







一.摘要
深度学习在三维点云中的应用由于缺乏顺序性而具有挑战性。受PointNet的点嵌入和dgcnn的边缘嵌入的启发,我们对点云分析任务提出了三个改进。首先,我们引入了一种新的特征关注神经网络层FAT层,它结合了全局点特征和局部边缘特征来生成更好的嵌入。其次,我们发现在两种不同形式的特征聚合(最大池和平均池)中应用相同的注意力机制,可以获得比单独使用任何一种更好的性能。第三,我们观察到残差特征重用在此设置下更有效地在层间传播信息,使网络更容易训练。我们的体系结构在点云分类任务上取得了最先进的结果,如在ModelNet40数据集上所示,并在ShapeNet部分分割挑战上具有极具竞争力的性能。
二.论文创新点
1)提出了一种新的注意力注入层,即FAT层,用于3D点云处理,该层通过非线性加权优化结合了全局基于点的嵌入和局部基于边的嵌入。
2)对两种不同的特征聚合方法应用加权,这比单独聚合更好。
3)首次通过残差连接增强了处理三维点云的网络学习,并通过共享权重MLPs对嵌入维数进行提升。
4)一项广泛的评估显示了ModelNet40分类任务的最新结果,在ShapeNet零件分割任务上的高度竞争结果,以及对随机输入点丢失的卓越鲁棒性。消融研究证实了我们的网络组成部分的有效性。
三.网络结构
1.总体架构

网络概览:
(1)输入点云首先进入一个transformer net回归出一个3*3的加权参数阵,然后对原点云进行加权后输入接下来的一系列fat layer
(2)在fat layer之间进行残差传播时,传统映射方法不再适用(why),本文采用共享权重的MLP来进行残差
(3)在经过一系列fat layer特征提取后,将前几层特征与最后一层特征做了一个cat,然后进行aggregation,采用一个新颖的FatNet aggregation得到一个1024维的特征向量。
1.1FAT Transformer Net
fat transformer net可以看作时整个fat net的一个迷你版本
首先是3个没有attention机制的fat layers(64,128,1024),然后aggregation。然后将得到的特征向量输入mlp(512,256)。最后回归得到33的转换矩阵,将33的转换矩阵与点云相乘。
1.2The Feature-attentive Layer (FAT layer)

图层中的信息通过跳跃连接传播到下一层,跳跃连接可以通过共享权重的MLP结构调整上一层的嵌入的尺寸。每个FAT layer计算单独的点和边嵌入,并使用特征注意机制重新加权。我们将加权后的点和边特征连接起来,并将它们传递到下一层。

点嵌入操作对应于使用共享权重MLP(conv1D)的点网络样式特征提取,而边嵌入是通过类似DGCNN的架构实现的。我们使用了一个如图所示的特征注意块,计算每个单独的特征嵌入的注意权重。在特征嵌入块中,我们使用一个具有两个密集层的共享权值编码器-解码器来学习每个点/边缘特征的注意权值。输入嵌入首先maxpooling得到特征向量,然后它们被送到编码器解码器。瓶颈处,通过一定压缩比压缩输入(使用8)。然后将瓶颈表示上采样回原始维度并传递至sigmoid激活函数层,以获得其对应的注意力权重
1.3Global Feature Aggregation (GFA) Block

平均池和最大池操作通过共享权重编码解码器(压缩比=16),然后是符号门控,以给予两个池的注意权重。缩放的输出被加在一起,以提供我们的全局特征聚合(GFA)块。
现有的点云处理架构将点嵌入到更高维特征空间中,并随后进行最大池全局特征聚合。考虑到嵌入中存在的所有信息都被合并到这个全局聚合中,它当然需要进一步研究,看看是否可以对通过conv1D操作提取的信息创建更好的编码。自PointNet提出以来,之前还没有做过任何工作来研究或修改这一全局特征聚合。PointNet的一个贡献表明,最大池聚合优于平均池。然而,这绝不表明平均汇集特征不能贡献整个网络性能。
为此,本文建议采用平均池特征和最大池特征,并学习注意力权重来调整它们对输出的影响。我们从1024维的特征层中提取最后的特征嵌入,同时提取最大池和平均池,得到两个向量表示。这些表示都被送到一个类似于之前的共享加权解码器-解码器中,压缩比为16。其输出通过一个gating以获得两个聚合的权重。然后,这些权重缩放它们各自的池操作的输出,然后被加在一起。在训练中,网络学会了从这两种特征聚合技术中适当地加权聚合特征。实验证明,这比单独最大池更好的结果。我们的全局特征聚合(GFA)块如图所示。
1.4Loss Formulation
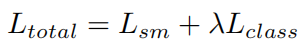
1.4.1Node-wise supervision
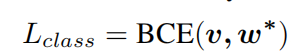
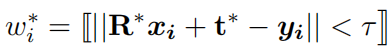
1.4.2Edge-wise supervision
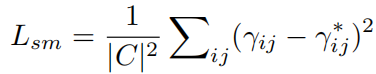















 544
544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









