







这个专栏主要在于分享代码以及教大家如何使用具体原理部分后期慢慢补上来
先上一下 处理完结果的图片

先放一张原始光谱的图像
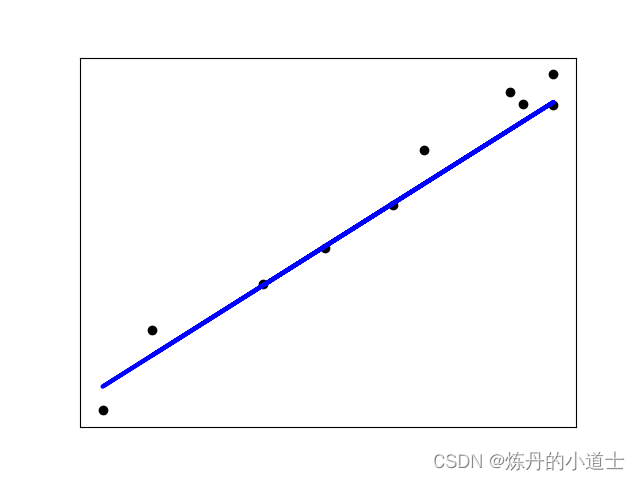
这个是进行线性回归的图形

这个是对线性回归的评价指标 MSE 和 R2
对于需要使用RMSE的同学 也可以直接求或者对MSE进行一个开方
现在介绍一下 我们使用的数据DATA的 分布情况

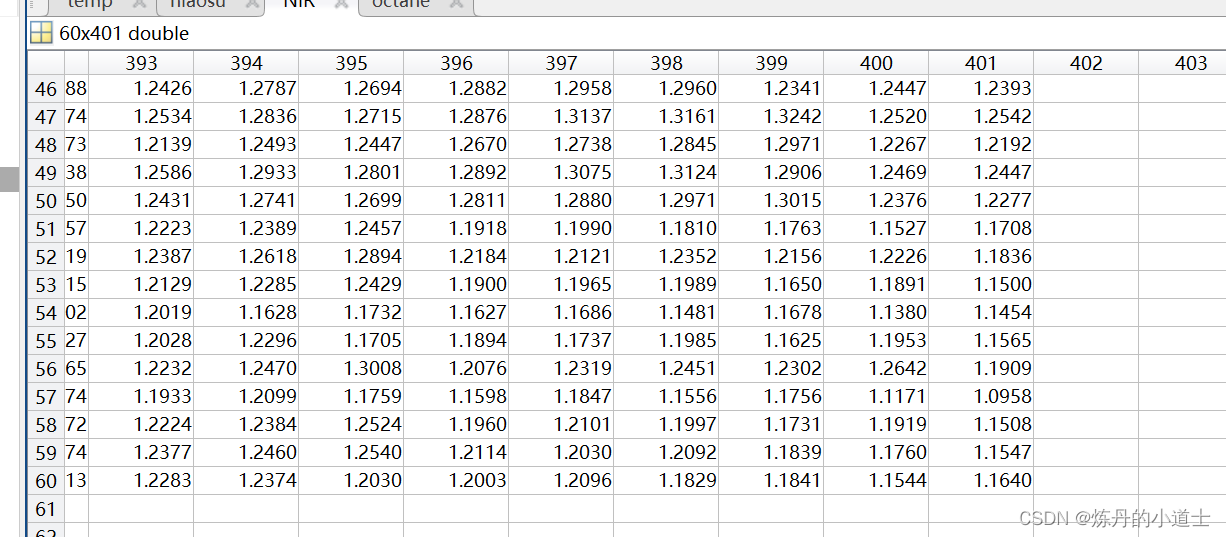
可以看到 data 是 60401
label 是601
一份比较简单的甲烷数据 900-1702nn 的波段 每隔2nn 取一个点
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
from sklearn import preprocessing
import scipy.io as sio #读取mat 文件
# 导入数据集
file = 'spectra_data.mat'
data = sio.loadmat(file)
X = data['NIR'] # 401 波段 60个样本
Y = data['octane']
print(X.shape)
print(Y.shape)
# 绘制原始光谱图
plt.figure()
plt.plot(np.arange(900, 1702, 2), np.transpose(X))
plt.xlabel('Wavelength(nm)')
plt.ylabel('Absorption')
plt.title('NIR spectrum of 60 gasoline samples')
plt.show()
# 划分训练集、验证集与测试集
k = np.random.permutation(X.shape[0]) #随机打乱顺序
print(k)
# 训练集
X_train = X[k[:50], :] # 前50
Y_train = Y[k[:50], :] #用x_train 带入模型的y_train_pred 跟 y_train 得出的是训练集
# 测试集
X_test = X[k[50:], :] #用x_test 带入模型的y_pred 跟 y_test 得出的是测试集
Y_test = Y[k[50:], :]
# 归一化
mms = preprocessing.MinMaxScaler()
X_train = mms.fit_transform(X_train) # [50, 100] ---> [0, 1]
# mms = preprocessing.MinMaxScaler()
# X_test = mms.fit_transform(X_test) # [20, 120] ---> [0, 1]
X_test = mms.transform(X_test)
Y_train = mms.fit_transform(Y_train)
print(X_train.shape)
print(Y_train.shape)
print(X_test.shape)
print(Y_test.shape)
# Create linear regression object
regr = linear_model.LinearRegression()
# regr = linear_model.LinearRegression(positive=True) #限定系数都是大于0 的
# Train the model using the training sets
regr.fit(X_train, Y_train)
# Make predictions using the testing set
y_pred = regr.predict(X_test)
Y_pred = mms.inverse_transform(y_pred.reshape(10, 1)) # 反归一化
# The coefficients
print("Coefficients: \n", regr.coef_)
# The mean squared error
print("Mean squared error: %.2f" % mean_squared_error(Y_test, Y_pred))
# The coefficient of determination: 1 is perfect prediction
print("Coefficient of determination: %.2f" % r2_score(Y_test, Y_pred)) # 决定系数
# Plot outputs
plt.scatter(Y_test, Y_pred, color="black")
plt.plot(Y_test, Y_test, color="blue", linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()
什么是线性回归?
要说线性回归,首先要理解机器学习及机器学习背后的统计学是基于什么样的假设,试图解决什么问题
在二十世纪二十年代以前,科学家基于传统牛顿力学、相对论等理论的成功,认为世界是由因果规律支配的,一切事物都严格遵守因果律和自然法则。也就是苹果会掉下来是因为有力在拉它,太阳在转也是因为有力在拉它。推导到最后就发现世界必须有一个源头提供原始的力,最终侧面证明了上帝的存在
二十世纪二十年代,开创量子力学的哥本哈根学派科学家波尔、海森伯认则为认为世界上一切事物的发生都是不确定的,只能用概率也就是发生的可能性来描述事物运动规律。也就是说世间一切的事儿都符合于某种概率分布而不是因果,可以用概率模型来表示一切规律
机器学习就是希望通过历史数据来找到事物背后的模式(pattern),而线性模型就是描述事物背后规律的一种方法,同时大部分的问题也是可以用线性模型来表示的















 461
461











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









