







代码仓库(数字空间项目,GN可上)
不想看的话,我也将代码上传到本博客中。
1.聚类算法简介
在数据科学和机器学习领域,聚类(Clustering)算法是一种无监督学习方法,它将相似的对象分到同一个组,而不同的对象则被分到不同的组。这种算法的主要目标是根据数据的特征进行分组,以此找出数据的内在结构。聚类算法的一个核心特点就是它并不需要预先知道数据的类别,而是通过算法自动进行分组。
在实际应用中,我们常见的聚类算法有K-means、DBSCAN、谱聚类、**AGNES(层次聚类)**等。每种算法都有其适用的场景,选择哪种算法主要取决于我们对数据的理解和目标。
在接下来的博客中,我们将深入探讨这些算法的工作原理,以及如何在实际问题中应用它们。本文,只涉及到划分聚类算法,本人使用C++实现了K-Means、K-Medoids、Spectral Clustering(谱聚类)和Mean-Shift算法。代码已经开源。
2. 划分聚类算法
聚类算法是典型的无监督学习,没有标签结果,即我们实际上并不知道准确的分类结果。聚类算法的评价指标往往非常主观,简单来说,聚类问题图解如下所示。
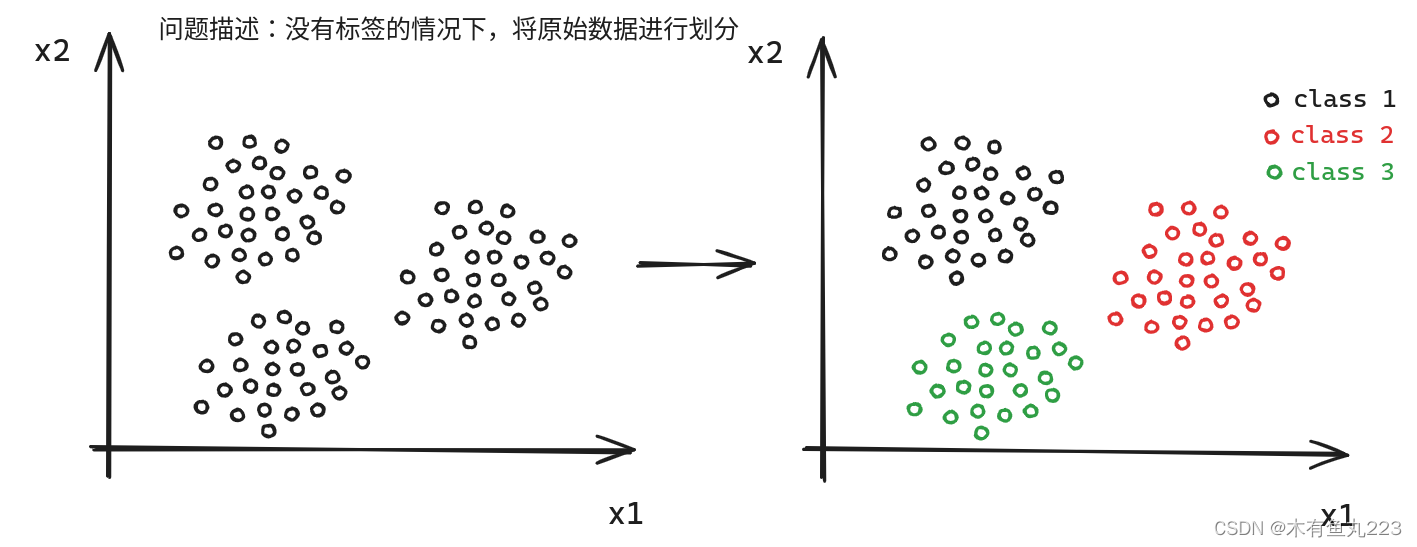
2.1 K-means算法
K-Means算法很早就出现了,核心思想:将数据集划分为K个集群,则每个集群内的数据点尽可能靠近(即内部差异小),而不同集群的数据点尽可能不同(即集群间差异大)。它需要确定各类中心点,然后依据每个点到中心点之间的L2距离确定属于哪一类,然后用每个类簇的平均点更新中心点。
2.1.1 算法核心描述
假定,数据点 x ⃗ = ( x 1 , x 2 , . . . , x n ) T \vec x=(x_1,x_2,...,x_n)^T x=(x1,x2,...,xn)T,数据集 { x ⃗ ( i ) ∣ i = 1 , . . . , m } \{\vec x^{(i)}|i=1,...,m\} {x(i)∣i=1,...,m},聚类簇的类别数 K K K,要求算法输出一个向量 y ⃗ = { k 1 , k 2 , . . . , k n ∣ k i = 0 , . . . , K − 1 } {\vec y=\{k_1,k_2,...,k_n|k_i = 0,...,K-1}\} y={k1,k2,...,kn∣ki=0,...,K−1}来表示聚类结果。
K-Means算法可以描述为以下三个步骤:
第一个初始化中心点(K个):
r
a
n
d
o
m
i
n
i
t
i
a
l
i
z
a
t
i
o
n
:
C
P
⃗
j
,
j
=
1
,
2
,
.
.
.
K
(1)
random\ \ initialization\ \ :\ \ \vec {CP}_j,\ \ \ j=1,2,...K\tag{1}
random initialization : CPj, j=1,2,...K(1)
根据中心点对每个数据进行类别划分:
C
l
a
s
s
(
x
⃗
(
i
)
)
=
a
r
g
m
i
n
j
∣
∣
x
⃗
(
i
)
−
C
P
⃗
j
∣
∣
(2)
Class(\vec x^{(i)}) = argmin_j||\vec x^{(i)} - \vec {CP}_j||\tag{2}
Class(x(i))=argminj∣∣x(i)−CPj∣∣(2)
用簇中的平均位置更新中心点:
C
P
⃗
j
=
∑
i
=
1
m
I
{
C
l
a
s
s
(
x
⃗
(
i
)
)
=
j
}
x
⃗
(
i
)
∑
i
=
1
m
I
{
C
l
a
s
s
(
x
⃗
(
i
)
)
=
j
}
,
j
=
1
,
2
,
.
.
.
K
(3)
\vec {CP}_{j}=\frac{\sum_{i=1}^mI\{{Class(\vec x^{(i)})=j\}\vec x^{(i)}}}{\sum_{i=1}^mI\{{Class(\vec x^{(i)})=j\}}},j=1,2,...K\tag{3}
CPj=∑i=1mI{Class(x(i))=j}∑i=1mI{Class(x(i))=j}x(i),j=1,2,...K(3)
循环执行(2)和(3)直到中心点不再发生变化,程序即可退出。
2.1.2 代码结果展示
这里的动图是循环的,代码执行的最后结果是均点不再发生变化。


2.1.3 优缺点
优点:算法简单,实现简单,直观,对于大规模数据集来说很实用(因为很简单)。
缺点:需要提前给出类簇数目K,随机的起始点对于聚类结果影响很大。离群点噪声对于该算法的影响将会是致命的。
3. 代码分享
from lib import clustering,dataGenerator # 这两个模块是自己用C++写的
import numpy as np
import matplotlib.pyplot as plt
if __name__ == '__main__':
y = dataGenerator.clusteringData(1000, 3, 2, -10, 10, 2)
clustering.init(y, 3, 10)
yy = np.array(y)
centerPoint = list([yy[0,:], yy[2,:], yy[-1,:]])
plt.figure(figsize=(8,8))
for i in range(10):
plt.cla()
centerPoint = clustering.singleTrain(centerPoint)
print(centerPoint)
label = clustering.getLabel(centerPoint)
# print(label)
indices1 = [i for i, x in enumerate(label) if x == 1]
indices2 = [i for i, x in enumerate(label) if x == 0]
indices3 = [i for i, x in enumerate(label) if x == 2]
lable = np.array(centerPoint)
plt.scatter(yy[indices1,0], yy[indices1,1], color = 'blue')
plt.scatter(yy[indices2,0], yy[indices2,1], color = 'pink')
plt.scatter(yy[indices3,0], yy[indices3,1], color = 'black')
plt.scatter(lable[:,0], lable[:,1], color='red')
plt.savefig('./image/' + str(i) + '.png')
plt.pause(1)
plt.show()
4.总结与思考
K-means算法呢,上个世纪中叶就有了,很简单。但是该算法仍有一些局限性:
1、需要预设聚类数量:K-means算法需要用户预先设定K值(即聚类的数量),这在实际应用中可能是一个挑战,因为最优的聚类数量通常是未知的。
2、对初始质心敏感:K-means算法的结果可能受到初始质心选择的影响。不同的初始质心可能会导致不同的聚类结果。
3、对异常值敏感:K-means算法对异常值和噪声很敏感,这些值可能会影响聚类质心的计算,从而影响最终的聚类结果。
4、假设聚类为凸形:K-means算法假设每个聚类的形状都是凸的,这在某些情况下可能不成立。
上述聚类数量K的确定,有一个“肘部法则”的方法。有一个一个簇内平方和的指标WCSS,一种用于评估聚类效果的指标,也可以用于确定聚类算法中的聚类数目K值。
具体做法是,对于每一个K值,我们都计算对应的WCSS值,然后画出K值与WCSS值的关系图。在这个图中,WCSS值会随着K值的增大而减小,但是当K值到达一个点之后,WCSS值的减小速率会明显降低,这个点就像人的肘部一样,因此被称为“肘点”。我们通常会选择这个“肘点”对应的K值作为最终的聚类数量。画个图解释如下所示。
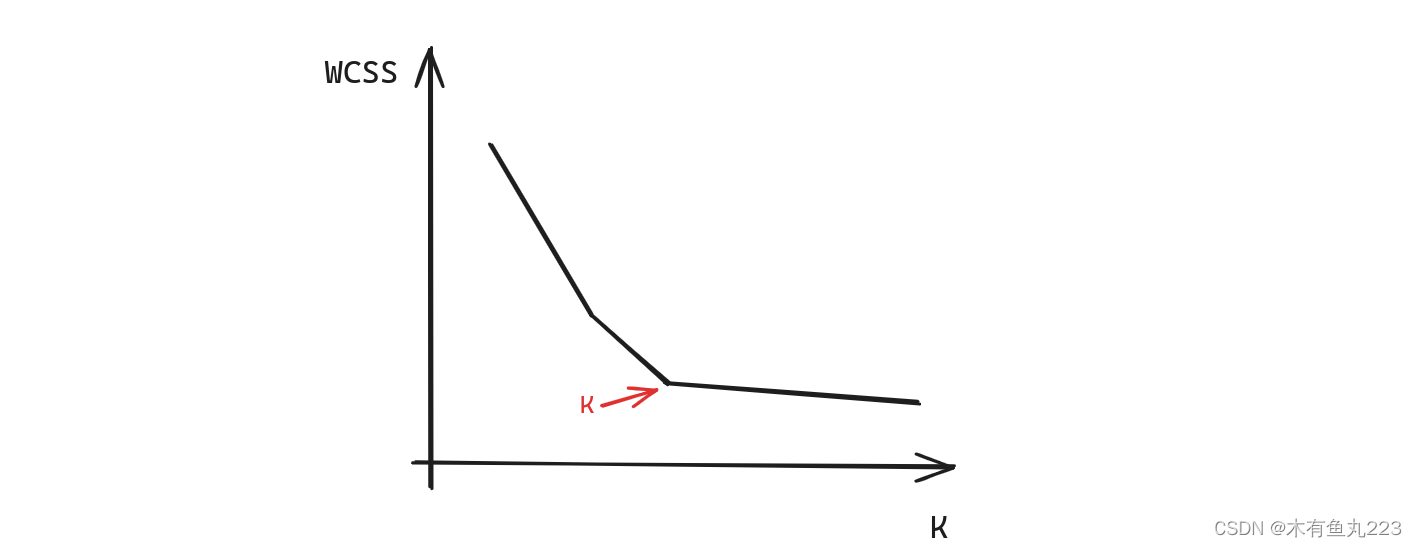















 1031
1031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









