







目录
- 1、CarPole-v0环境
- 2、DQN
- 3、Q-learing/DQN(李宏毅)
- 4、Q-Learing for Continuous Actions
在Q-learning中我们建立了一个Q表,智能体通过查询Q表来确定动作,当然表示一个Q表必须要求状态是离散的(即有限的状态数量)。但当环境的状态为连续(即无限多个状态)的时候呢,Q-learning就无法通过建立表格来确定每个动作的Q值了。比如OpenAI Gym中的经典控制问题CarPole-v0的状态为连续的。
\\[30pt]
1、CarPole-v0环境
通过以下代码将CarPole-v0环境渲染出来:
import gym
env = gym.make('CartPole-v0')
env.reset()
for _ in range(1000):
env.render()
env.step(env.action_space.sample()) # take a random action
env.close()
显示效果如下:

黑色方块为小车,杆子的一端连接到小车上,由于重力影响杆子会倾斜,当杆子倾斜一定的角度后会倒下。该游戏的任务是控制小车左右移动使得杆子立起来,立起来的时间越长收益越多,即收益与杆子立起来的时间成正比,一旦杆子倒下,游戏结束。
- CarPole-v0的状态由四个值构成:
| 序号 | 环境信息 | 最小值 | 最大值 |
|---|---|---|---|
| 1 | 小车的位置 | − 1.4 -1.4 −1.4 | 2.4 2.4 2.4 |
| 2 | 小车的速度 | − ∞ -\infty −∞ | + ∞ +\infty +∞ |
| 3 | 杆子的倾斜角度 | − 41. 8 ∘ -41.8^\circ −41.8∘ | 41. 8 ∘ 41.8^\circ 41.8∘ |
| 4 | 杆子顶端的移动速度 | − ∞ -\infty −∞ | + ∞ +\infty +∞ |
- 动作为0和1,分别表示向左和向右移动一步。
\\[30pt]
2、DQN
在Q-learning中智能体通过查询Q表选择动作,每个状态对应该状态下所有动作的Q值,但当状态空间较大或状态是连续时,该算法就显得力不从心了。DQN是基于Q-learning的思想,它将当前状态作为神经网络的输入,最后网络输出每个动作的Q值。因此,DQN与Q-learning的唯一缺别是计算Q值的方式不一样罢了,即DQN = Q-learning + NN。
在Q-learning中,Q值的更新公式为:
Q
(
S
t
,
A
t
)
←
Q
(
S
t
,
A
t
)
+
α
[
R
t
+
1
+
γ
max
a
Q
(
S
t
+
1
,
a
)
−
Q
(
S
t
,
A
t
)
]
(1)
Q(S_t,A_t)\leftarrow Q(S_t,A_t)+\alpha[R_{t+1}+\gamma \max_a Q(S_{t+1},a)-Q(S_t,A_t)] \tag{1}
Q(St,At)←Q(St,At)+α[Rt+1+γamaxQ(St+1,a)−Q(St,At)](1)
从式子(1)看出,Q-learning的学习目标为
R
t
+
1
+
γ
max
a
Q
(
S
t
+
1
,
a
)
R_{t+1}+\gamma \max_a Q(S_{t+1},a)
Rt+1+γmaxaQ(St+1,a),我们希望该值与
Q
(
S
t
,
A
t
)
Q(S_t,A_t)
Q(St,At)的值越接近越好,当二者的值很接近时可认为Q值已收敛。
但是在DQN中学习目标是什么呢?我们借助下图来进行描述,首先输入当前状态
S
t
S_t
St到Q网络,输出当前状态下所有动作的Q值,然后根据
ε
\varepsilon
ε-greedy策略选择动作
A
A
A,这时候得到
S
t
S_t
St下动作
A
A
A的价值
Q
(
S
t
,
A
)
Q(S_t,A)
Q(St,A)。其次,将下一个状态
S
t
+
1
S_{t+1}
St+1输入到同一个Q网络中,输出所有动作的Q值,我们选择最大的Q值,这时得到了我们的学习目标
R
t
+
1
+
γ
max
a
Q
(
S
t
+
1
,
a
)
R_{t+1}+\gamma \max_a Q(S_{t+1},a)
Rt+1+γmaxaQ(St+1,a)(真实的Q值)。在Q-learning中我们希望学习目标越接近预测的
Q
(
S
t
,
A
t
)
Q(S_t,A_t)
Q(St,At)越好,因此在DQN中也一样,构建
Loss
=
R
t
+
1
+
γ
max
a
Q
(
S
t
+
1
,
a
)
−
Q
(
S
t
,
A
t
)
\text{Loss} = R_{t+1}+\gamma \max_a Q(S_{t+1},a)-Q(S_t,A_t)
Loss=Rt+1+γmaxaQ(St+1,a)−Q(St,At),使用该Loss更新Q网络,注意下图中虽然绘制了两个Q网络,但是他们是同一个神经网络,这里只是为了方便呈现。
另外,如果把下面的Q网络在几步内固定下来,然后每隔多少步后把第一个Q网络的权重复制到这一个Q网络中,这样的的策略叫做固定目标Q网络。

\\[30pt]
3、Q-learing/DQN(李宏毅)
1) Introduction of Q-learning
a. 状态价值函数 V π ( s ) V^\pi(s) Vπ(s)
Q-learning是基于值函数的迭代方法,在该方法中我们学习不是一个策略,而学习的是一个critic,它并不会直接采取行为,而是评价当前的行为有多好或是多不好。其中
V
π
(
s
)
V^\pi(s)
Vπ(s)是在actor(策略)
π
\pi
π下状态s的价值函数,即从s开始一直到最终状态获得的累计收益的期望,即:
V
π
(
s
)
=
E
π
[
G
t
∣
S
t
=
s
]
=
E
π
[
∑
k
=
0
∞
γ
k
R
t
+
k
+
1
∣
S
t
=
s
]
V^\pi(s)=\Bbb E_\pi[G_t|S_t=s]=\Bbb E_\pi \left[\sum_{k=0}^\infty \gamma^k R_{t+k+1}|S_t=s \right]
Vπ(s)=Eπ[Gt∣St=s]=Eπ[k=0∑∞γkRt+k+1∣St=s]
若策略
π
\pi
π比较好,那么就会得到一个较大的
V
π
(
s
)
V^\pi(s)
Vπ(s);反之若较差,得到的
V
π
(
s
)
V^\pi(s)
Vπ(s)较小,分别对应下图中的两种情况。

- 下面是一个比如,这里的佐为是Critic,他评价大马不飞在阿光(actor)下的好坏,Critic评价大马步飞在以前的阿光和变强的阿光下的价值分别是bad和good。我们可看到相同的动作在不同的策略下会有不同的价值(效果)。

- 怎么评价一个状态的好坏呢?有MC和TD两种方法。MC方法要走完整个回合才能更新,而TD走一步更新一步。


- MC在不同幕得到的 G a G_a Ga可能相差较大,因为它是所有时间步收益之和。而TD的更新只用到了当前的收益再加上下一状态的价值,方差较小,但当下一状态的估计不精确的话,那么当前状态的价值也就不精确了。

- 下面的例子表明了采用不同的方法来估计状态
s
a
s_a
sa的价值
V
π
(
s
a
)
V^\pi(s_a)
Vπ(sa)会得到不一样的结果。

b. 状态-动作价值函数 Q π ( s , a ) Q^\pi(s,a) Qπ(s,a)
另外一种Critic是评价状态-动作对的价值函数
Q
π
(
s
,
a
)
Q^\pi(s,a)
Qπ(s,a),一直使用策略
π
\pi
π,在状态s处采取动作a后所得到的的累计折扣回报的期望,即:
Q
π
(
s
,
a
)
=
E
π
[
G
t
∣
S
t
=
s
,
A
t
=
a
]
=
E
π
[
∑
k
=
0
∞
γ
k
R
t
+
k
+
1
∣
S
t
=
s
,
A
t
=
a
]
Q^\pi(s,a)=\Bbb E_\pi[G_t|S_t=s,A_t=a]=\Bbb E_\pi \left[ \sum_{k=0}^\infty \gamma^k R_{t+k+1} |S_t=s,A_t=a \right]
Qπ(s,a)=Eπ[Gt∣St=s,At=a]=Eπ[k=0∑∞γkRt+k+1∣St=s,At=a]
在下图中展示了两种情况,第一种是输入(s,a)输出对应的Q价值函数,第二种是输入状态s输出所有动作的Q价值函数,后面这一种只适用于动作是离散的情况,即动作可以穷举出来。

下面展示了在策略
π
\pi
π下,通过TD或者MC求出
Q
π
(
s
,
a
)
Q^\pi(s,a)
Qπ(s,a)后,我们能找到另一个比策略
π
\pi
π更好的策略
π
′
\pi^\prime
π′。

那么怎么定义一个策略比另一个策略好呢?即对于所有的状态s,都有
V
π
′
(
s
)
≥
V
π
(
s
)
V^{\pi^\prime}(s) \geq V^\pi(s)
Vπ′(s)≥Vπ(s)。假如在策略
π
\pi
π下,我们得到了
Q
π
(
s
,
a
)
Q^\pi(s,a)
Qπ(s,a),然后在s处得到使
Q
π
(
s
,
a
)
Q^\pi(s,a)
Qπ(s,a)最大的那个动作,即
π
′
(
s
)
\pi^\prime(s)
π′(s),若有多个则随机选择一个动作即可。
注意,
π
′
(
s
)
\pi^\prime(s)
π′(s)不是一个新的NN,而是由
Q
π
(
s
,
a
)
Q^\pi(s,a)
Qπ(s,a)推出来的。另外,该方法只适用于离散的动作。

下面证明当我们取
π
′
(
s
)
=
arg max
a
Q
π
(
s
,
a
)
\pi^\prime(s)=\argmax_a Q^\pi(s,a)
π′(s)=aargmaxQπ(s,a),对所有的状态s有
V
π
′
(
s
)
≥
V
π
(
s
)
V^{\pi^\prime}(s) \geq V^\pi(s)
Vπ′(s)≥Vπ(s)。

2) Tip 1: Target Network
我们可以固定target网络,当Q网络N次更新后,再次将Q网络复制到target中。

3) Tip 2: Exploration
我们使用
ε
\varepsilon
ε-贪婪策略来选择动作,来探索未知的轨迹。虽然选择最大价值的动作是最好的,但我们也需要选择其他的动作,它有可能会导致较好的结果。就好比你刚到一个城市定居下来,刚开始的几天你去过3家餐厅,后面你就会选择3家中最好的那家去吃,但说不定还有比这3家以外更好的餐厅呢,所以你需要探索新的餐厅,我相信在最初的时候大多数情况下都会找到更好的那个餐厅的。

4) Tip 3: Replay Buffer


5) DQN (fixed target network)

6) Double DQN
横轴是训练的时间步,纵轴是所有状态价值的平均值,可看出在DQN中Q value会被高估,而double DQN估计的值和真实的值比较接近。

为什么DQN总是被高估了呢?这是因为我们的目标是使得
Q
(
s
t
,
a
t
)
和
r
t
+
max
a
Q
(
s
t
+
1
,
a
)
Q(s_t,a_t)和r_t+\max_a Q(s_{t+1},a)
Q(st,at)和rt+maxaQ(st+1,a)越接近越好,但当某个动作的Q值被高估了后,那么
Q
(
s
t
,
a
t
)
Q(s_t,a_t)
Q(st,at)就会变得越来越大。

那么怎么解决这种高估的问题呢?那就是double DQN做的事情,将原来的更新目标
r
t
+
max
a
Q
(
s
t
+
1
,
a
)
r_t+\max_a Q(s_{t+1},a)
rt+maxaQ(st+1,a)改变成
r
t
+
Q
′
(
s
t
+
1
,
arg max
a
Q
(
s
t
+
1
,
a
)
)
r_t+Q^\prime \left(s_{t+1},\argmax_a Q(s_{t+1},a) \right)
rt+Q′(st+1,aargmaxQ(st+1,a)),其中
Q
′
Q^\prime
Q′是目标Q网络。对比二者的更新公式:
D
Q
N
:
Q
(
S
t
,
A
t
)
←
Q
(
S
t
,
A
t
)
+
α
[
R
t
+
1
+
γ
max
a
Q
(
S
t
+
1
,
a
)
−
Q
(
S
t
,
A
t
)
]
\textcolor{red}{DQN: } Q(S_t,A_t)\leftarrow Q(S_t,A_t)+\alpha \left[R_{t+1}+\gamma \max_a Q(S_{t+1},a) -Q(S_t,A_t) \right]
DQN:Q(St,At)←Q(St,At)+α[Rt+1+γamaxQ(St+1,a)−Q(St,At)]
d
o
u
b
l
e
D
Q
N
:
Q
(
S
t
,
A
t
)
←
Q
(
S
t
,
A
t
)
+
α
[
R
t
+
1
+
γ
Q
′
(
S
t
+
1
,
arg max
a
Q
(
S
t
+
1
,
a
)
)
−
Q
(
S
t
,
A
t
)
]
\textcolor{red}{double \quad DQN: } Q(S_t,A_t)\leftarrow Q(S_t,A_t)+\alpha \left[R_{t+1}+\gamma Q^\prime \left( S_{t+1}, \argmax_a Q(S_{t+1},a) \right )-Q(S_t,A_t) \right]
doubleDQN:Q(St,At)←Q(St,At)+α[Rt+1+γQ′(St+1,aargmaxQ(St+1,a))−Q(St,At)]
结合代码来理解
def process_data(self):
# 随机从队列中取出一个batch大小的数据
data = random.sample(self.memory, self.batch)
state = tf.constant([d[0] for d in data], dtype=tf.float32)
action = tf.constant([d[1] for d in data], dtype=tf.float32)
next_state = tf.constant([d[2] for d in data], dtype=tf.float32)
r = [d[3] for d in data]
done = [d[4] for d in data]
y = self.Q_network(state).numpy()
Q1 = self.target_Q_network(next_state).numpy()
Q2 = self.Q_network(next_state).numpy()
nex_action = np.argmax(Q2, axis=1)
for i, (_, a, _, r, done) in enumerate(data):
if done:
target = r
else:
# target = r + self.gamma * np.max(Q1[i]) #这一行是DQN_ER
target = r + self.gamma * Q1[i][nex_action[i]]
target = np.array(target, dtype='float32')
y[i][a] = target
return state, y

7) Dueling DQN (改了网络的架构)

改变一个状态s的值,那么对应的所有状态-动作对的值都会改变。

将输出[7, 3, 2]里面的每个元素减去他们的和得到[3, -1, -2],再将这个结果加上V(s)得到新的Q(s,a)。

具体来说,Dueling DQN将Q网络分成了两部分,第一部分仅与状态s有关,与采取的动作a无关,我们称这部分叫价值函数(Value Function)部分,记做
V
(
s
;
θ
,
β
)
V(s;\theta,\beta)
V(s;θ,β),第二部分同时与状态s和动作a有关,这部分叫优势函数(Advantage Funtion),记做
A
(
s
,
a
;
θ
,
α
)
A(s,a;\theta,\alpha)
A(s,a;θ,α)。因此,最终的价值函数为
Q
(
s
,
a
;
θ
,
α
,
β
)
=
V
(
s
;
θ
,
β
)
+
(
A
(
s
,
a
;
θ
,
α
)
−
1
∣
A
∣
∑
a
′
∈
A
A
(
s
,
a
′
;
θ
,
α
)
)
Q(s,a;\theta,\alpha,\beta)=V(s;\theta,\beta)+\left(A(s,a;\theta,\alpha) -\frac{1}{|\mathcal A|}\sum_{a^\prime \in \mathcal A} A(s,a^\prime;\theta,\alpha)\right)
Q(s,a;θ,α,β)=V(s;θ,β)+(A(s,a;θ,α)−∣A∣1a′∈A∑A(s,a′;θ,α))
其中,
θ
\theta
θ是价值函数和优势函数的公共参数,
α
\alpha
α是优势函数部分的参数,
β
\beta
β是价值函数部分的参数
由于tensorflow提供的示例代码结构比较复杂,我另外提供示例代码以供参考。
#第一部分:定义了两个隐藏层,用于处理数据。
#第二部分:计算svalue,输出两个动作的价值
#第三部分:计算avalue,从h2层输入到该层,然后对avalue进行归一化胡处理,即增加A值的平均值为0的限制。我们用原来的avalue的值减去自己的均值来进行归一化。
# dueling DQN只改了网络架构。
def get_model(self):
# 第一部分
input = tl.layers.Input(shape=[None, self.input_dim])
h1 = tl.layers.Dense(16, tf.nn.relu, W_init=tf.initializers.GlorotUniform())(input)
h2 = tl.layers.Dense(16, tf.nn.relu, W_init=tf.initializers.GlorotUniform())(h1)
# 第二部分
svalue = tl.layers.Dense(2, )(h2)
# 第三部分
avalue = tl.layers.Dense(2, )(h2) # 计算avalue
mean = tl.layers.Lambda(lambda x: tf.reduce_mean(x, axis=1, keepdims=True))(avalue) # 用Lambda层,计算avg(a)
advantage = tl.layers.ElementwiseLambda(lambda x, y: x - y)([avalue, mean]) # a - avg(a)
output = tl.layers.ElementwiseLambda(lambda x, y: x + y)([svalue, advantage])
return tl.models.Model(inputs=input, outputs=output)
8) Prioritized Relay
我们可以对那些具有更大TD-error的数据附加更高的概率,使得他们更容易选择到。
原始文章为:Schaul, T., Quan, J., Antonoglou, I., and Silver, D. Prioritized experience replay. CoRR, abs/1511.05952, 2015b. URL .http://arxiv.org/abs/1511.05952

9) Multi-step
使用n步TD来平衡MC和TD。

10) Boisy Net
在原来的方法中我们使用
ε
\varepsilon
ε-贪婪策略来探索未知的轨迹,而我们可以在每幕的开始之前对Q网络的参数增加噪声。

在动作上添加噪声有一个问题,就是我们输入同样的状态可能会给出不同的动作,大多数是贪婪动作,但少数会是随机动作,实际上这个在真实的情况下不太正常。
相反,如果在Q网络的参数上增加噪声,那么在当前幕,看到同一个或类似的状态会采取相同的动作。这在原始的论文中称为state-dependent exploration。

左边是
ε
\varepsilon
ε-贪婪方法,右边是Noise net的方法,虽然左边学会了奔跑,但跑的方式不好所以比较慢。

11) Distributional Q-function
我们可以看到不同的分布可能会有相同的
Q
π
(
s
,
a
)
Q^\pi(s,a)
Qπ(s,a)。

对每个动作估算出一个分布出来。

12) Rainbow
下面是在DQN基础上加了某个机制,其中DDQN是double DQN,Rainbow是所有的机制。

下图表示在Rainbow中去掉某个机制的算法。

4、Q-Learing for Continuous Actions
针对连续的动作,有三种处理方式:
- solution 1:采样出N个可能的动作,然后带入Q函数里面看谁的Q值最大。
- solution 2:这其实是一个优化问题,找到一个动作a使得我们的Q函数达到最大,比如采取梯度上升算法。

- solution 3:动作现在是一个连续的向量,即每个分量都是连续的,那么怎么评价(s,a)的Q值呢?可以设计一个网络来做优化。下图中
a
和
μ
(
s
)
a和\mu(s)
a和μ(s)是个列向量,
Σ
(
s
)
\Sigma(s)
Σ(s)是个矩阵,
V
(
s
)
V(s)
V(s)是个标量。将s输入到网络中,会输出
μ
(
s
)
,
Σ
(
s
)
和
V
(
s
)
\mu(s),\Sigma(s)和V(s)
μ(s),Σ(s)和V(s)。
注意, Σ ( s ) \Sigma(s) Σ(s)不是正定的就不能保证 ( a − μ ( s ) ) T Σ ( s ) ( a − μ ( s ) ) (a-\mu(s))^T\Sigma(s)(a-\mu(s)) (a−μ(s))TΣ(s)(a−μ(s))为正, 将 输 出 的 m a t r i x 跟 另 外 一 个 m a t r i x 做 什 么 这 里 没 听 清 楚 \textcolor{red}{将输出的matrix跟另外一个matrix做什么这里没听清楚} 将输出的matrix跟另外一个matrix做什么这里没听清楚,以保证是正定的。所以设置 a = μ ( s ) a=\mu(s) a=μ(s)能使得 Q ( s , a ) Q(s,a) Q(s,a)达到最大。

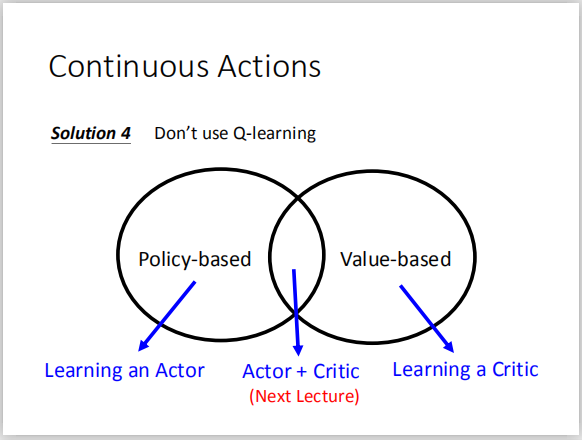
- solution 4: 不要使用Q-learing(听到这里笑尿了)















 242
242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









