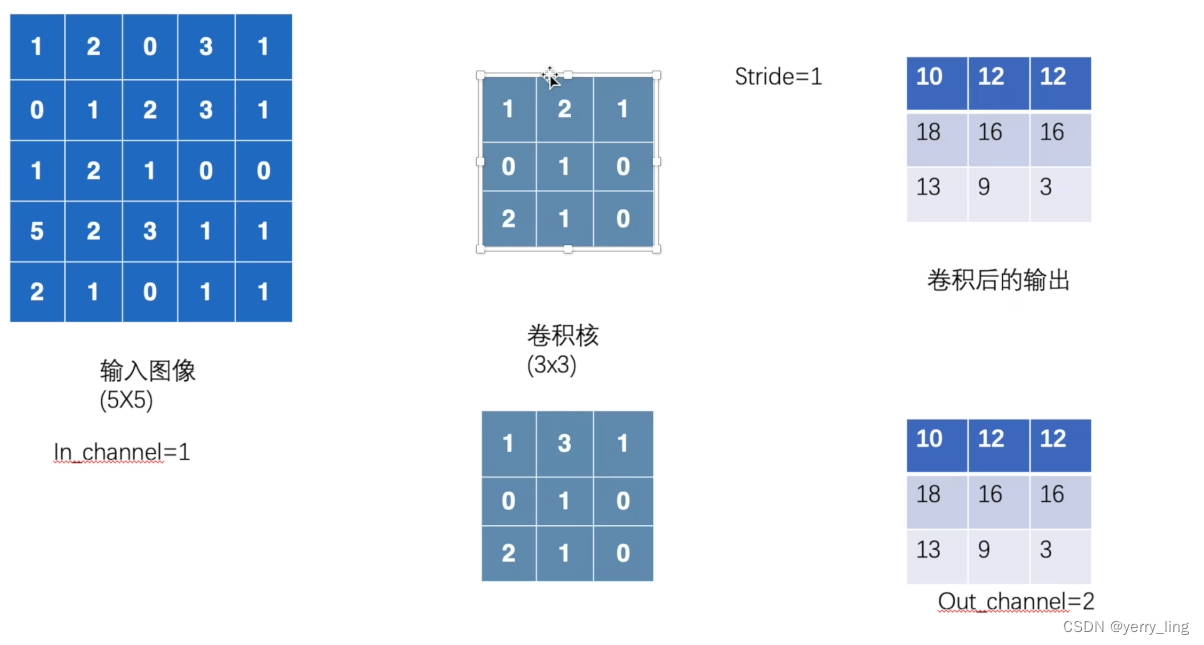
如果有两个卷积核是进行了两次运算会有两次输出结果。
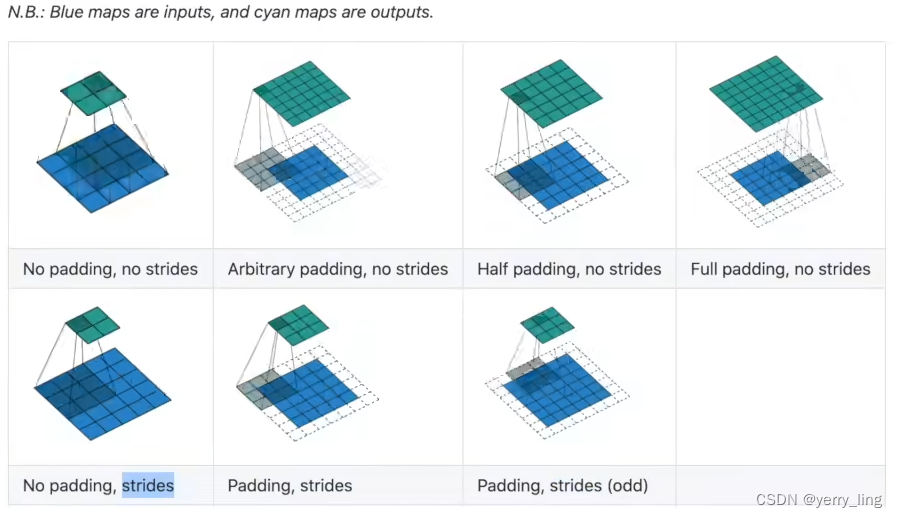
padding就是填充,一般进行卷积后都会缩小,padding能保证图片是一样大小
conv2d
官方学习文档conv2d链接Conv2d — PyTorch 2.3 documentation
参数
-
in_channels (int) – 输入图片通道数,彩色图片一般是三个通道
-
out_channels (int) – 卷积后输出通道数
-
padding_mode (str, optional) –填充的方式
'zeros','reflect','replicate'or'circular'. Default:'zeros' -
groups (int, optional) – 一般为1
-
bias (bool, optional) – 偏置
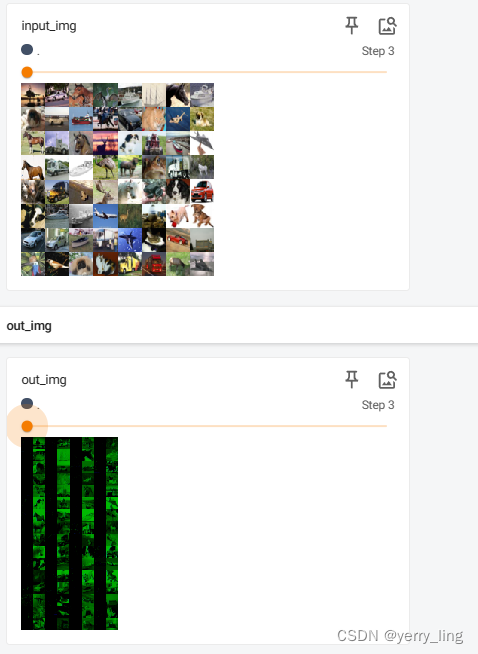
这里使用了上次是测试集数据,因为是图片RGB 3通道。进行两次卷积的话就会是6通道(3通道*2),输出得再次转换成3通道,不然会报错。
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=64)
class Test(nn.Module):
def __init__(self):
super(Test, self).__init__()
self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
def forward(self,x):
x = self.conv1(x)
return x
test = Test()
step =0
writer = SummaryWriter("dataloader")
for data in dataloader:
imgs,targets = data
output = test(imgs)
writer.add_images("input_img",imgs,step)
#这里要变成和输入一样的3通道 torch.Size([64,6,32,32])->[xxx,3,30,30]
#-1是占位符 表示让Pytorch自动计算维度大小
output= torch.reshape(output,(-1,3,30,30))
writer.add_images("out_img",output,step)
step = step+1
writer.close()控制台输入
tensorboard --logdir="dataloader"
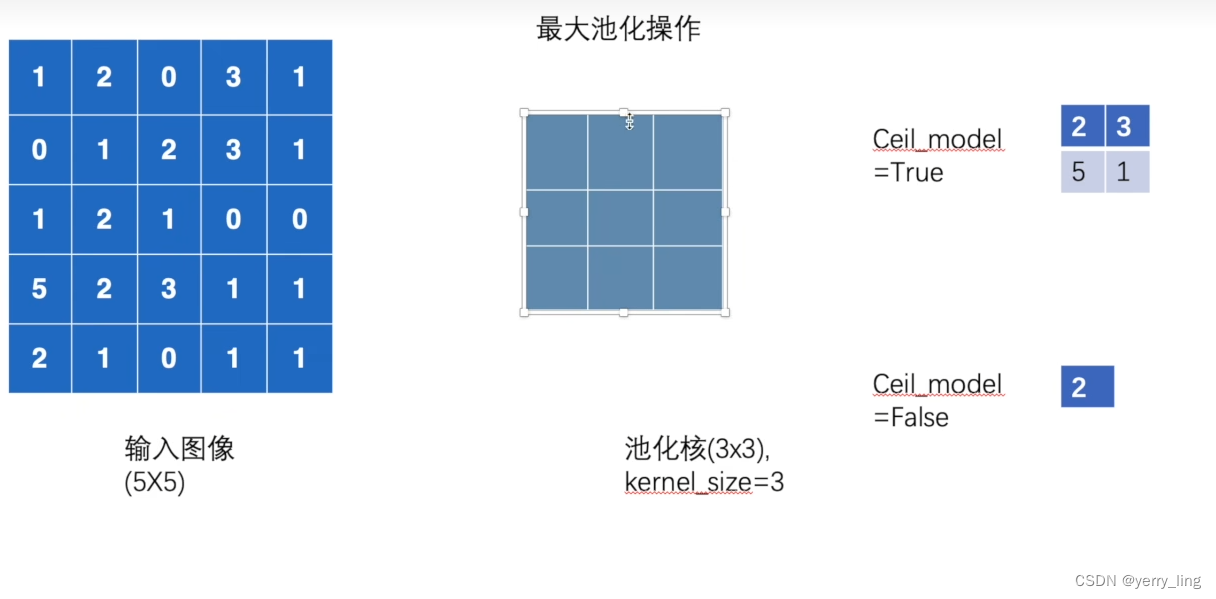
最大池化
池化核在输入图像中找出最大值,步长=kernel_size
ceil_model=False 在边框外直接省略,反之照取最大值作为输出
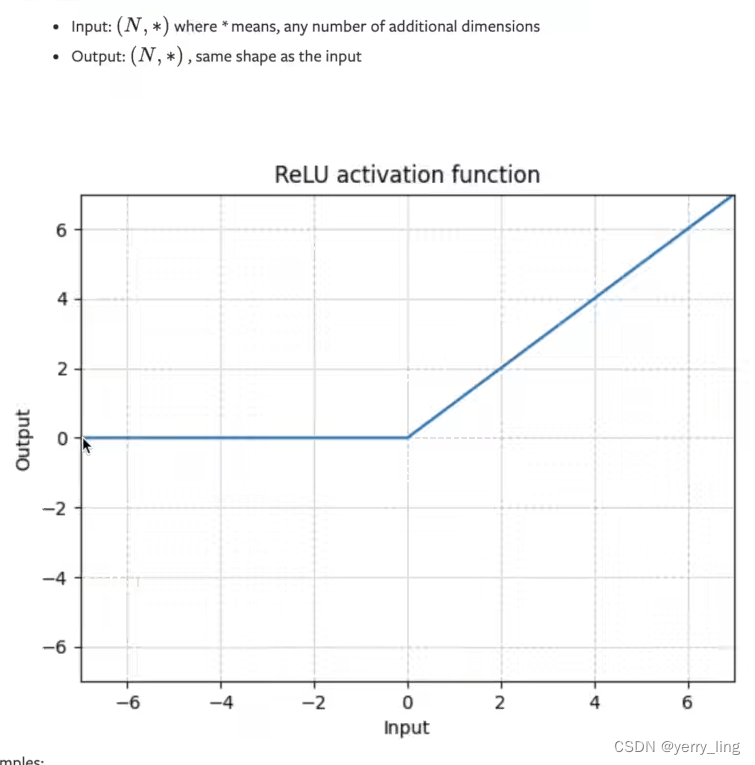
非线性激活
relu当输入小于0截断
原位操作
如果true是input值改变,如果false是多了一个output值输出

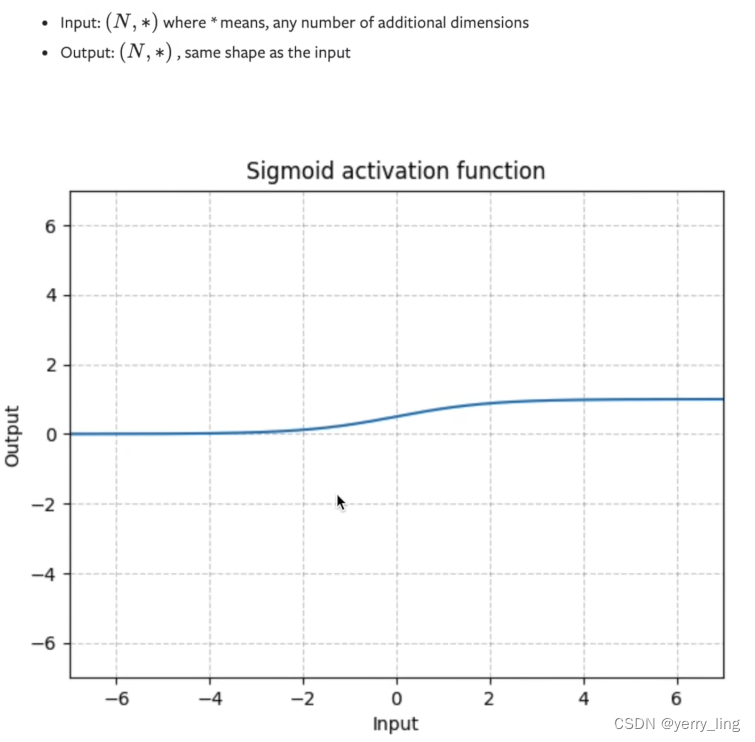
Sigmoid例子
import torch
import torchvision.datasets
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# input =torch.tensor([[1,-0.5],
# [-1,3]])
# #-1自动匹配bathsize 1通道 2*2
# output = torch.reshape(input,(-1,1,2,2))
# print(input.shape)
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=64)
class Test(nn.Module):
def __init__(self):
super(Test, self).__init__()
self.relu1 = ReLU()
self.sigmoid = Sigmoid()
def forward(self,input):
# output = self.relu1(input)
output = self.sigmoid(input)
return output
test = Test()
writer = SummaryWriter("dataloader")
step = 0
for data in dataloader:
imgs, tagets = data
output = test(imgs)
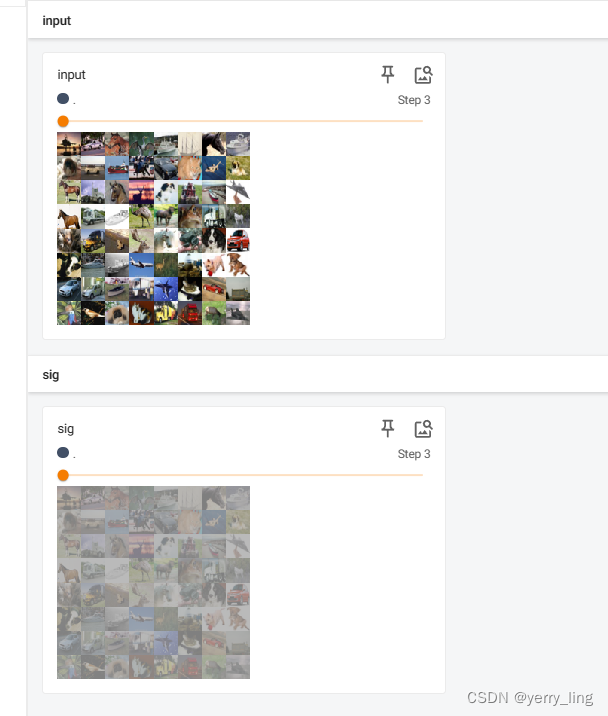
writer.add_images("input",imgs,step)
writer.add_images("sig",output,step)
step = step+1
# output = test(input)
# print(output)
writer.close()删除之前dataloader的数据
运行tensorboard --logdir="dataloader"
flatten展开操作

import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=64)
class Test(nn.Module):
def __init__(self):
super(Test, self).__init__()
#这里outf设置为10
self.linear1 = Linear(196608,10)
def forward(self,input):
output = self.linear1(input)
return output
test = Test()
for data in dataloader:
imgs,targets = data
print(imgs.shape)
#宽度自动定义
# output = torch.reshape(imgs,(1,1,1,-1))
output = torch.flatten(imgs)
print(output.shape)
output = test(output)
print(output.shape)
Sequential
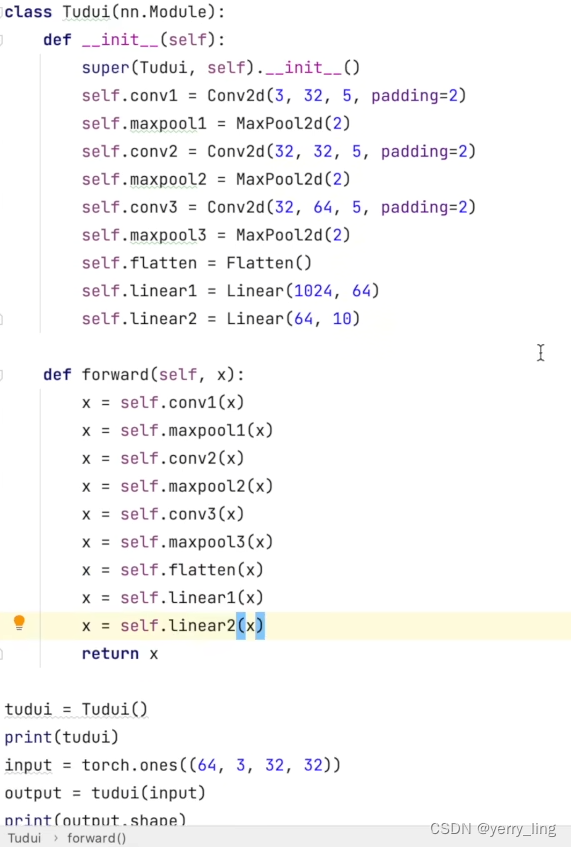
复现以下网络模型
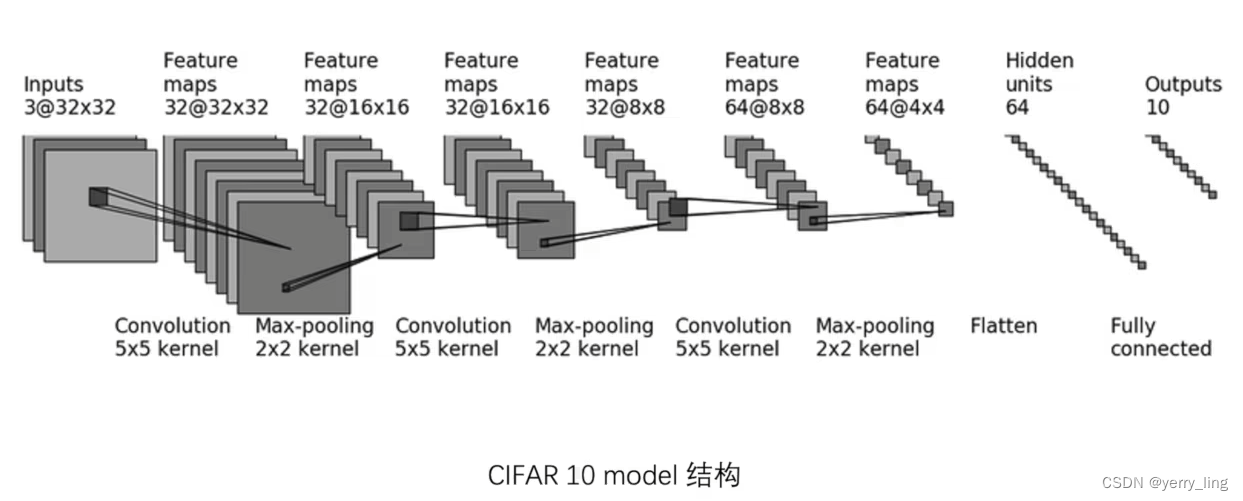
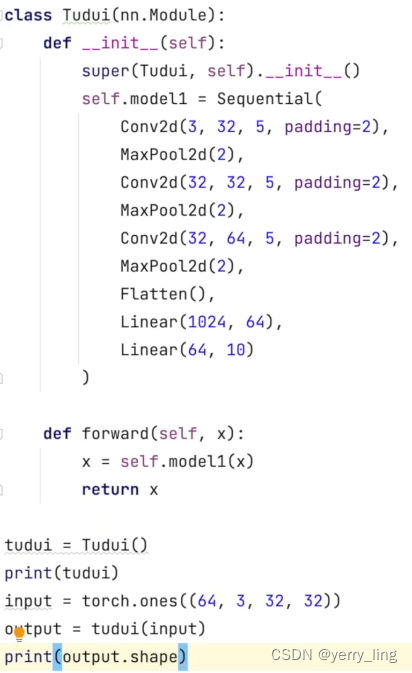
如果用Sequential则能减少代码如下:















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









