






大家好,我是微学AI,今天给大家介绍一下基于通义千问Qwen大模型的图片理解的应用场景项目介绍:例如智能文档处理、医疗影像分析、前端页面生成、教育辅助。
项目背景
在当今数字化时代,图像处理和信息提取变得越来越重要。特别是在需要将图像内容转换为文本描述的场景中,自动化工具的需求日益增长。本项目旨在通过使用OpenAI的API,将图像转换为文本描述,从而满足这一需求。
应用场景
- 智能文档处理:自动识别和描述文档中的图像内容。通过OCR技术和图像识别算法,系统可以从扫描的文档中提取文本和图像信息。例如,在法律文件中,系统可以自动识别并提取合同中的关键条款和图表。
- 社交媒体内容分析:批量处理社交媒体图片并生成描述。通过分析用户上传的图片,系统可以自动生成描述,帮助提高内容的可访问性。例如,在Instagram上,系统可以为每张图片生成简要描述,帮助视障用户理解图片内容。
- 电子商务:自动生成商品图片的文字描述。通过分析商品图片,系统可以生成详细的产品描述,帮助消费者更好地了解产品。例如,在电商平台上,系统可以为每个商品图片生成详细的描述,包括颜色、材质和用途。
- 医疗影像分析:辅助医生理解医学影像。通过分析医学影像,系统可以自动生成报告,帮助医生更快地做出诊断。例如,在X光片或MRI图像中,系统可以标记出异常区域并提供初步诊断意见。
- 安防监控:实时分析监控画面并生成文字报告。通过实时分析监控视频,系统可以检测异常活动并生成警报。例如,在银行监控系统中,系统可以检测到可疑行为并立即通知安保人员。
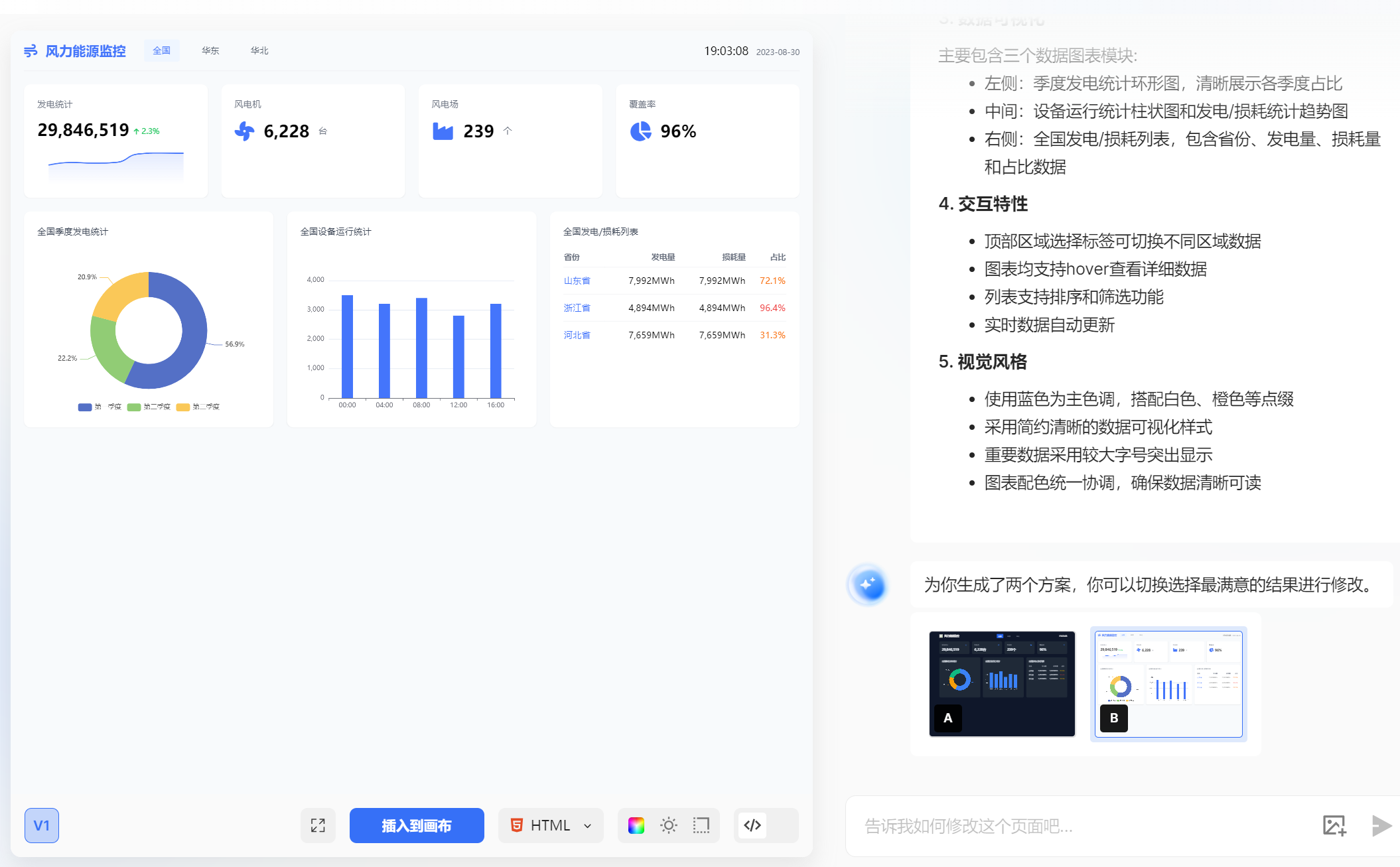
- 前端页面生成:通过分析设计图或原型图,自动生成对应的HTML/CSS代码或前端框架代码(如React、Vue)。例如,在UI设计工具中,系统可以解析设计图中的布局、颜色、字体等信息,并生成可直接使用的前端代码。这不仅提高了开发效率,还减少了手动编码过程中可能出现的错误。
- 教育辅助:为教学材料中的图片生成描述或解释。通过分析教材中的图表、公式或实验图片,系统可以生成详细的说明,帮助学生更好地理解复杂概念。例如,在数学或物理教材中,系统可以为几何图形或电路图生成详细的步骤解析。
- 游戏开发:自动生成游戏场景描述或角色设定。通过分析游戏设计图或概念图,系统可以生成文字描述,帮助开发者快速构建游戏背景故事或角色特性。例如,在角色扮演游戏(RPG)中,系统可以根据角色形象图生成详细的背景故事和技能设定。
- 艺术创作辅助:为艺术作品生成描述或标签。通过分析绘画、雕塑或其他艺术形式的作品,系统可以生成描述性文字或关键词标签,帮助艺术家进行作品分类或推广。例如,在艺术品拍卖网站上,系统可以为每件作品生成详细的描述,包括风格、主题和创作技法。
- 科研数据分析:自动解析科研论文中的图表并生成描述。通过分析论文中的实验数据图、流程图或结构图,系统可以生成简洁明了的文字描述,帮助研究人员快速理解图表内容。例如,在生物医学领域,系统可以为基因表达热图或蛋白质结构图生成详细的分析报告。
项目介绍
本项目主要包含两个部分:img2text.py和test_img2text.py。img2text.py负责将图像转换为Base64编码,并通过OpenAI的API生成文本描述。test_img2text.py则用于测试img2text函数的功能,确保其在不同情况下都能正常工作。
技术栈
- Python 3.8+
- OpenAI API
- Base64编码
- 单元测试框架
项目结构
project/
├── img2text.py # 核心功能实现
├── test_img2text.py # 测试文件
├── requirements.txt # 项目依赖
└── README.md # 项目文档
基本原理
-
图像转Base64:
- 使用
image_to_base64函数将图像文件读取并转换为Base64编码 - 支持多种图像格式(JPG、PNG、GIF等)
- 包含错误处理机制,确保程序稳定性
- 使用
-
API调用:
- 通过OpenAI的API进行图像分析
- 使用流式响应处理大量数据
- 支持自定义提示词和参数配置
-
错误处理:
- 文件不存在处理
- API调用异常处理
- 网络连接问题处理
- 内存溢出保护
实现代码(python)
以下是项目的核心代码片段:
# img2text.py
import os
from openai import OpenAI
import base64
from typing import Optional, Union
import logging
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def image_to_base64(image_path: str) -> Optional[str]:
"""
将图像文件转换为Base64编码
Args:
image_path (str): 图像文件路径
Returns:
Optional[str]: Base64编码的字符串,失败时返回None
"""
try:
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
except FileNotFoundError:
logger.error(f"Error: The file {image_path} was not found.")
return None
except Exception as e:
logger.error(f"Error: {e}")
return None
def img2text(image_path: str, prompt: str = "这张图片是什么") -> Optional[Union[str, dict]]:
"""
将图像转换为文本描述
Args:
image_path (str): 图像文件路径
prompt (str): 提示词,默认为"这张图片是什么"
Returns:
Optional[Union[str, dict]]: API响应结果,失败时返回None
"""
base64_image = image_to_base64(image_path)
if not base64_image:
return None
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
try:
completion = client.chat.completions.create(
model="qwen-vl-plus-2025-01-25",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"}
}
]
}],
stream=True,
)
return completion
except Exception as e:
logger.error(f"API调用错误: {e}")
return None
# test_img2text.py
import unittest
from img2text import img2text
import os
from unittest.mock import patch, MagicMock
class TestImg2Text(unittest.TestCase):
def setUp(self):
"""测试前的准备工作"""
self.valid_image_path = 'valid_image.jpg'
self.invalid_image_path = 'invalid_image.jpg'
self.non_existent_path = 'non_existent_image.jpg'
# 创建测试用的图片文件
with open(self.valid_image_path, 'wb') as f:
f.write(b'dummy image content')
def tearDown(self):
"""测试后的清理工作"""
if os.path.exists(self.valid_image_path):
os.remove(self.valid_image_path)
def test_img2text_valid_image(self):
"""测试有效图片的处理"""
with patch('openai.OpenAI') as mock_openai:
mock_client = MagicMock()
mock_openai.return_value = mock_client
mock_client.chat.completions.create.return_value = "测试响应"
result = img2text(self.valid_image_path)
self.assertIsNotNone(result)
def test_img2text_invalid_image(self):
"""测试无效图片的处理"""
result = img2text(self.invalid_image_path)
self.assertIsNone(result)
def test_img2text_no_image(self):
"""测试不存在的图片处理"""
result = img2text(self.non_existent_path)
self.assertIsNone(result)
def test_img2text_custom_prompt(self):
"""测试自定义提示词"""
with patch('openai.OpenAI') as mock_openai:
mock_client = MagicMock()
mock_openai.return_value = mock_client
mock_client.chat.completions.create.return_value = "自定义提示词响应"
result = img2text(self.valid_image_path, "请详细描述这张图片")
self.assertIsNotNone(result)
if __name__ == '__main__':
unittest.main()
使用说明
-
环境配置
pip install -r requirements.txt -
API密钥设置
export DASHSCOPE_API_KEY='your-api-key' -
基本使用
from img2text import img2text result = img2text('path/to/your/image.jpg')
性能优化
-
图像预处理
- 支持图像压缩
- 自动调整图像大小
- 格式转换优化
-
API调用优化
- 批量处理支持
- 并发请求处理
- 缓存机制
-
内存管理
- 大文件分块处理
- 自动清理临时文件
- 内存使用监控
安全性考虑
-
API密钥保护
- 环境变量管理
- 密钥轮换机制
- 访问权限控制
-
数据安全
- 本地数据加密
- 传输加密
- 敏感信息过滤
未来展望
-
功能扩展
- 支持更多图像格式
- 多语言支持
- 自定义模型训练
-
性能提升
- GPU加速支持
- 分布式处理
- 实时处理优化
-
应用场景拓展
- 视频处理支持
- 3D模型分析
- AR/VR内容生成
结论
通过本项目,我们实现了一个简单而强大的工具,能够将图像转换为文本描述。这不仅提高了信息处理的效率,也为未来的图像分析应用奠定了基础。项目的模块化设计和完善的错误处理机制,使其能够适应各种应用场景,并为后续的功能扩展提供了良好的基础。


















 870
870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











