







废话综述
yolov1是yolo系列的开山之作,它是一个无anchor框的检测模型,也是将目标检测任务变成一个回归任务来处理的。看yolo系列一定要从v1开始看,慢慢看每个系列的改进,理解其精髓才能有比较大的提升。yolov1等于将每个图片分成7 * 7的区域,最后的输出张量每个张量“负责”图片中的每个区域的检测,但是一定要注意每个张量负责的区域会比图片分割后的格子要稍大一些,而且每个1 * 1张量的感受野是整张图片的信息(因为进过了一个全连接层)。这个网络一定要好好理解它回归处理目标检测这个思想,把重点放在最后的输出和损失函数上面。
一、Yolo v1算法框架原理

输入图像的大小为448 * 448,进过若干个卷积层和池化层,变为一个7 * 7 * 1024的张量。(里面卷积层,特征图和通道数看不懂的话说明基础还不够扎实)然后经过两个全连接层(这里以后的版本会进行改变,因为参数计算量太大了全连接层),*得到一个7 * 7 30的张量。这里跟普通的卷积网络没什么很大区别,最巧妙的地方在它的输出,这个7 * 7 * 30的张量。这个7 * 7代表就把原始图像按照7 * 7分割成一个个小格子,每个小格子“负责”一个区域,一定要注意这每个小格子“负责”区域的感受野是整张图片,因为全连接层的训练(前向传播和反向传播根据损失函数更新参数,这是回归问题理解起来的重点)让每个小格子注重的区域不同,从而达到的效果。
最后这个30维度的张量,代表的就是20个分类和两个bounding box的5个参数(x,y,w,h,confidence)。注意这里每个每个格子都会产生2个bbox(作者设定的,可以更改),所以会产生98(7 * 7 * 2)个bbox放入损失函数进行回归训练,但是不是每个每个bbox都会参与到损失函数的计算,这里后面会讲,这是理解上面的重点!!!
这个网络结构借鉴了GoogleNet的网络结构,24个卷积层,2个全连接层。
整体流程

整体流程就是把图片变为7 * 7的小格子,每个小格子都输出98个bbox放入损失函数进行回归计算,然后真实标签中的中心点落在了哪个格子内,这个格子就负责预测这个物体的bbox。在yolov1中一个格子只能负责预测一个物体,所以整个网络最多可以预测49种物体(这样存在很大的网络局限性,后面的版本会对这里进行提升改进)。然后可能有多个格子都包含这个真实标签的中心点(因为格子的感受野),所以可能有多个同类别的预测框。通过nms(非极大值抑制)输出最终的同个类别的一个框,就是网络预测的结果。
30维里的置信度的计算
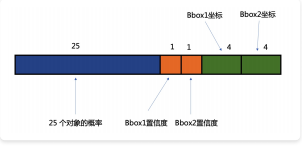
这里蓝色那里是20个对象的概率!
bbox置信度的计算公式:
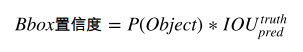
P(Object)表示是否存在待检对象。在训练阶段,如果这个像素点的“负责”的区域没没有gd,则P(Object) = 0,反之为1。然后就是计算gd和pd的IOU的值。
Bbox 置信度表达了这个像素点对应的“负责”区域有没有,且 Bbox 准不准的程度。反应了 Bbox的准确性程度。
要注意,Bbox置信度虽然有多个,(⼀个像素点对应的负责区域会有多个 Bbox,⽐如这⾥是2个)。但我们只看和 GroudTruth IOU ⼤的那个,另外⼀个⾃动设定为 0 。
Bbox 置信度的⼤⼩期望在 [0,1] 之间。
为什么我们需要两个 Bbox 来进⾏预测呢?
在训练时,我们希望两个框同时⼯作,但真正计算损失的时候,我们只去对 IOU 最⼤的框进⾏梯度下降和修正。类似于⼀个相同的⼯作,让两个⼈⼀起做,为了保障⼯作正常完成。在训练最后,会发现两个框意⻅开始出现了分⼯,⽐如⼀个框倾向于去检测细⻓型的物体。另⼀个框倾向于去检测扁宽型的物体。
总结⼀下就是,在训练阶段,输出的两个 Bbox 只会选择其中⼀个参与损失的计算(和 gd IOU⼤的那个)。
在测试阶段,输出的两个 Bbox 只有⼀个有实际预测的意义。
通过前⾯讲解,可以看到 YoloV1 ⾄多只能预测 49 个⽬标,即每个“负责”区域输出⼀个⽬标。
注意!我们可以使⽤不⽌ 2 个 Bbox,理论上 Bbox 越多效果越好,但是效率会降低。作者取两个Bbox 的原因是因为性能和效率的取舍。
30维里bbox的坐标
这里会先对gt框的中心点做一个归一化的操作(网格里包含中心点才做的),这个操作个人觉得比较蠢,后面的v2,v3版本都舍弃了这种做法。假设grid中的左上角的坐标值为Lx,Ly,中心点的坐标是Gx,Gy,grid的宽为w,高为h。归一化后的x就是:(Gx-Lx)/w,归一化后的y就是:(Gy-Ly)/h。用这种方式强行的对坐标进行编码。
具体对象的概率
具体对象的概率公式:
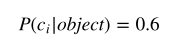
表示这个像素点“负责“原始图像的区域“存在”对应对象的概率。注意,这⾥的前提是该⽹格中存在待检测的对象。每⼀个值的⼤⼩期望在 [0,1] 之间。
如何定义前⾯说的“存在”对应对象呢?如果原始图像的待检⽬标的 bbox 的中⼼点在对应的“负责”区域内。则表示存在对应对象。

损失函数(最重要的部分)
损失函数这里我们需要关心两个部分,一个是损失函数的输入,也就是标签值(gd)和预测值(pd)。⼆是损失函数的具体形式。
损失函数的输入
这里的置信度标签是动态变化的,因为我们之前说了每个grid会有两个bbox,只需要置信度大的那个参与到损失函数置信度的计算中。这样能让网络更加注重于大的IOU的置信度的框的学习,让它更加接近于真实标签中的gt,也就是更加接近于1这个值。
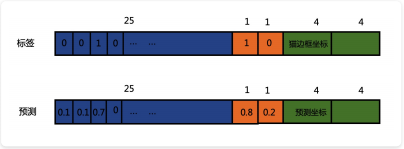
总的损失函数由四部分构成,第一部分是边框中心点误差和边框宽度和高度的误差,第二部分是置信度误差(框内有对象),第三部分是置信度的误差(边框内无对象),第四部分是对象分类误差。

为什么要有两个不同的部分来进行置信度误差的拟合呢(这是我学习时候一个疑问)?
因为我们需要让边框内有对象的时候,让这个置信度尽可能的接近1。在边框内没有对象时,让这个置信度尽可能的接近于0。这样让网络对正负样本都能进行很好的学习。但是在这个过程中,正例样本远远小于负例样本,所以为了平衡,会在负例置信度的计算前面加上一个调节权重的参数,参数设定为0.5。让网络更加注重于正例样本的学习。

然后我们想让网络更加注重于边框中心点和宽度高度的误差,毕竟是一个目标检测任务嘛,所以在这两部分的损失函数前面都添加了一个调节权重的参数,参数设定为5。
损失函数的x,y,w,h都是经过上面说的编码过程,强行将它们的值归一化到0到1之间。这里的w,h开根号是为了降低w,h对损失函数的敏感度,因为w和h有时的值会偏大或者偏小。

测试阶段
在测试阶段,是将bbox的置信度和对象概率相乘,得到存在类别对应目标的概率:
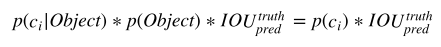
对每⼀个⽹格的每⼀个 bbox 执⾏同样操作: 7x7x2 = 98 bbox (每个bbox既有对应的class信息⼜有坐标信息)
得到 98 个 bbox 的信息后,⽤ NMS 算法去掉重复率较⼤的 bounding box 。
注意,在测试阶段需要将 dropout 也开启为测试模式。(如果有 BatchNorm 需要将 BatchNorm也开启为测试模式,原始论⽂中没有 BatchNorm 层)。
总结
yolo v1算法的结构相对还是比较简单的,但是里面的缺陷也是由很多的,比如网络结构的缺陷(提取特征网络不够深,全连接里面参数太多了);对小目标和靠得很近的目标检测起来不准确(每个grid只输出一个类别,如果很多物体的中心点都在这个grid中,网络就很无奈);处理x,y,w,h的编码方式太蠢了等等。后面yolo v2,v3,v4基本都解决这些问题,让网络的精度和速度得到很高的提升。
如果我的博客中存在什么理解上的问题请及时提出,互相学习的过程!















 553
553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









