









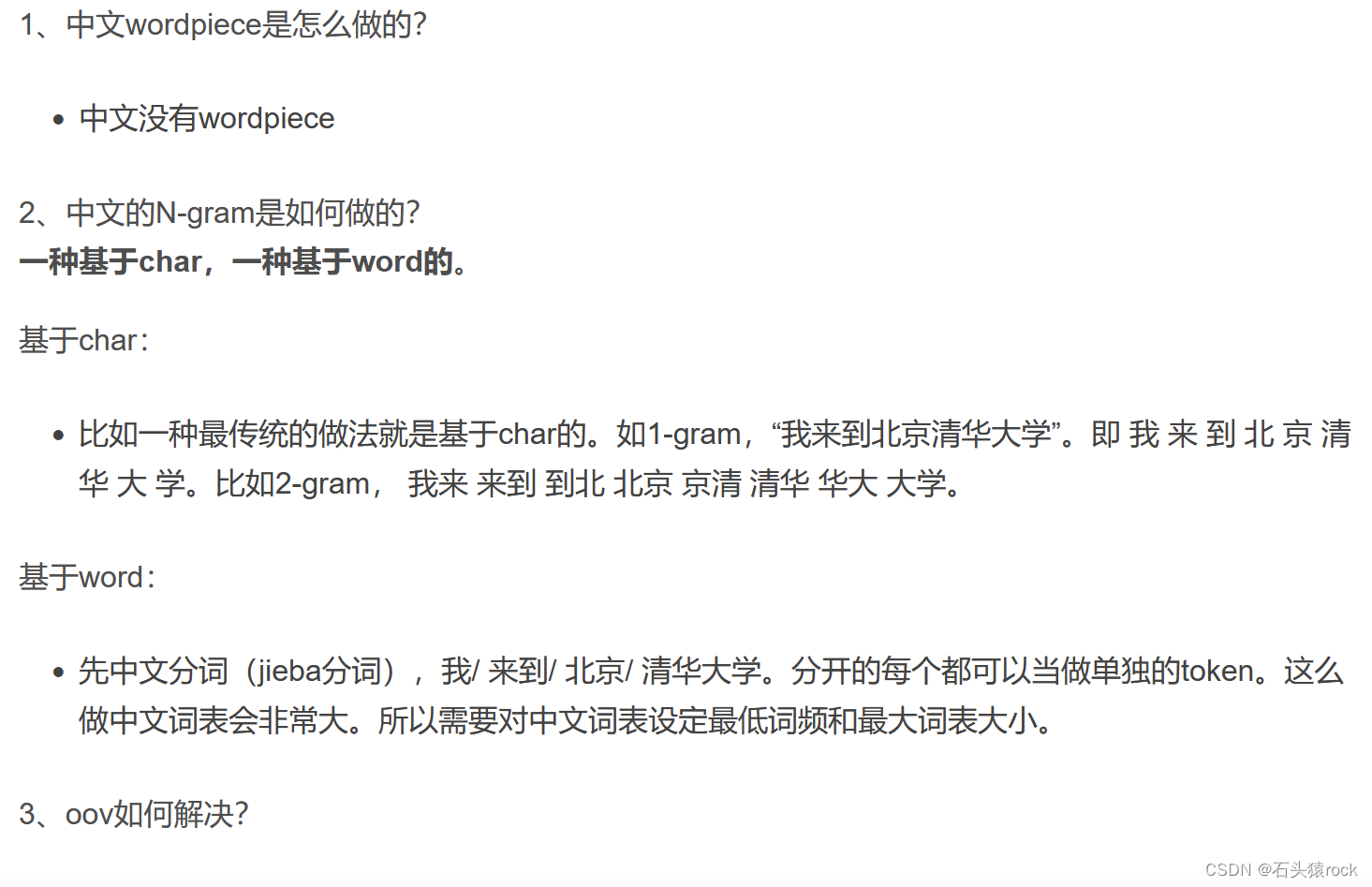
Bert的网络结构以及训练过程
Bert是文本编码器,它使用了Transformer的Encoder端,有两个预训练任务,分别是掩码语言模型和下一句子预测;掩码语言模型是随机选择15%的词,在这15%的词中,选择80%的词进行mask,选择10%的词随机替换成别的词,剩下10%的词什么也不做,然后根据上下文来预测这些词。下一句子预测是判断前后两个句子是否互为上下句;然后它使用了大规模的预料进行预训练。
这么做的主要原因是:① 在后续finetune任务中语句中并不会出现 [MASK] 标记;②预测一个词汇时,模型并不知道输入对应位置的词汇是否为正确的词汇( 10% 概率),这就迫使模型更多地依赖于上下文信息去预测词汇,并且赋予了模型一定的纠错能力。
Bert和Transformer的区别
Bert的输入,增加了segment embedding,和Transformer相比,将基于三角函数的位置编码替换成可学习的参数。
query和key为什么不用一个值
将单词的embeding通过不同的线性映射投影到独立的空间,增强了表达能力,增强了泛化性。
Bert的warmup策略
常规的学习率策略是一开始设置一个较大的学习率,在模型迭代的过程中,学习率逐渐减小,直到收敛到局部最优。
Bert使用warmup的原因是一开始模型对数据的分布非常陌生,如果使用较大的学习率,很容易发生过拟合的现象,后面需要通过多轮训练才能拉回来。使用warmup策略,模型在前几轮的迭代过程先慢慢熟悉数据分布,然后使用较大的学习率不容易让模型学偏,当模型训练到一定的阶段后,模型学习到了大概的数据分布,loss也已经接近了局部最优。
Bert预训练任务的loss

MLM是个语言模型,语言模型的损失函数是基于上下文的条件概率,-logp(y|x)
如何优化Bert的效果
1.使用质量更高的数据(通用法则)
2.取模型的后四层输出,最大池化或平均池化
3.模型集成,将现有的大模型以bagging方式进行集成
4.在Bert的输出上加网络层或再加一层注意力
5.在特定领域上的数据集上进行预训练

还了解过哪些预训练模型
百度ERNIE:对预训练任务进行了改进,第一阶段是基于切词的mask,第二阶段是基于实体的mask,让模型在预训练过程中学习到一些词级别,短语级别,实体级别的信息。
















 5319
5319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











