






邮件检测平台的搭建
上学期导师让我们搭建一个垃圾邮件检测的网站,于是乎我跟队友开始查询各种资料,进行调研,决定由他做网页前端设计和后台逻辑处理,而我负责检测算法编写和数据库的交互。
数据库和数据
数据库我选择了对文本处理比较友好的mongodb,邮件的训练集一共有二十万封。python有支持mongodb的库pymongo,在装mongo数据库的时候踩了很多坑,Windows向来对程序员不友好,转向linux后解决了mongo服务无法开启的问题。
网页的左半部分显示了数据库中邮件的总数,垃圾邮件和正常邮件的数量,选用轻量级框架Flask。
检测算法
检测垃圾邮件的算法参考了一篇论文,主要是借鉴了对邮件的处理,如何净化,解析邮件和提取特征,选用了机器学习中的集成算法和神经网络对邮件进行分类。
首先是对邮件的净化处理,需要对一些常用词用空格替代,这样做是为了将邮件中重要的词句提取出来,接着将一些换行符,空格符等特殊符号去掉,转换成简单文本。
// 净化邮件
def sanitiser_email(content):
string_list = []
for string in content:
sanitiser_email = []
text = dehtml(string)
text = text.replace('\n', '')
text = text.replace('\\n', '')
text = text.split(' ')
for item in text:
item = item.lower()
for signal in signal_stopwords:
if signal in item:
item = item.replace(signal, '')
#print(signal)
if item in stopwords:
item = item.replace(item, '')
sanitiser_email.append(item)
string = sanitiser_email[0] + ' ' + sanitiser_email[1]
#string = pure_email[0] + ' ' + pure_email[1]
for index in range(1,len(sanitiser_email)-1):
string = string + ' ' + sanitiser_email[index + 1]
#string.replace(' ', '')
string_list.append(string)
return string_list
解析邮件主要做的是统计邮件主体中超链接,javascript,附件等的数量。
// 解析邮件
def parse_email(email):
count_url = 0
count_atta = 0
email_feature = [0, 0]
for item in email:
if ('<head>' in item) | ('<body>' in item):
email_feature[0] = 1
if ('<script>') in item:
email_feature[1] = 1
if ('http://') in item:
count_url += 1
if 'Content-Disposition: attachment' in item:
count_atta += 1
email_feature.append(count_url)
email_feature.append(count_atta)
return email_feature
接下来的一步是最重要的一步,在这里我要介绍一下word2vec这个python库,它是google在2013年推出的一个NLP工具,它的特点是将所有的词向量化,这样词与词之间就可以定量的去度量他们之间的关系,挖掘词之间的联系。核心是两个神经网络算法 CBOW与Skip-Gram。

// 文本向量化
from gensim.models import word2vec
from nltk import tokenize
import numpy as np
def build_wordvec(text, size, model):
vec = np.zeros(size).reshape((1, size))
count = 1
for word in text:
try:
vec += model[word].reshape((1, size))
count += 1
except KeyError:
continue
if count != 0:
vec /= count
return vec
def build_feature(vocab_list):
fail_list = []
vec_feature = []
for i in range(len(vocab_list)):
open('corpus.txt', 'w+', encoding='utf-8').write(vocab_list[i])
try:
model = word2vec.Word2Vec(word2vec.LineSentence('corpus.txt'), min_count= 3)
except RuntimeError as e:
print(e)
fail_list.append(i)
else:
print('第{}轮'.format(i))
vect = build_wordvec(tokenize.word_tokenize(vocab_list[i]), 100, model)
vec_feature.append(list(vect[0]))
return vec_featur
最后得到文本向量,再将之前的统计的得到的矩阵concat就可以获得每一封邮件的1*104的特征向量矩阵。
邮件分类
训练集和验证集一共选取了十万封,前几次用了不到一万封,跑出的结果很乐观,但是放入新的测试集特征后出现了严重的过拟合,因此狠了狠心扩大了训练集(心疼我的电脑(ˉ▽ˉ;))。
// 邮件分类
import pandas as pd
from pandas import DataFrame
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score, f1_score
from sklearn.neural_network import MLPClassifier
from xgboost import XGBClassifier
from create_feature import *
columns = ['html', 'javascript', 'urlCount', 'attachCount']
for i in range(100):
columns.append('vector{}'.format(i))
ham_email_feature = email_feature_ham
spam_email_feature = email_feature_spam
ham_email = DataFrame(ham_email_feature, columns=columns)
spam_email = DataFrame(spam_email_feature, columns= columns)
train_x = pd.concat([spam_email, ham_email], axis= 0)
train_x = train_x.reset_index()
ham_email['label'] = 0
spam_email['label'] = 1
train_y = pd.concat([spam_email['label'], ham_email['label']], axis = 0)
train_y = train_y.reset_index()
x_train, x_test, y_train, y_test = train_test_split(train_x, train_y, random_state = 42)
x_train = x_train.drop(['index'], axis= 1)
x_test = x_test.drop(['index'], axis= 1)
y_train = y_train.drop(['index'], axis= 1)
y_test = y_test.drop(['index'], axis= 1)
#gbdt = GradientBoostingClassifier()
mlp = MLPClassifier(solver='lbfgs', activation= 'tanh', random_state= 0, hidden_layer_sizes= [10, 10])
#xgb = XGBClassifier()
mlp.fit(x_train, y_train)
preds =mlp.predict(x_test)
结果很好,达到九十多的正确率。
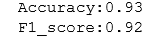
总结
这一次的邮件检测平台的搭建是第一次将机器学习算法和邮件分类结合在一起,也是首次接触了nlp,感觉这一领域水挺深的,没什么必要就不去深入研究了,还是好好水几篇论文毕业吧。
感谢论文的提供者,名字忘记啦。















 2384
2384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









