







k-近邻(KNN)
在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类。
步骤:
- 准备数据,对数据进行预处理
- 选用合适的数据结构存储训练数据和测试元组
- 设定参数,如 k维护一个大小为k的的按距离由大到小的优先级队列,用于存储最近邻训练元组。随机从训练元组中选取k个元组作为初始的最近邻元组,分别计算测试元组到这k个元组的距离,将训练元组标号和距离存入优先级队列遍历训练元组集,计算当前训练元组与测试元组的距离,将所得距离L 与优先级队列中的最大距离Lmax进行比较。若 L >=Lmax,则舍弃该元组,遍历下一个元组。若L < Lmax,删除优先级队列中最大距离的元组,将当前训练元组存入优先级队列。
- 遍历完毕,计算优先级队列中k 个元组的多数类,并将其作为测试元组的类别。
- 测试元组集测试完毕后计算误差率,继续设定不同的k值重新进行训练,最后取误差率最小的k 值。
在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离:

API:
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier(n_neighbors=5,algorithm='auto') //实例化估计器
knn.fit(data) # 传入参数
y_predict=knn.predict(x_test) # 得出预测值
knn.score(x_test,y_test) # 得出准确率
n_neighbors:查询默认使用的邻居数
algothrim:{auto,ball_tree,kd_tree} auto会根据传递给fit的方法的值来决定算法
k值选取
对于k值的选择,没有一个固定的经验,一般根据样本的分布,选择一个较小的值,可以通过交叉验证选择一个合适的k值。
选择较小的k值,就相当于用较小的邻域中的训练实例进行预测,训练误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是泛化误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合。
选择较大的k值,就相当于用较大邻域中的训练实例进行预测,其优点是可以减少泛化误差,但缺点是训练误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
一个极端是k等于样本数m,则完全没有分类,此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的类,模型过于简单。
优点:简单易懂
缺点:时间复杂度高,内存开销大
朴素贝叶斯
朴素说的是特征相互独立
贝叶斯方法是以贝叶斯原理为基础,使用概率统计的知识对样本数据集进行分类。由于其有着坚实的数学基础,贝叶斯分类算法的误判率是很低的。贝叶斯方法的特点是结合先验概率和后验概率,即避免了只使用先验概率的主观偏见,也避免了单独使用样本信息的过拟合现象。贝叶斯分类算法在数据集较大的情况下表现出较高的准确率,同时算法本身也比较简单。
贝叶斯公式:
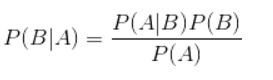
换个表达形式就会明朗很多,如下:
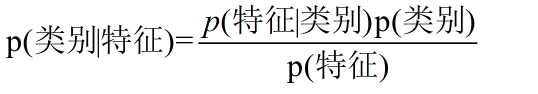
拉普拉斯平滑系数
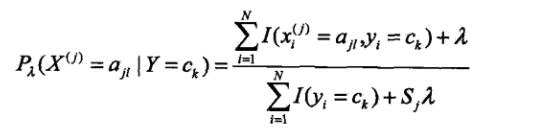
其中ajl,代表第j个特征的第l个选择,[公式]代表第j个特征的个数,K代表种类的个数。
λ为1,这也很好理解,加入拉普拉斯平滑之后,避免了出现概率为0的情况,又保证了每个值都在0到1的范围内,又保证了最终和为1的概率性质!
API:
from sklearn.naive_bayes import Multional(alpha=1.0) #alpha为拉普拉斯平滑系数
优点
朴素贝叶斯算法假设了数据集属性之间是相互独立的,因此算法的逻辑性十分简单,并且算法较为稳定,当数据呈现不同的特点时,朴素贝叶斯的分类性能不会有太大的差异。换句话说就是朴素贝叶斯算法的健壮性比较好,对于不同类型的数据集不会呈现出太大的差异性。当数据集属性之间的关系相对比较独立时,朴素贝叶斯分类算法会有较好的效果。
缺点
属性独立性的条件同时也是朴素贝叶斯分类器的不足之处。数据集属性的独立性在很多情况下是很难满足的,因为数据集的属性之间往往都存在着相互关联,如果在分类过程中出现这种问题,会导致分类的效果大大降低。
决策树
决策树算法采用树形结构,使用层层推理来实现最终的分类。决策树由下面几种元素构成:
根节点:包含样本的全集
内部节点:对应特征属性测试
叶节点:代表决策的结果

预测时,在树的内部节点处用某一属性值进行判断,根据判断结果决定进入哪个分支节点,直到到达叶节点处,得到分类结果。
这是一种基于 if-then-else 规则的有监督学习算法,决策树的这些规则通过训练得到,而不是人工制定的。
决策树是最简单的机器学习算法,它易于实现,可解释性强,完全符合人类的直观思维,有着广泛的应用。
举个栗子:
上面的说法过于抽象,下面来看一个实际的例子。银行要用机器学习算法来确定是否给客户发放贷款,为此需要考察客户的年收入,是否有房产这两个指标。领导安排你实现这个算法,你想到了最简单的线性模型,很快就完成了这个任务。
首先判断客户的年收入指标。如果大于20万,可以贷款;否则继续判断。然后判断客户是否有房产。如果有房产,可以贷款;否则不能贷款。

信息熵:
信息熵越大,不确定性就越大
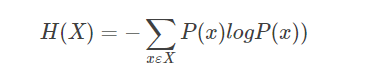
条件熵:
在x取值一定的情况下随机变量y不确定性的度量
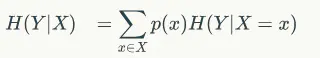
信息增益:
信息增益就是熵和特征条件熵的差
g(D,A)=H(D)-H(D|A)
什么意思呢,就是说对一个确定的数据集来说,H(D)是确定的,那H(D|A)在A特征一定的情况下,随机变量的不确定性越小,信息增益越大,这个特征的表现就越好
常见决策树算法:ID3、C4.5 CART
API:
from sklearn.tree import DecisionTreeClassifier(criterion='gini',max_depth=None,random_state=None)
决策树结构保存
sklearn.tree.export_graphviz(estimator,out_file='tree.dot',feature_names=[',']) #导出为DOT格式
优点
- 决策树易于理解和解释,可以可视化分析,容易提取出规则;
- 可以同时处理标称型和数值型数据;
- 比较适合处理有缺失属性的样本;
- 能够处理不相关的特征;
- 测试数据集时,运行速度比较快;
- 在相对短的时间内能够对大型数据源做出可行且效果良好的结果。
缺点
-
容易发生过拟合(随机森林可以很大程度上减少过拟合);
-
容易忽略数据集中属性的相互关联;
-
对于那些各类别样本数量不一致的数据,在决策树中,进行属性划分时,不同的判定准则会带来不同的属性选择倾向;信息增益准则对可取数目较多的属性有所偏好(典型代表ID3算法),而增益率准则(CART)则对可取数目较少的属性有所偏好,但CART进行属性划分时候不再简单地直接利用增益率尽心划分,而是采用一种启发式规则)(只要是使用了信息增益,都有这个缺点,如RF)。
-
ID3算法计算信息增益时结果偏向数值比较多的特征。
随机森林
随机森林是由很多决策树构成的,不同决策树之间没有关联。
当我们进行分类任务时,新的输入样本进入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么随机森林就会把这个结果当做最终的结果。
单个树建立过程:
- 随机在N个样本中选1个样本,重复n此(放回抽样)
- 随机从M个特征中选m个特征(随机放回抽样)
API:
from sklearn.ensemble import RandomForestClassifier
rfc=RandomForestClassifier()
优点
- 它可以出来很高维度(特征很多)的数据,并且不用降维,无需做特征选择
- 它可以判断特征的重要程度
- 可以判断出不同特征之间的相互影响
- 不容易过拟合
- 训练速度比较快,容易做成并行方法
- 实现起来比较简单
- 对于不平衡的数据集来说,它可以平衡误差。
- 如果有很大一部分的特征遗失,仍可以维持准确度。
缺点
- 随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟合。
- 对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的
线性回归
如果 2 个或者多个变量之间存在“线性关系”,那么我们就可以通过历史数据,摸清变量之间的“套路”,建立一个有效的模型,来预测未来的变量结果。

线性关系不仅仅只能存在 2 个变量(二维平面)。3 个变量时(三维空间),线性关系就是一个平面,4 个变量时(四维空间),线性关系就是一个体。以此类推…

公式

wi为权重,xi为特征值,b为偏置项=w0x1
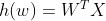
损失函数:
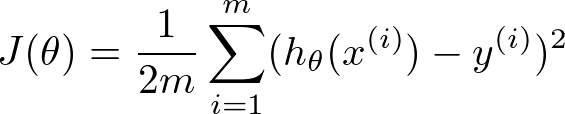
最小二乘法
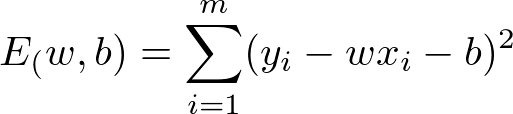
求w值有两种方法:
- 正规方程
- 梯度下降
正规方程公式:
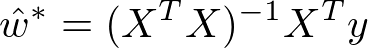
梯度下降公式
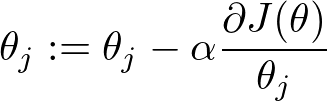
API:
# 正规方程
from sklearn.linear_model import LinearRegression
# 梯度下降
from sklearn.linear_model import SGDRegression
# x,y值都需要标准化
评判标准:均方差
from sklearn.metrix import mean_squared_error
优点:
- 建模速度快,不需要很复杂的计算,在数据量大的情况下依然运行速度很快。
- 可以根据系数给出每个变量的理解和解释
缺点:
- 不能很好地拟合非线性数据。所以需要先判断变量之间是否是线性关系
- 过拟合:原始特征过多,存在嘈杂特征;解决方法:特征选择,交叉验证,正则化
- 欠拟合:特征太少
l2正则化:L2正则化,即原损失函数 + 所有权重平方和的平均值 * λ / 2 , λ>0
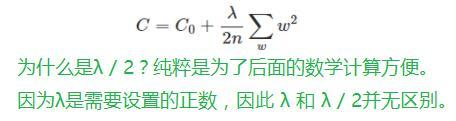
同样,需要先对ω求导:
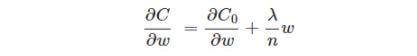
那么权重ω的更新规则为:
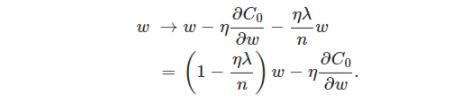
岭回归
带有正则化的线性回归
API:
from sklearn.linear_model import Ridge
模型保存与加载
from sklearn.externals import joblib
joblib.dump() #保存
joblib.load() #加载
逻辑回归
利用sigmoid函数
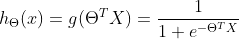
损失函数:
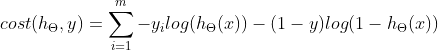
均方误差不存在多个局部最低点,只有一个最优解;对数似然函数有多个局部最优点
from sklearn.linear_model import LogisticRegression

K-means算法
步骤:
- 随机设置k个特征空间的点,作为初始的聚类中心
- 对于其余点计算到这k个点的距离,未知的点选择最近的一个聚类中心点作为标记类别
- 分别计算k个族群的平均值,得到新的中心点
- 如果新中心点和原中心点一致,则结束,否则以新的点开始迭代
from sklearn.Cluster import Kmeans
评估标准:轮廓系数
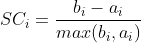
bi为i点到其他族群的所有样本距离最小值,ai为到本身簇的距离平均值
from sklearn.metrix import silhouette_score
















 2641
2641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









