







Transformer 是谷歌大脑在 2017 年底发表的论文 attention is all you need 中所提出的 seq2seq 模型。现在已经取得了大范围的应用和扩展,而 BERT 就是从 Transformer 中衍生出来的预训练语言模型
这篇文章分为以下几个部分
- Transformer 直观认识
- Positional Encoding
- Self Attention Mechanism
- 残差连接和 Layer Normalization
- Transformer Encoder 整体结构
- Transformer Decoder 整体结构
- 总结
- 参考文章
0. Transformer直观认识
Transformer 和 LSTM 的最大区别,就是 LSTM 的训练是迭代的、串行的,必须要等当前字处理完,才可以处理下一个字。而 Transformer 的训练时并行的,即所有字是同时训练的,这样就大大增加了计算效率。Transformer 使用了位置嵌入 (Positional Encoding) 来理解语言的顺序,使用自注意力机制(Self Attention Mechanism)和全连接层进行计算,这些后面会讲到
Transformer 模型主要分为两大部分,分别是 Encoder 和 Decoder。Encoder 负责把输入(语言序列)隐射成隐藏层(下图中第 2 步用九宫格代表的部分),然后解码器再把隐藏层映射为自然语言序列。例如下图机器翻译的例子(Decoder 输出的时候,是通过 N 层 Decoder Layer 才输出一个 token,并不是通过一层 Decoder Layer 就输出一个 token)

#模型重要参数
src_len = 5 # length of source sentence
tgt_len = 5 # length of target sentence
d_model = 512 # Embedding Size
d_ff = 2048 # FeedForward dimension
d_k = d_v = 64 # dimension of K(=Q), V
n_layers = 6 # number of Encoder of Decoder Layer
n_heads = 8 # number of heads in Multi-Head Attention
# input:[batch_size,src_len] 每一个batch形如[0,1,2,3,4,5]其中每个数字表示单词或字在vocabulary中的index
1. Positional Encoding
由于 Transformer 模型没有循环神经网络的迭代操作,所以我们必须提供每个字的位置信息给 Transformer,这样它才能识别出语言中的顺序关系
现在定义一个位置嵌入的概念,也就是 Positional Encoding,位置嵌入的维度为 [max_sequence_length, embedding_dimension], 位置嵌入的维度与词向量的维度是相同的,都是 embedding_dimension。max_sequence_length 属于超参数,指的是限定每个句子最长由多少个词构成
注意,我们一般以字为单位训练 Transformer 模型。首先初始化字编码的大小为 [vocab_size, embedding_dimension],vocab_size 为字库中所有字的数量,embedding_dimension 为字向量的维度,对应到 PyTorch 中,其实就是 nn.Embedding(vocab_size, embedding_dimension)
论文中使用了 sin 和 cos 函数的线性变换来提供给模型位置信息:
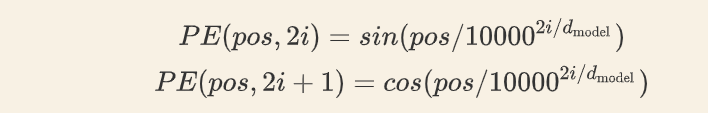
上述公式中,pos表示单词在句子中的绝对位置,i表示单词embedding_size的某一个维度,d_model就是embedding_size.
如果不理解这里为何这么设计,可以看这篇文章 Transformer中的Positional Embedding
此外,要注意的是,Transformer论文中的embedding是固定的,不参与训练。
def get_sinusoid_encoding_table(n_position, d_model):# n_position表示句子最大长度
def cal_angle(position, hid_idx):
return position / np.power(10000, 2 * (hid_idx // 2) / d_model)
def get_posi_angle_vec(position):
return [cal_angle(position, hid_j) for hid_j in range(d_model)]
sinusoid_table = np.array([get_posi_angle_vec(pos_i) for pos_i in range(n_position)])
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
return torch.FloatTensor(sinusoid_table) #shape:[src_len,d_model]
2. Self Attention
对于输入的句子X ,通过 WordEmbedding 得到该句子中每个字的字向量,同时通过 Positional Encoding 得到所有字的位置向量,将其相加(维度相同,可以直接相加),得到该字真正的向量表示。第 t个字的向量记作 xt
计算公式如图
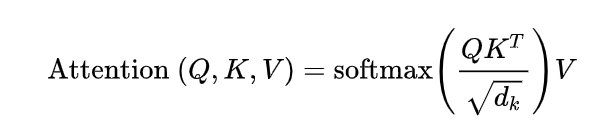
接着我们定义三个矩阵WQ,WK,WV,使用这三个矩阵分别对所有的字向量进行三次线性变换,于是所有的字向量又衍生出三个新的向量 qt,kt,vt。我们将所有的 qt 向量拼成一个大矩阵,记作查询矩阵 Q,将所有的 kt 向量拼成一个大矩阵,记作键矩阵K ,将所有的vt向量拼成一个大矩阵,记作值矩阵 V(见下图)

接下来,Q和KT相乘除以d_k,经过softmax以后乘以V得到输出

Multi-Head Attention
这篇论文还提出了 Multi-Head Attention 的概念。其实很简单,前面定义的一组 可以让一个词 attend to 相关的词,我们可以定义多组Q,K,V ,让它们分别关注不同的上下文。计算 的过程还是一样,只不过线性变换的矩阵从一组 变成了多组。

Padding Msk

上面 Self Attention 的计算过程中,我们通常使用 mini-batch 来计算,也就是一次计算多句话,即X的维度是[batch_size,sequence_length],而一个mini_batch是由多个不等长的句子进行补齐,一般用0进行填充,这个过程叫padding
同时,为了在使用注意力机制时使注意力不关注这些位置,需要将QKT相乘后得到的score(shape:[len_q,len_k])中那些padding位置改为一个一个很大的负数,这样softmax后,其权重很低。
3. 残差连接和 Layer Normalization
残差连接
Layer Normalization


4. Transformer Encoder 整体结构


5. Transformer Decoder 整体结构
我们先从 HighLevel 的角度观察一下 Decoder 结构,从下到上依次是:
- Masked Multi-Head Self-Attention
- Multi-Head Encoder-Decoder Attention
- FeedForward Network

Masked Self-Attention
具体来说,传统 Seq2Seq 中 Decoder 使用的是 RNN 模型,因此在训练过程中输入t时刻的词,模型无论如何也看不到未来时刻的词,因为循环神经网络是时间驱动的,只有当 t时刻运算结束了,才能看到 t+1时刻的词。而 Transformer Decoder 抛弃了 RNN,改为 Self-Attention,由此就产生了一个问题,在训练过程中,整个 ground truth 都暴露在 Decoder 中,这显然是不对的,我们需要对 Decoder 的输入进行一些处理,该处理被称为 Mask


之后再做 softmax,就能将 - inf 变为 0,得到的这个矩阵即为每个字之间的权重

Masked Encoder-Decoder Attention
其实这一部分的计算流程和前面 Masked Self-Attention 很相似,结构也一摸一样,唯一不同的是这里的K,V为 Encoder 的输出, 为Q为Decoder 中 Masked Self-Attention 的输出
6.总结

Transformer 为什么需要进行 Multi-head Attention?
原论文中说到进行 Multi-head Attention 的原因是将模型分为多个头,形成多个子空间,可以让模型去关注不同方面的信息,最后再将各个方面的信息综合起来。其实直观上也可以想到,如果自己设计这样的一个模型,必然也不会只做一次 attention,多次 attention 综合的结果至少能够起到增强模型的作用,也可以类比 CNN 中同时使用多个卷积核的作用,直观上讲,多头的注意力有助于网络捕捉到更丰富的特征 / 信息
Transformer 相比于 RNN/LSTM,有什么优势?为什么?
- RNN 系列的模型,无法并行计算,因为 T 时刻的计算依赖 T-1 时刻的隐层计算结果,而 T-1 时刻的计算依赖 T-2 时刻的隐层计算结果
- Transformer 的特征抽取能力比 RNN 系列的模型要好
为什么说 Transformer 可以代替 seq2seq?
这里用代替这个词略显不妥当,seq2seq 虽已老,但始终还是有其用武之地,seq2seq 最大的问题在于将 Encoder 端的所有信息压缩到一个固定长度的向量中,并将其作为 Decoder 端首个隐藏状态的输入,来预测 Decoder 端第一个单词 (token) 的隐藏状态。在输入序列比较长的时候,这样做显然会损失 Encoder 端的很多信息,而且这样一股脑的把该固定向量送入 Decoder 端,Decoder 端不能够关注到其想要关注的信息。Transformer 不但对 seq2seq 模型这两点缺点有了实质性的改进 (多头交互式 attention 模块),而且还引入了 self-attention 模块,让源序列和目标序列首先 “自关联” 起来,这样的话,源序列和目标序列自身的 embedding 表示所蕴含的信息更加丰富,而且后续的 FFN 层也增强了模型的表达能力,并且 Transformer 并行计算的能力远远超过了 seq2seq 系列模型
本文主要参考
https://wmathor.com/index.php/archives/1438/
代码实现:
https://wmathor.com/index.php/archives/1455/















 3703
3703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









