







Fully Convolutional Geometric Features
一.四个问题
1.要解决什么问题?
从三维扫描或点云中提取几何特征是配准、重建和跟踪等应用中的第一步。现有的基于学习的特征提取算法基于兴趣点所在表面及临近点的空间分布,提取基本的二维、三维几何属性作为兴趣点特征信息,如角偏差,法线,点分布等,并通过多层感知器或三维卷积映射到一个低维特征空间。这种特征提取算法复杂度低、运算效率高、内存消耗少,但领域尺寸的选择对识别效果影响较大。这就产生了几个问题:
- 所有先前的方法都需要提取一个小的三维patch,或者一系列点,然后将其映射到低维特征空间,这不但限制了网络的感受野,也使得计算效率很低。甚至是在有重叠的三维区域上,所有中间的表示都需要分别计算。
- 使用了昂贵的低阶几何特征作为输入,会降低特征计算的速度。
- 只对一些interest points提取特征,导致分辨率(点的数量)下降,因此降低了后续的配准精度。
2.用什么方法解决?
基于上述问题,作者提出了应用全卷积网络来解决。因为全卷积网络有三个特点:
- 因为中间激活结果可以在感受野有重叠的神经元上共享,所以全卷积网络效率很高,计算速度快。
- 因为其不再被限制在分别提取和处理过的patch上,所以全卷积网络中的神经元有着更加广阔的感受野。
- 全卷积网络的输出是稠密的。非常适合需要对场景进行详细描述的任务。
3.效果如何?
FCGF在室内室外数据集上均进行了测试,可以达到state-of-art的性能表现,比最快的快9倍,比最好的快290倍。
4.问题?
因为在全卷积特征的提取过程中,相邻特征的位置是相关的,所以一个batch内特征是独立同分布的假设不再成立。
这也就决定了,后面的度量损失也要重新设计。相应的,作者也提出了新的loss function。(在后面会具体介绍新的loss function,但,可以看到新loss function与传统的hardest对比损失差别不大,是否能真的解决特征不再服从独立同分布假设存疑)
- 论文概述
2.1 Sparse Tensors and Convolutions
这里作者定义了一个稀疏张量卷积。首先,最主要的卷积操作其实是参考了Minkowski 卷积。其次,作者提出稀疏张量,也主要是因为所采集的点云数据主要是通过对物体表面进行三维扫描,所以点云数据本身具有一定的稀疏性质。具体来看:
稀疏张量:一个sparse tensor可以用一个矩阵Matrix去表示其坐标,另一个矩阵向量代表其特征。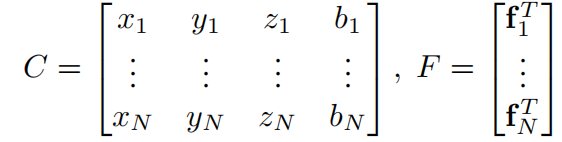
卷积:这里参考的是Minkowski卷积
![]()
这里可以看出,其实还是一个加权求和的卷积操作。可以从这里看出:![]() ,i代表的是一个三维意义上的偏移量。x(u+i)对应的也就代表的是x(u)的邻点。也就是说,当我们想要在u点处卷积时,其实还是对u的邻点进行一个加权和。
,i代表的是一个三维意义上的偏移量。x(u+i)对应的也就代表的是x(u)的邻点。也就是说,当我们想要在u点处卷积时,其实还是对u的邻点进行一个加权和。
2.2 Sparse fully-convolutional features.
全卷积网络纯粹由平移不变操作构成,例如卷积操作和基于元素的非线性操作。相似的,如果我们对一个稀疏张量应用一个稀疏的卷积网络,我们会得到一个稀疏的输出张量。我们将这个输出的张量叫做"fully convolutional features"。作者使用一个带有skip connection和残差模块的UNet架构去提取fully convolutional features. 其架构如下图:
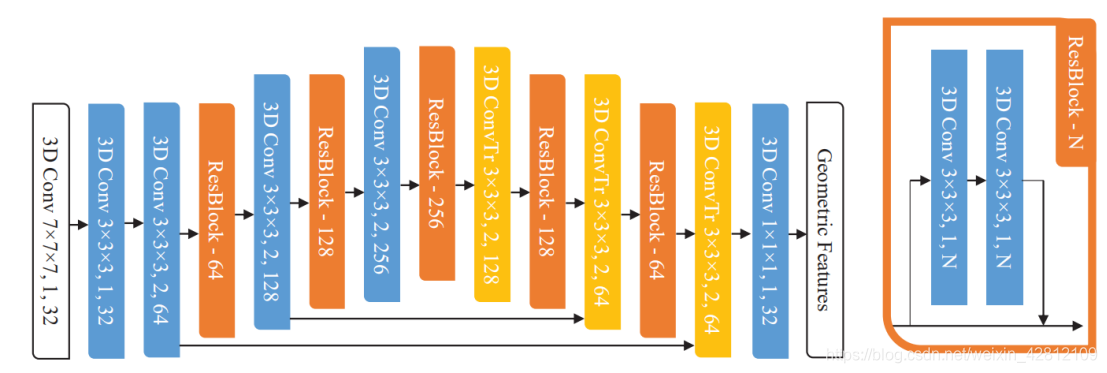
可以看到,这是一个ResUNet的架构,其中白色块代表着输入和输出层,每个block都由三个参数指定: kernel size, stride, channel dimensionality。所有的卷积操作(除了最后一层)后都应用了一个batch norm和一个ReLU。具体来说:
- 残差结构: Res = [(Conv + Bn + ReLU) + (Conv + Bn)], Output = ReLU(input + Res(input)),其中的Conv, Bn, ReLU操作均为稀疏数据的卷积,即Minkowski下的卷积操作。
- 编码: 包括N(Figure2中N=3)个(Conv + Bn + Res)结构,kernel size一般设置为3,第一个Conv中的stride=1,其他Conv的stride一般设置为2。
- 解码: 包括N(数量同编码部分)个(transposed Conv + Bn + Res)结构,除了第一个transposed Conv结构外,其他transposed Conv结构的输入均是encoder和decoder进行concat后的tensor。同时,最后一个transposed Conv中的kernel size为1,stride为1,其它的transposed Conv中的kernel size均为3,stride均为2。
- 特征提取层: Conv(kernel size=1, stride=1),其后无Bn和ReLU结构。
2.3Loss function
2.3.1Fully-convolutional Metric Learning
传统的度量学习假定:特征feature是独立同分布的,因为batch是通过随机采样来构建的。然而,在全卷积特征提取中,相邻的feature之间是局部相关的。因此,难负例挖掘(hard-negative mining)会找到与锚点相邻的特征们,但是他们是假的负例。(难负例的定义是很难判别的负例,所以要再次送入网络进行学习。但是这里锚点相邻的特征是局部相关的,所以其在度量上接近是情有可原的,不是负例。) 所以,将假负例过滤掉是十分重要的,这里采用距离阈值进行过滤。
2.3.2New Losses
作者总共实现了4种不同的损失函数,分别是Contrastive Loss, Hardest-contrastive Loss, Triplet Loss和Hardest-triplet Loss。上述四种Loss主要基于一种思想: 如果(i,j)是positive pairs,则它们特征fi,fj间的距离应该满足D(fi,fj)−>0(为了防止过拟合,要求D(fi,fj)<mp即可);如果(i,j)是negative pairs,它们的特征fi,fj的距离D(fi,fj)应该满足D(fi,fj)>mn。mp和mn是positive pairs和negative pairs的margin。

- Contrastive Loss and Hardest-contrastive Loss
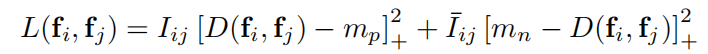
其中,(i,j)是positive pairs,则Iij= 1,否则Iij=0。positive pairs由3DMatch数据的G.T. correspondences获得,negative pairs随机产生,但过滤掉属于positive pairs的点对。如Figure 3所示,蓝色箭头连接的点表示positive pairs,橘色箭头连接的点表示negative pairs。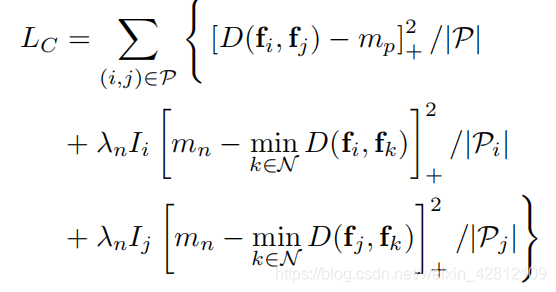
P是positive pairs的集合,![]() ,
,![]() ,
,![]() 。简单说,对于positive pairs,由数据集的G.T.获得;对于每一对positive pair(i,j),由i根据特征距离产生一对hard negative pairs,由j根据特征距离产生一对hard negative pairs,如Figure 3的第三个图所示,蓝色线连接的表示positive pairs,橘色线连接的是negative pairs。
。简单说,对于positive pairs,由数据集的G.T.获得;对于每一对positive pair(i,j),由i根据特征距离产生一对hard negative pairs,由j根据特征距离产生一对hard negative pairs,如Figure 3的第三个图所示,蓝色线连接的表示positive pairs,橘色线连接的是negative pairs。
2. Triplet Loss and Hardest-triplet Loss
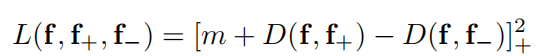
m是positive pairs和negative pairs之间的margin。对于三元组的随机采样是这样的: 对于positive pairs,由数据集的G.T.获得;对于每一对positive pair (i,j),随机产生一个k,若(i,k)是一个negative pair,则形成三元组(i,j,k),如Figure 3的第二个图所示,否则在训练中放弃此三元组。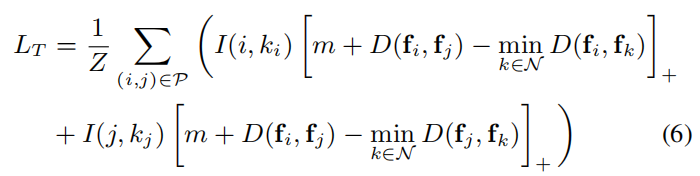
简单的说,positive pairs由G.T.获得,对于每一对positive pair(i,j),对点i从N2找到特征距离最小的点ki,若(i,ki)不属于positive pais,则构成三元组(i,j,ki),否则舍弃此无效三元组;对点j进行同样的操作,得到三元组(i,j,kj)。如Figure 3的第四个图所示,由一对positive pair(蓝色的圆)产生了两个三元组。
2.4Experiments
Fature-Match Recall and Time
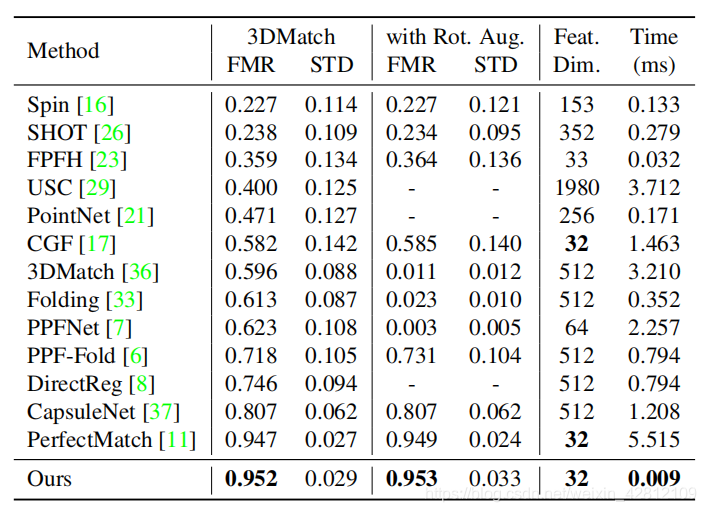
作者在3DMatch测试集中比较了FCGF与传统方法和深度学习方法的性能,第1列是方法名称,第2列是FMR值(及其标准差),第3列是在旋转的3DMatch数据集中的FMR值(及其标准差),第4列表示特征描述子的维度和提取特征的时间。从表中可以看到,FCGF提取特征的速度快,特征简洁(只有32维),在3DMatch数据集和旋转增强的3DMatch数据集均有最高的FMR。

















 1295
1295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









