







机器学习模型评估策略及相关术语
目录
1.模型评估
1.1 训练集和测试集
- 我们将数据输入到模型中训练出了对应模型,但是模型的效果好不好呢?我们需要对模型的好坏进行评估
- 我们将用来训练模型的数据称为训练集,将用来测试模型好坏的集合称为测试集。
- 训练集:输入到模型中对模型进行训练的数据集合。
- 测试集:模型训练完成后测试训练效果的数据集合。
1.2 损失函数
-
损失函数用来衡量模型预测误差的大小。
-
定义:选取模型 f 为决策函数,对于给定的输入参数 X,f(X) 为预测结果, Y 为真实结果;f(X) 和 Y 之间可能会有偏差,我们就用一个损失函数(loss function)来度量预测偏差的程度,记作 L(Y,f(X))
-
损失函数是系数的函数
-
损失函数值越小,模型就越好
0 – 1 损失函数
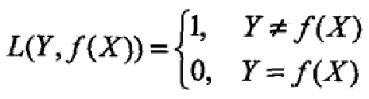
平方损失函数
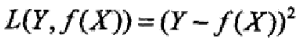
绝对损失函数
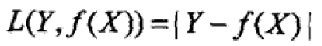
**对数损失函数**
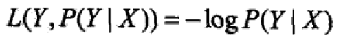
1.3 训练误差和测试误差
训练误差
-
训练误差(training error)是关于训练集的平均损失。
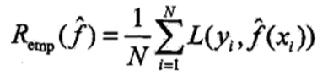
-
训练误差的大小,可以用来判断给定问题是否容易学习,但本质上并不重要
测试误差
-
测试误差(testing error)是关于测试集的平均损失。
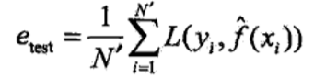
-
测试误差真正反映了模型对未知数据的预测能力,这种能力一般被称为 泛化能力
1.4 过拟合和欠拟合
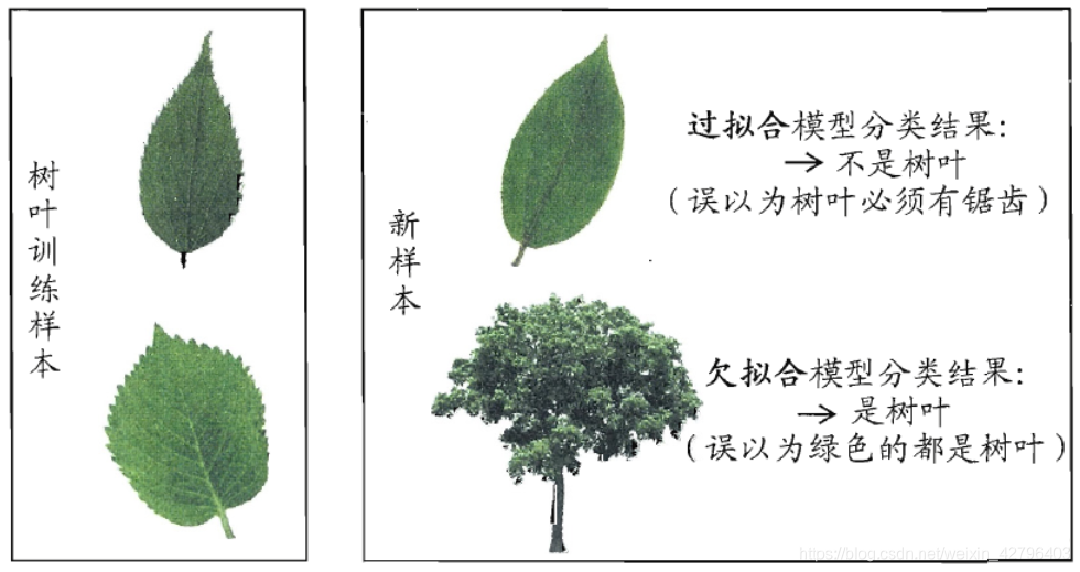
- 模型没有很好地捕捉到数据特征,特征集过小,导致模型不能很好地拟合数据,称之为欠拟合(under-fitting)。 欠拟合的本质是对数据的特征“学习”得不够
- 训练数据学习的太彻底,以至于把噪声数据的特征也学习到了,特征集过大,这样就会导致在后期测试的时候不能够很好地识别数据,即不能正确的分类,模型泛化能力太差,称之为过拟合(over-fitting)。
2.模型选择
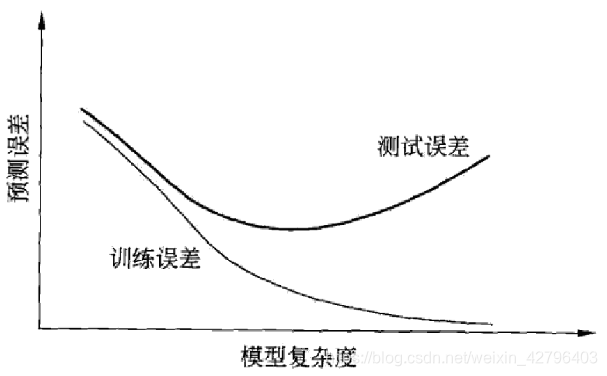
- 当模型复杂度增大时,训练误差会逐渐减小并趋向于0;而测试误差会先减小,达到最小值之后再增大
- 当模型复杂度过大时,就会发生过拟合;所以模型复杂度应适当
2.1 正则化
结构风险最小化(Structural Risk Minimization,SRM)
- 是在 ERM 基础上,为了防止过拟合而提出来的策略
- 在经验风险上加上表示模型复杂度的正则化项(regularizer),或者叫惩罚项
- 正则化项一般是模型复杂度的单调递增函数,即模型越复杂,正则化值越大
结构风险最小化的典型实现是正则化(regularization)
- 形式:
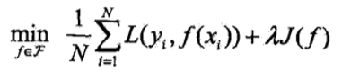
- 第一项是经验风险,第二项 J (f ) 是正则化项, 是调整两者关系的系数
- 正则化项可以取不同的形式,比如,特征向量的L1范数或L2范数
2.2 奥卡姆剃刀原则
- 奥卡姆剃刀(Occam‘s razor)原理:如无必要,勿增实体
- 正则化符合奥卡姆剃刀原理。它的思想是:在所有可能选择的模型中,我们应该选择能够很好地解释已知数据并且十分简单的模型
- 如果简单的模型已经够用,我们不应该一味地追求更小的训练误差,而把模型变得越来越复杂
3 交叉验证
3.1 数据集划分
- 如果样本数据充足,一种简单方法是随机将数据集切成三部分:训练集(training set)、验证集(validation set)和测试集(test set)
训练集用于训练模型,验证集用于模型选择,测试集用于学习方法评估
3.2 交叉验证
数据不充足时,可以重复地利用数据——交叉验证(cross validation)
简单交叉验证
- 数据随机分为两部分,如70%作为训练集,剩下30%作为测试集
- 训练集在不同的条件下(比如参数个数)训练模型,得到不同的模型
- 在测试集上评价各个模型的测试误差,选出最优模型
S折交叉验证
- 将数据随机切分为S个互不相交、相同大小的子集;S-1个做训练集,剩下一个做测试集
- 重复进行训练集、测试集的选取,有S种可能的选择
留一交叉验证














 413
413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









