







 本文介绍了一种名为Prefix-Tuning的方法,通过在Transformer模型中添加可训练的前缀,以少量参数实现自然语言生成任务的Fine-Tuning替代。实验显示,即使在低数据和复杂任务中,Prefix-Tuning也能与Fine-Tuning和Adapter相比表现出更好的性能。研究还探讨了前缀长度、嵌入层调整等影响因素。
本文介绍了一种名为Prefix-Tuning的方法,通过在Transformer模型中添加可训练的前缀,以少量参数实现自然语言生成任务的Fine-Tuning替代。实验显示,即使在低数据和复杂任务中,Prefix-Tuning也能与Fine-Tuning和Adapter相比表现出更好的性能。研究还探讨了前缀长度、嵌入层调整等影响因素。
1.本文提出了Prefix-Tuning,一种轻量级的自然语言生成任务的fine-tune替代方案,使语言模型参数保持冻结状态,但是优化了一个小的连续的特定于任务的向量(这个向量称之为前缀)。
2.adapter-tuning是在预训练模型的层之间插入额外的特定于任务的层。只添加了2%-4%的任务参数。
3.GPT-3的in-context learning或者prompting,即在任务输入中预先准备自然语言任务指令和一些示例,然后从LM输出。
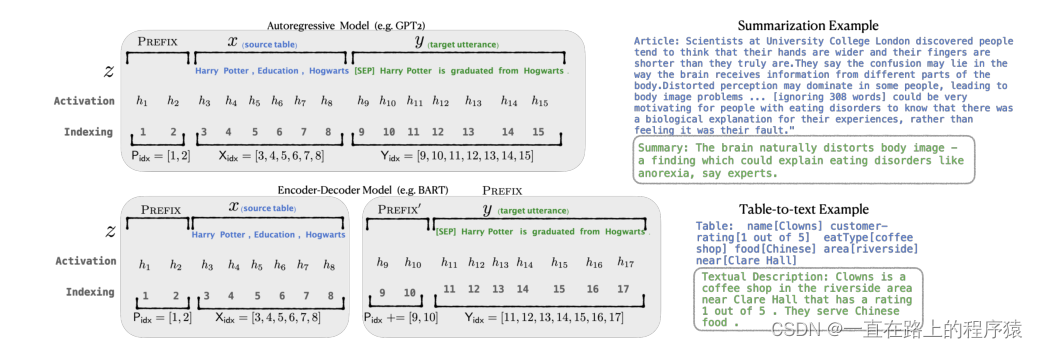
3.问题描述:
(1)假设有一个基于Transformer架构自回归的语言模型,
![]()
hi是再时间步i的所有激活层的一个连接,hi的计算如下所示:
![]()
hi的最后一层的输出被拿来计算下一个token的分布,即如下所示:

(2)Encoder-Decoder 结构
(3)微调,使用如下的目标函数进行微调
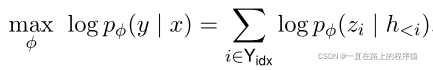
4.Prefix-Tuning
方法如下所示:
Prefix-tuning为自回归语言模型,添加一个前缀,z=[Prefix;x;y],Pidx是前缀索引的序列,|Pidx|即为前缀的长度。

训练目标函数如上所示,不同的是语言模型的参数固定,只训练前缀参数。观察发现,对于所有的i来说,hi是可训练PΘ的函数。当i不属于Pidx时,hi依然依赖于PΘ,因为prefix activations总是在左边,总是会影响到右边任意一个activation。
PΘ参数化问题:直接更新PΘ参数会导致优化不稳定,性能略有下降。论文中的做法重新参数化矩阵PΘ,
![]()
行数相等,列数不同,后者列数少于前者(该方法思路,将原来的PΘ作为中间结果,而不是原来模型中的起始,将更小的矩阵作为开始点。)。一旦训练完成,只需保留前向神经网络的结果即可,其余的参数可以删除。
5.实验
三个table to text数据集:E2E,WebNLG,DART,三个数据集按照复杂度和大小依次升高。
一个摘要数据集:XSUM
(1)在table to text中的实验效果如下图所示:
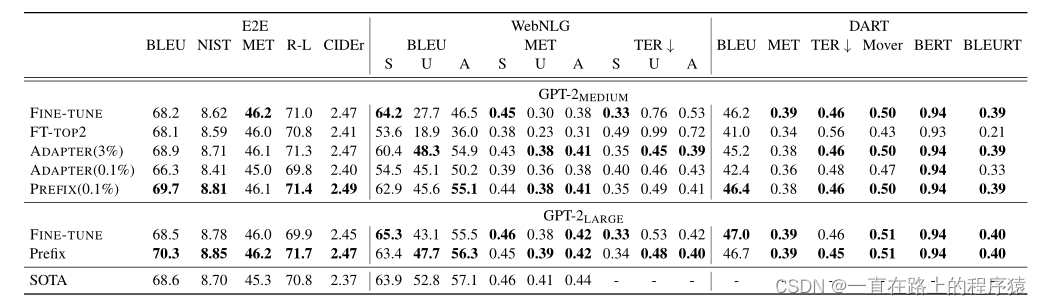
Prefix性能超过轻量级的基准(FT-TOP2,ADAPTER),达到了和fine-tune相当的性能;Prefix优于adapter(0.1%)的性能,甚至优于fine-tuning和adapter(3.0%)的性能;这表明prefix-tuning在减少参数的同时,提高了生成数据的质量。
(2)摘要任务性能:
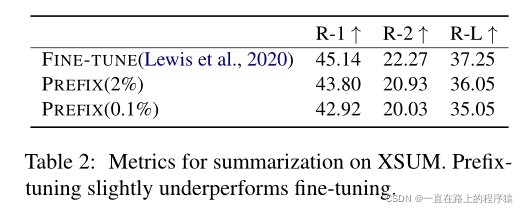
观察可知,只需2%的参数就可以获得比fine-tune少两个点左右的效果;而0.1%的参数,prefix则相差较远。同央视0.1%的参数,导致在XSUM中和tabel to text效果不同的原因有三个:①XSUM有更多的训练数据②XSUM输入文章的长度是表格输入的17倍③摘要更加的复杂,需要阅读理解并识别文章关键内容。
(3)Low-data Setting,为了构建低数据设置,我们对完整的数据集(E2E用于表到文本,XSUM用于摘要)进行子采样,以获得大小为{50100200500}的小数据集。
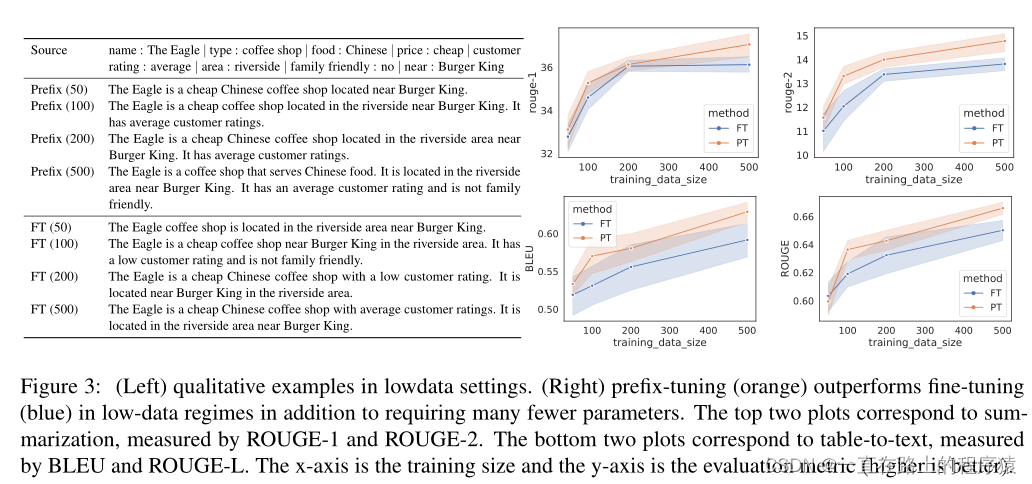
左边是在低数据量下的生成例子,虽然内容都生成不足,但是prefix tuning比fine tuning更加可靠。例如prefix和FT的(100,200)例子,前者更加符合表格的内容。
(4)推断任务(对未知主题的推断能力)
构建两个推断数据集,分别是news-to-sports和within-news(news下有许多子部分,比如"world","UK",“business”等,使用这三个作为训练data,剩下的作为测试数据)。实验结果图如下所示:

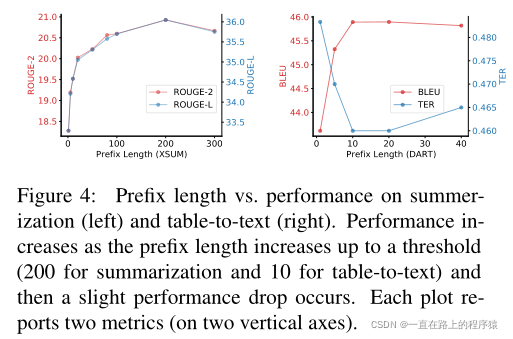
(5)对前缀长度的探索
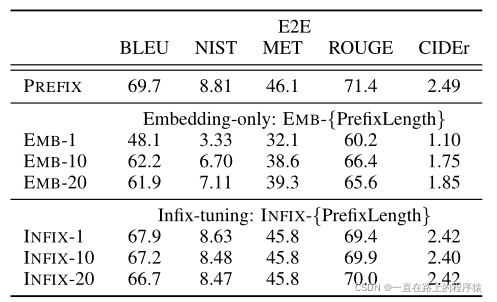
(6)Full vs Embedding-only(调节transformer的所有层(在tranformer的每一层加入提示) vs 只调节embedding 层)

















 783
783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









