









文章目录
- 概述
- 基于深度学习的边缘检测
- 一般的边缘检测
- 2019
- 2020
- 2021
- Pixel Difference Networks for Efficient Edge Detection
- HED-UNet: Combined Segmentation and Edge Detection for Monitoring the Antarctic Coastline(TGRS)
- RINDNet: Edge Detection for Discontinuity in Reflectance, Illumination, Normal and Depth(ICCV)
- LEARNING DEEP MORPHOLOGICAL NETWORKS WITH NEURAL ARCHITECTURE SEARCH
- 2022
- 遮挡边缘检测
概述
边缘检测(英语:Edge detection)是图像处理和计算机视觉中的基本问题,边缘检测的目的是标识数字图像中亮度变化明显的点。图像属性中的显著变化通常反映了属性的重要事件和变化。这些包括(i)深度上的不连续、(ii)表面方向不连续、(iii)物质属性变化和(iv)场景照明变化。 边缘检测是图像处理和计算机视觉中,尤其是特征检测中的一个研究领域。
本博文只介绍基于深度学习的边缘检测。
基于深度学习的边缘检测
基于深度学习的边缘检测分为三类:1.全要素边缘检测;2.物体边缘检测;3.语义边缘检测。如下图所示。.

这三个方向的论文和代码请自取。
一般的边缘检测
2019
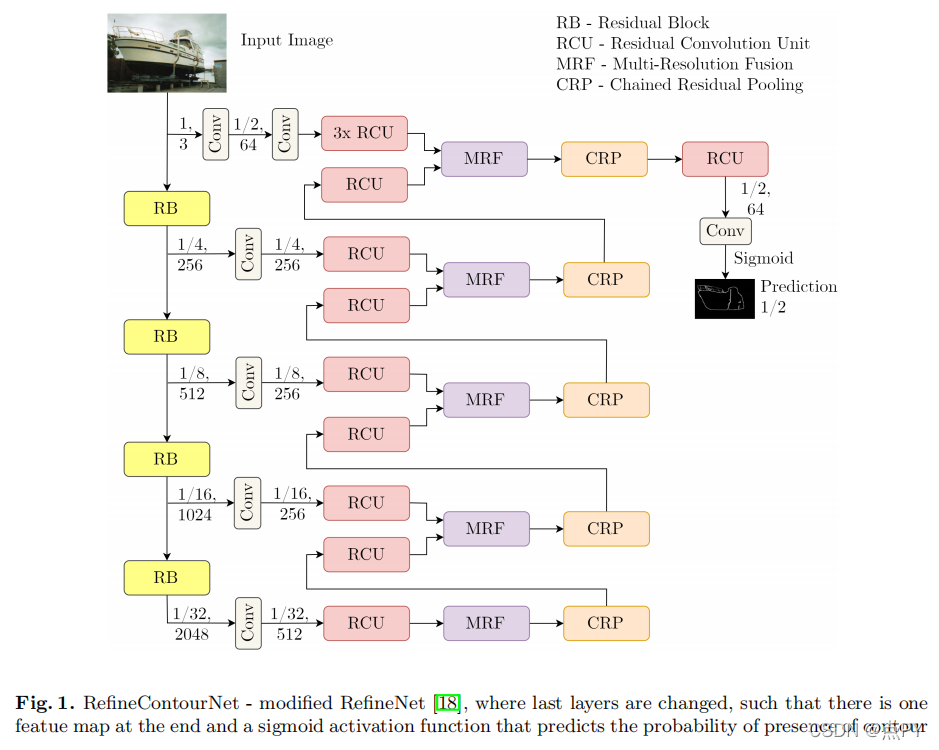
Object Contour and Edge Detection with RefineContourNet
code : https://github.com/daovietanh190499/ContourDetection
摘要
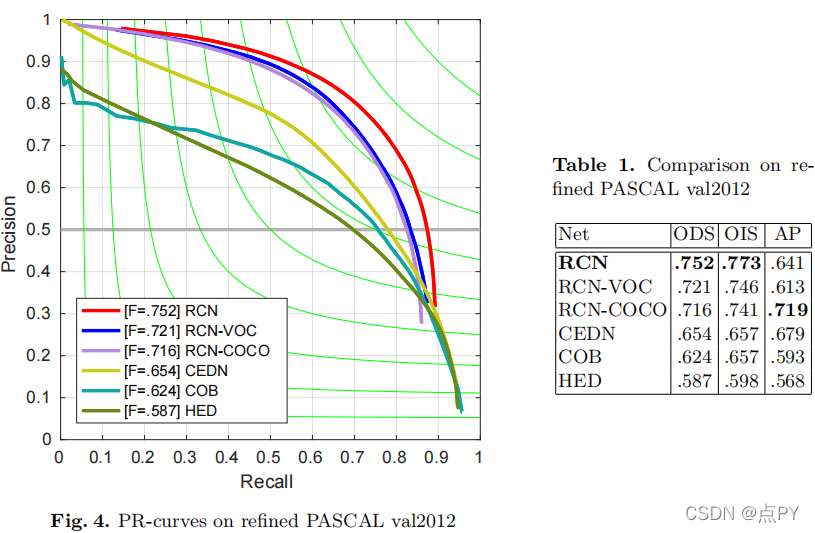
采用基于resnet的多路径细化CNN进行目标轮廓检测。对于这项任务,我们优先考虑有效利用ResNet的高级抽象能力,这导致了最先进的边缘检测结果。记住我们的重点,我们按照特定的顺序融合了高、中、低级别的特性,这与许多其他方法不同。它使用具有最高层次特征的张量作为起点,将其与具有较低抽象级别的特征分层结合起来,直到达到最低层次。我们在一个改进的帕斯卡VOC2012数据集上训练该网络,用于目标轮廓检测,并在一个改进的帕斯卡-val数据集上进行评估,达到优异的性能和最佳数据集尺度(ODS)为0.752。此外,通过对BSDS500数据集的精细训练,我们得到了最先进的ODS为0.824的边缘检测结果。
Edge-Direct Visual Odometry
code : https://github.com/kevinchristensen1/EdgeDirectVO
摘要
在本文中,我们提出了一种边缘直接视觉测程算法,有效地利用边缘像素找到相对姿态,以最小化图像之间的光度误差。之前利用边缘像素的工作是将边缘视为特征,并使用各种技术来匹配边线或像素,这增加了不必要的复杂性。直接方法通常用于所有的像素强度,这被证明是高度冗余的。相比之下,我们的方法建立在直接视觉测程方法上,最小的添加计算。它不仅比直接密集方法更有效,因为我们使用一小部分像素迭代,而且更准确。我们通过仅从一张图像中提取边缘,可以获得较高的精度和效率,并利用鲁棒高斯-牛顿来最小化这些边缘像素的光度误差。这同时找到参考图像中的边缘像素,以及使光度误差最小的相对相机姿态。
2020
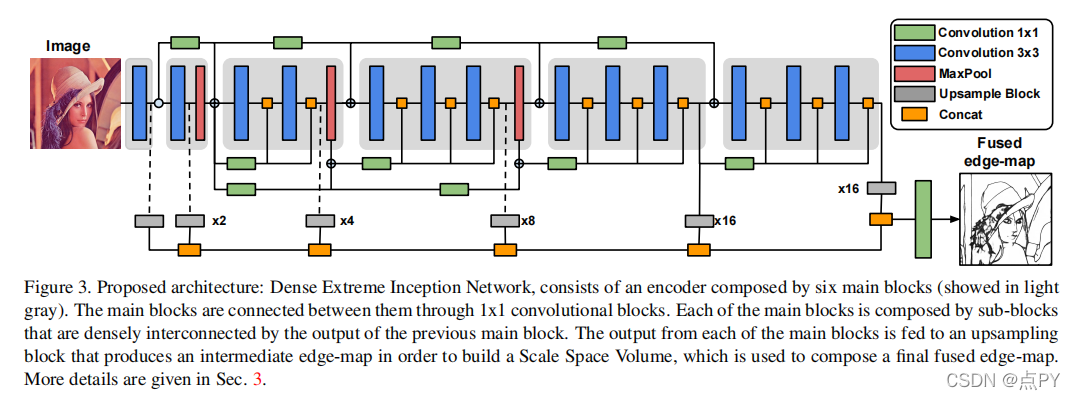
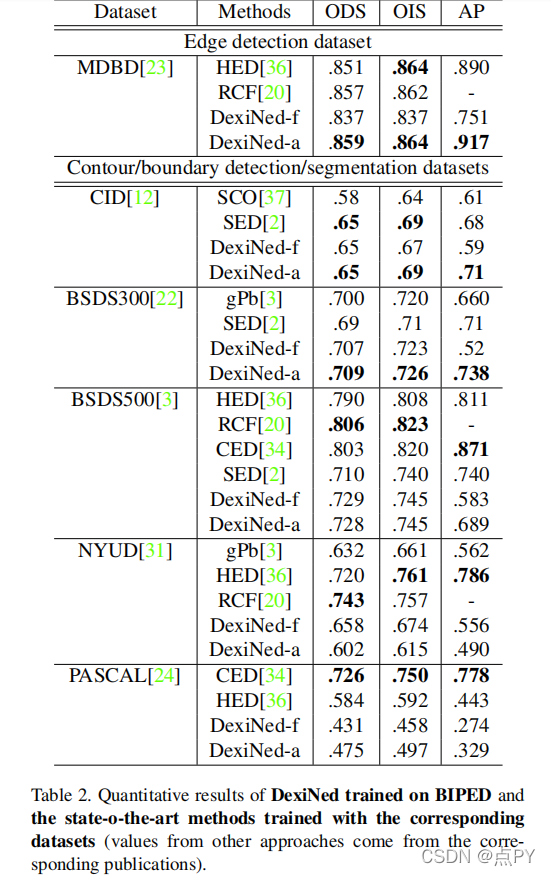
Dense Extreme Inception Network: Towards a Robust CNN Model for Edge Detection
code : https://github.com/xavysp/DexiNed
摘要
本文提出了一种基于深度学习的边缘检测器,它是基于HED(整体嵌套边缘检测)和x感觉网络。该方法生成适合人眼的薄边缘图;它可以用于任何边缘检测任务,而无需以前的训练或微调过程。作为第二个贡献,已经生成了一个具有仔细注释的边的大型数据集。该数据集已被用于训练所提出的方法以及最先进的比较算法。在不同的基准上进行了定量和定性评估,表明当考虑到ODS和OIS的f-测量时,所提出的方法有所改进。
2021
Pixel Difference Networks for Efficient Edge Detection
code: https://github.com/zhuoinoulu/pidinet
摘要:
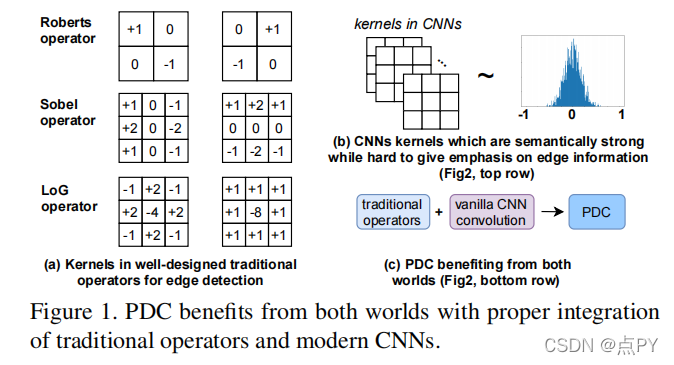
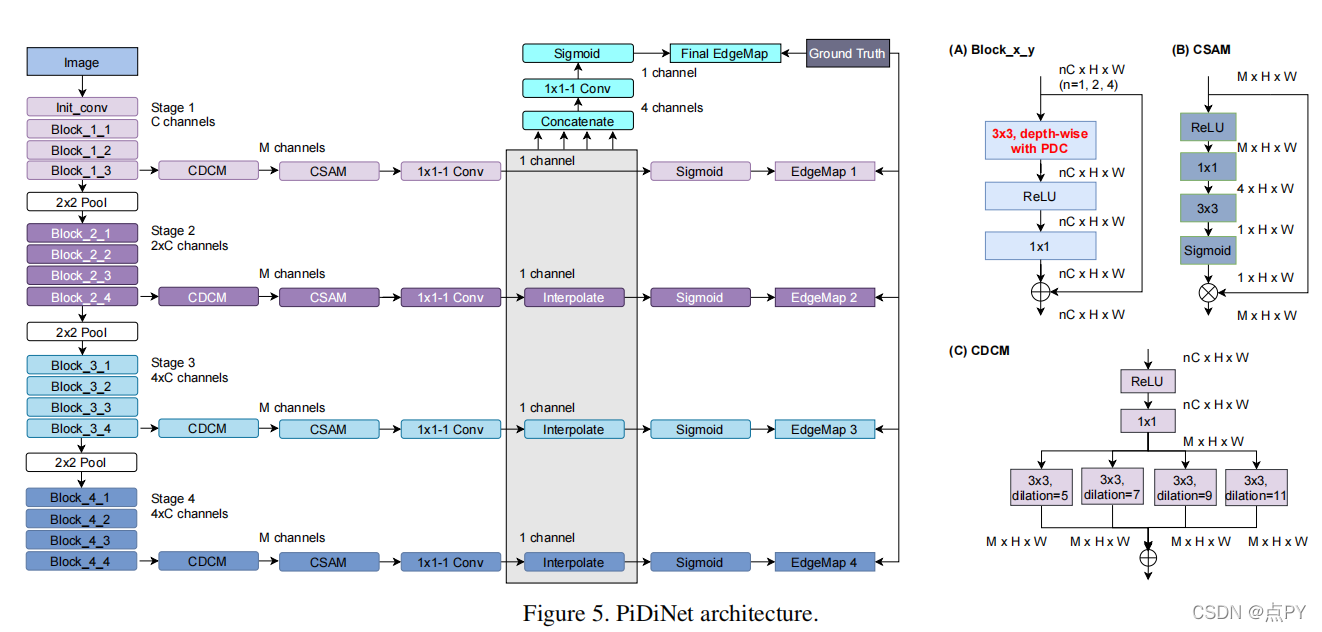
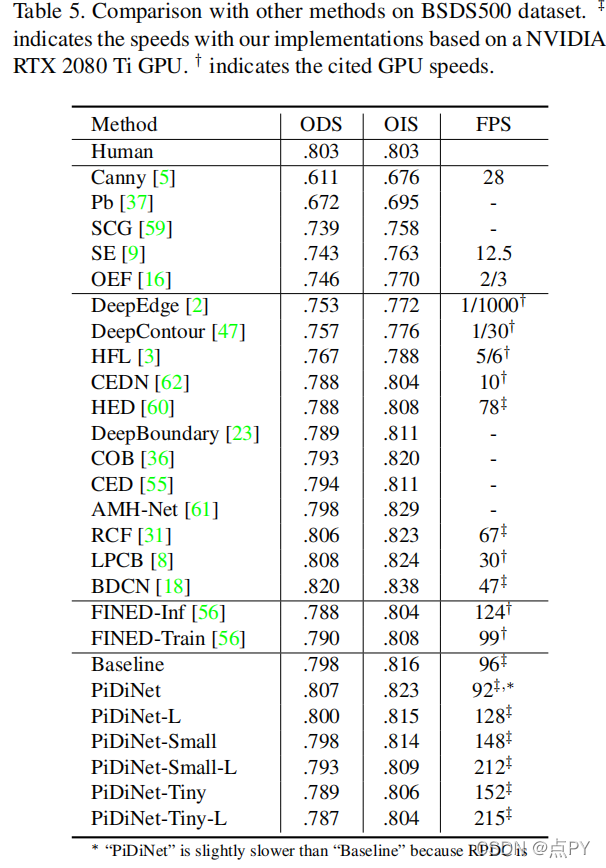
近年来,深度卷积神经网络(CNNs)具有丰富而抽象的边缘表示能力,可以实现人类水平的边缘检测性能。然而,基于CNN的边缘检测的高性能是通过一个大的预训练CNN主干实现的,这是消耗内存和能量。此外,令人惊讶的是,在快速发展的深度学习时代,传统的边缘探测器,如Canny、Sobel和LBP,之前的智慧很少被研究。为了解决这些问题,我们提出了一个简单、轻量级但有效的架构,称为像素差异网络(PiDiNet),用于有效的边缘检测。PiDiNet采用新的像素差卷积,将传统的边缘检测操作符集成到现代cnn中流行的卷积操作中,以提高任务性能,具有两者的优点。
HED-UNet: Combined Segmentation and Edge Detection for Monitoring the Antarctic Coastline(TGRS)
code : https://github.com/khdlr/HED-UNet
摘要
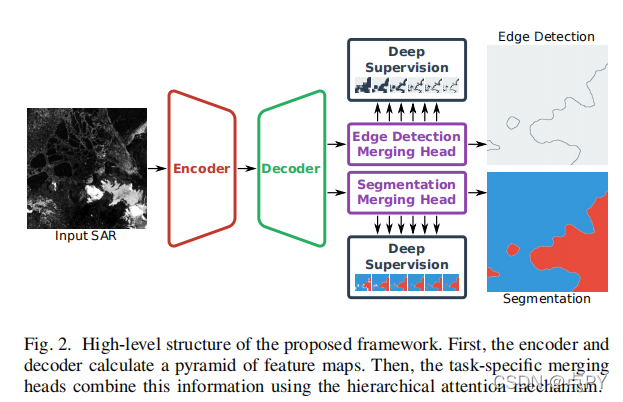
近年来,基于深度学习的海岸线检测算法已经开始超越传统的统计方法。然而,它们通常只作为单一用途的模型进行训练,以分割陆地和水或划定海岸线。与此相反,在执行手动海岸线检测时,人类注释者通常会保留分割和轮廓的心理地图。为了考虑这一任务的二偶性,我们设计了一个新的模型来将这两种方法结合在深度学习模型中。通过从语义分割框架(UNet)和边缘检测框架(HED)的主要构建块中获得灵感,这两个任务以一种自然的方式结合在一起。通过在多种分辨率下对侧预测进行深度监督,使训练有效。
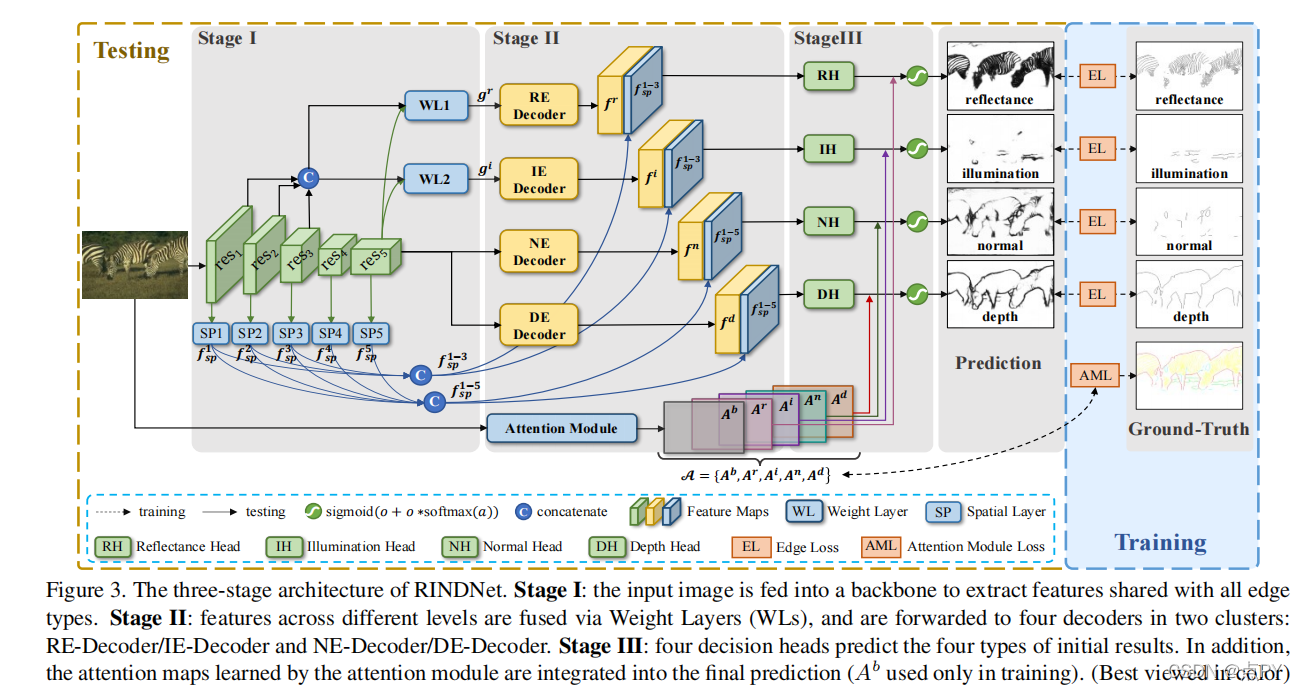
RINDNet: Edge Detection for Discontinuity in Reflectance, Illumination, Normal and Depth(ICCV)
code: https://github.com/MengyangPu/RINDNet
摘要:
边缘作为计算机视觉的基本组成部分,根据表面反射的不连续性可分为四种类型——表面反射、照明、表面正态线或深度。虽然在检测一般或个别边缘类型方面取得了很大的进展,但对所有四种边缘类型进行综合研究仍有待充分探索。在本文中,我们提出了一种新的神经网络解决方案,RINDNet,以联合检测所有四种类型的边。考虑到每种边类型的不同属性和它们之间的关系,RINDNet学习了每种边的有效表示,并分三个阶段工作。在阶段I中,RINDNet使用一个共同的主干来提取所有边共享的特征。
然后在第二阶段,它进行分支,通过相应的解码器为每个边缘类型准备鉴别特征。在第三阶段,每种类型的独立决策头汇总了前一阶段的特征来预测初始结果。此外,一个注意模块学习所有类型的注意映射,以捕获它们之间的潜在关系,并将这些映射与初始结果相结合,生成最终的边缘检测结果。为了进行训练和评估,我们构建了第一个公共基准,BSDS-RIND,并仔细注释了所有四种类型的边。在我们的实验中,与最先进的方法相比,RINDNet产生了很有希望的结果。补充的分析在补充材料中提出。

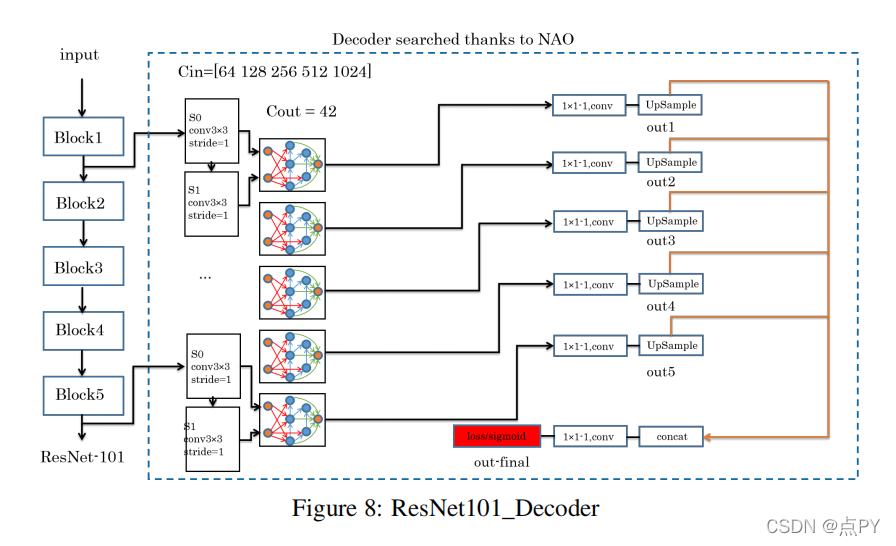
LEARNING DEEP MORPHOLOGICAL NETWORKS WITH NEURAL ARCHITECTURE SEARCH
code : https://github.com/giannifranchi/NAO_morpho
摘要
深度神经网络(DNNs)是通过依次执行线性和非线性过程来生成的。使用线性和非线性程序的组合是生成一个足够深的特征空间的关键。大多数的非线性算子都是激活函数或池化函数的推导函数。数学形态学是数学中的一个分支,它为各种图像处理问题提供了非线性算子。本文研究了在端到端深度学习框架中集成这些操作的效用。dnn的设计是为了获得特定工作的真实表示。形态操作符给出拓扑描述符,传达关于图像中描述的物体形状的显著信息。我们提出了一种基于元学习的方法,将形态学算子纳入dnn中。学习的架构展示了我们的新形态操作如何显著提高DNN在各种任务上的性能,包括图像分类和边缘检测。
2022
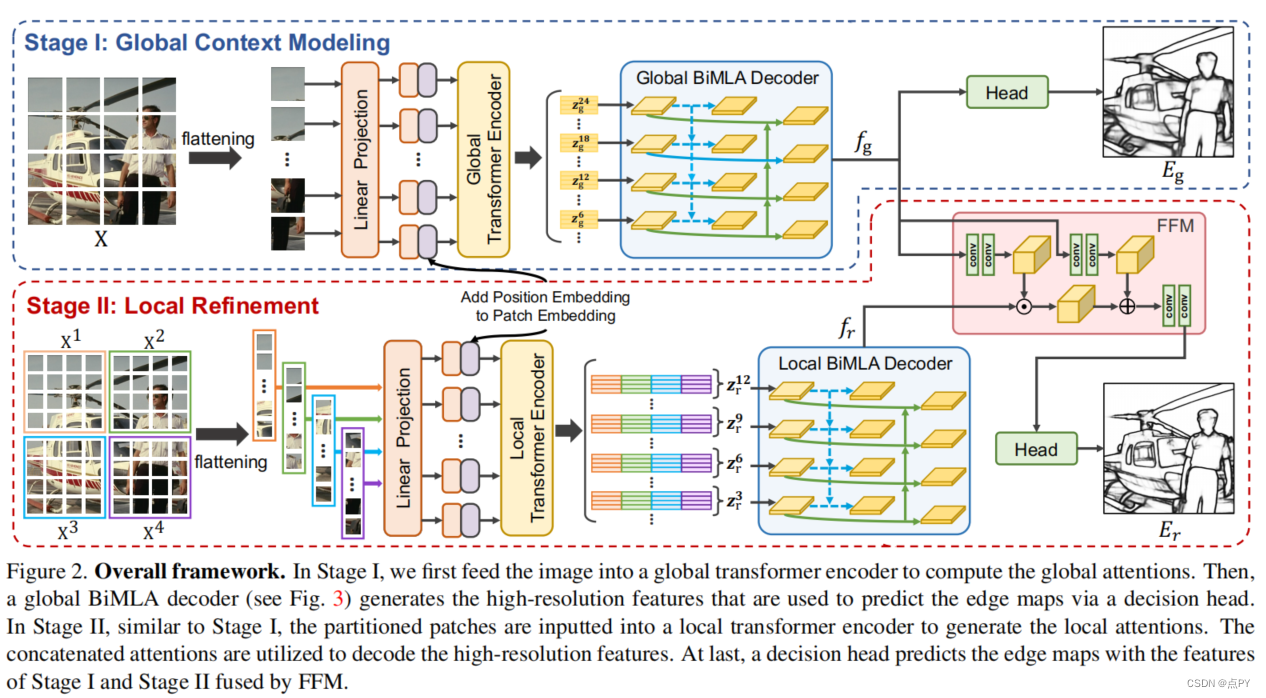
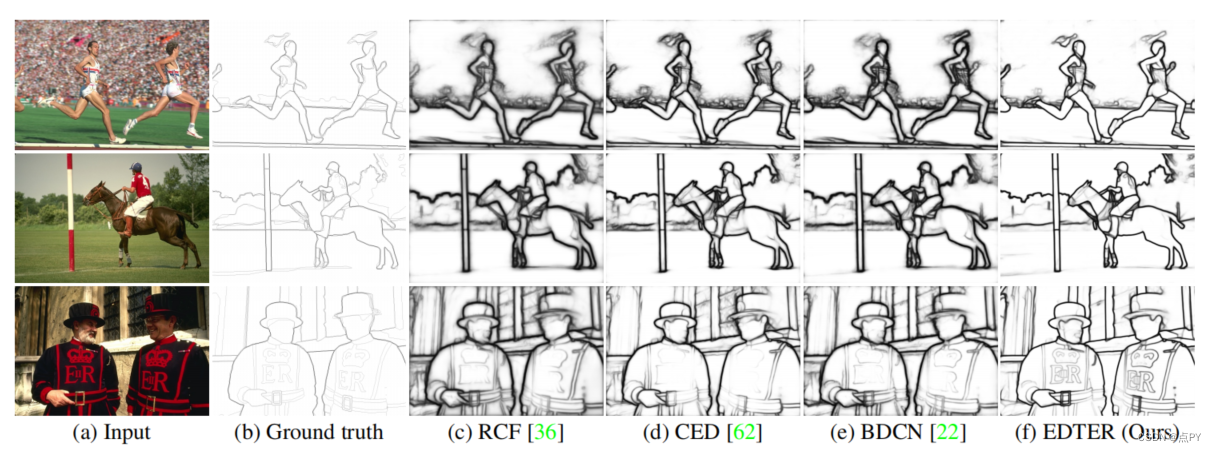
EDTER: Edge Detection with Transformer
code: https://paperswithcode.com/paper/edter-edge-detection-with-transformer
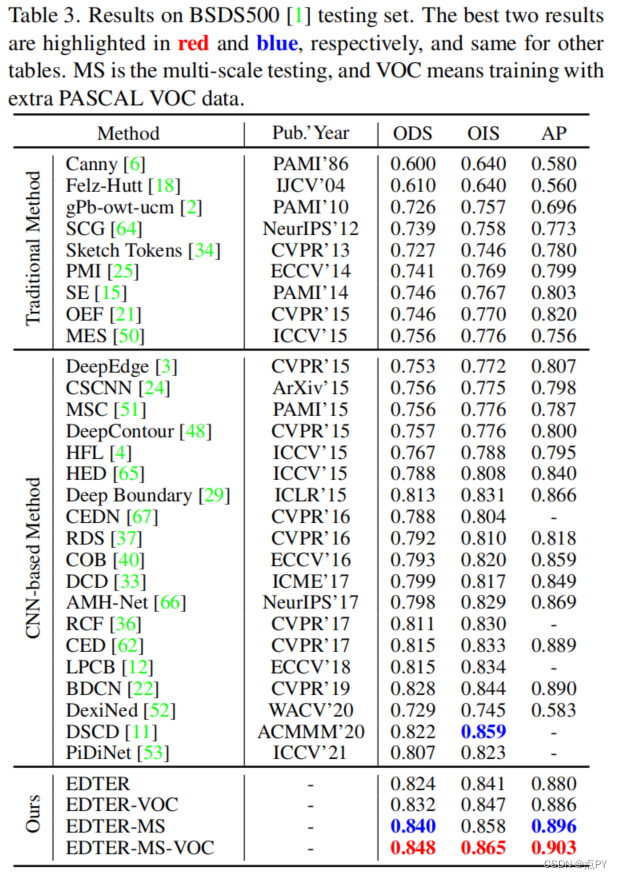
摘要:卷积神经网络通过逐步探索上下文和语义特征,在边缘检测方面取得了显著进展。然而,随着感受野的扩大,局部细节逐渐被抑制。最近,视觉变压器在捕获远程依赖关系方面显示出了良好的能力。受此启发,我们提出了一种新的基于变压器的边缘检测器,边缘检测变换器(EDTER),通过同时利用完整的图像上下文信息和详细的局部线索,来提取清晰、清晰的物体边界和有意义的边缘。EDTER分两个阶段工作。在阶段I中,一个全局转换器编码器用于捕获粗粒度图像补丁上的远程全局上下文。然后在第二阶段,一个本地变压器编码器工作在细粒度的补丁,以挖掘短程的局部线索。每个变压器编码器后面都有一个精心设计的双向多级聚合解码器,以实现高分辨率的特性。最后,通过特征融合模块将全局上下文和局部线索相结合,输入决策头进行边缘预测。在BSDS500、NYUDv2和多技术上的大量实验表明,EDTER与先进技术相比的优越性。
遮挡边缘检测
2007
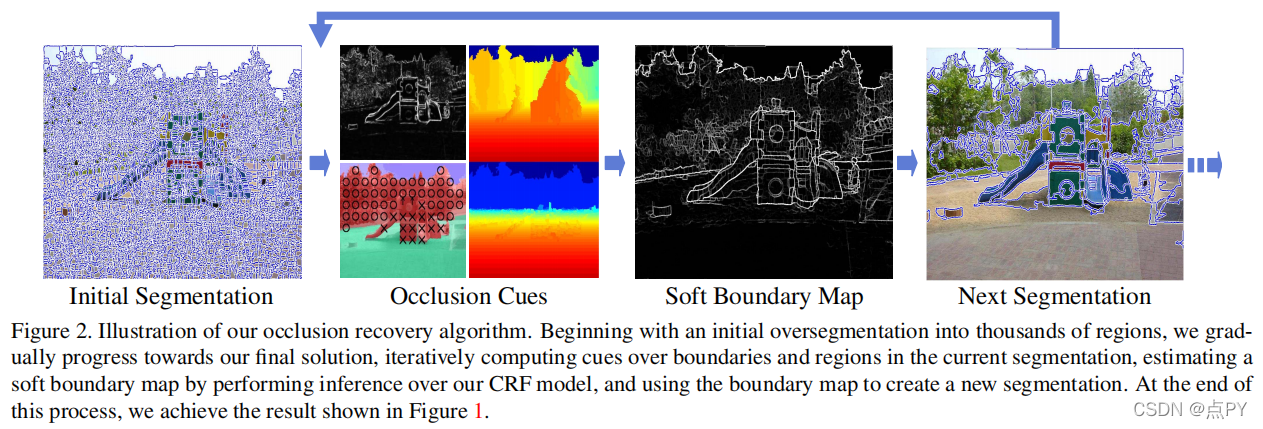
Recovering Occlusion Boundaries from a Single Image(ICCV)
开源地址: http://dhoiem.cs.illinois.edu/
摘要: 遮挡推理是日常生活中的一个重要方面,也是计算机视觉中的一个基本问题,它也是导航和物体搜索等任务所必需的遮挡推理。我们相信,人类从一幅图像中推断遮挡的惊人能力是基于本质上的3D解释。在本文中,我们的目标是恢复场景中独立结构的遮挡边界和深度排序。我们的方法是学习识别和标记遮挡边界使用传统的三维表面和深度线索和区域线索。由于其中一些线索需要良好的空间支持(即分割),我们逐渐创建更大的区域,并使用它们来改进在边界上的推理。我们的实验证明了一种基于场景的方法对遮挡推理的力量。
2016
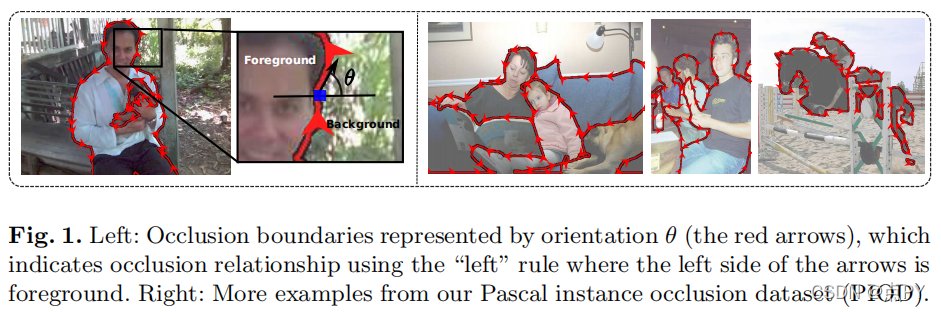
DOC: Deep OCclusion Estimation From a Single
code: https://github.com/pengwangucla/DOC
摘要: 在本文中,我们提出了一种称为DOC的深度卷积网络架构,它检测对象边界并估计遮挡关系(即边界的哪一边是前景,哪一边是背景)。具体来说,我们首先用一个二值边缘指示器来表示遮挡关系,表示对象边界,以及一个遮挡方向变量,用左侧规则表示遮挡关系,见图1。然后,我们的DOC网络利用局部和非局部图像线索来学习和估计这种表示,从而恢复遮挡关系。为了训练和测试DOC,我们使用帕斯卡VOC图像构建了一个大规模的实例遮挡边界数据集,我们称之为帕斯卡实例遮挡数据集(PIOD)。它包含10,000张图像,因此比现有的户外图像遮挡数据集大两个数量级。我们在PIOD和BSDS所有权数据集上测试了DOC的两种变体,并显示出它们的性能通常比最先进的方法多出5个AP。最后,我们进行了大量的实验,研究了BSDS和PIOD的多重设置和BSDS之间的转移,为进一步研究遮挡估计提供了更多的见解。
2018
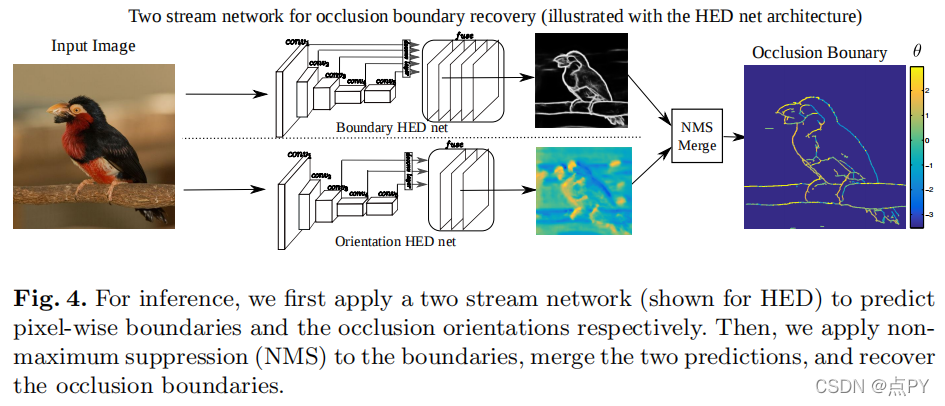
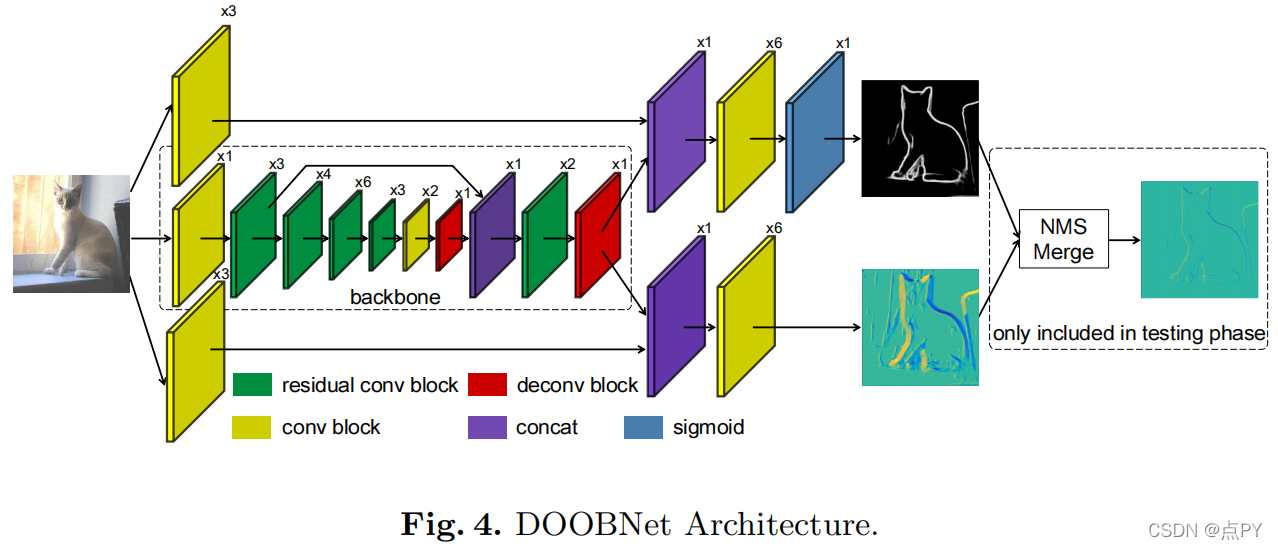
DOOBNet: Deep Object Occlusion Boundary Detection from an Image
code : https://github.com/GuoxiaWang/DOOBNet(Caffe)
https://github.com/yuzhegao/doob(PyTorch)
摘要:
目标遮挡边界检测是计算机视觉中一个基础和重要的研究问题。解决这个问题是具有挑战性的,因为我们遇到了极端的边界/非边界类不平衡。在本文中,我们提出通过用我们的注意力损失函数加权假阴性和假阳性例子的损失贡献来解决这类不平衡。我们还提出了一种统一的端到端多任务深度目标遮挡边界检测网络(DOOBNet),通过共享卷积特征来同时预测目标边界和遮挡方向。DOOBNet采用了具有跳跃连接的编码解码器结构,可以自动学习多尺度和多级特征。我们显著超过了PIOD数据集(ODSF-分数为0.702)和BSDS所有权数据集(ODSF-分数为0.555),并将PIOD数据集上的每幅图像的检测速度提高到0.037s。
APPD: Adaptive and Precise Pupil Boundary Detection using Entropy of Contour Gradients
2019
Occlusion-shared and Feature-separated Network for Occlusion Relationship Reasoning
code: https://github.com/buptlr/OFNet
摘要: 遮挡关系推理要求封闭的轮廓来表示对象,并要求每个轮廓像素的方向来描述对象之间的顺序关系。目前基于cnn的方法忽略了任务中的两个关键问题:(1)同时存在对这两个元素的相关性和区别,即遮挡边缘和遮挡方向;以及(2)对取向特征的探索不足。基于上述原因,我们提出了闭塞共享和特征分离网络(OFNet)。一方面,考虑到边缘和方向之间的相关性,设计了两个子网络来共享遮挡线索。另一方面,将整个网络分为两条路径,分别学习高级语义特征。此外,还提取了方向预测的上下文特征,表示前景和背景区域的双边线索。然后将双侧提示与遮挡提示融合,以精确定位目标区域。最后,设计了一个条带卷积来进一步聚合遮挡边缘周围场景的特征。所提出的OFNet显著地推进了在PIOD和BSDS所有权数据集上的最新方法。
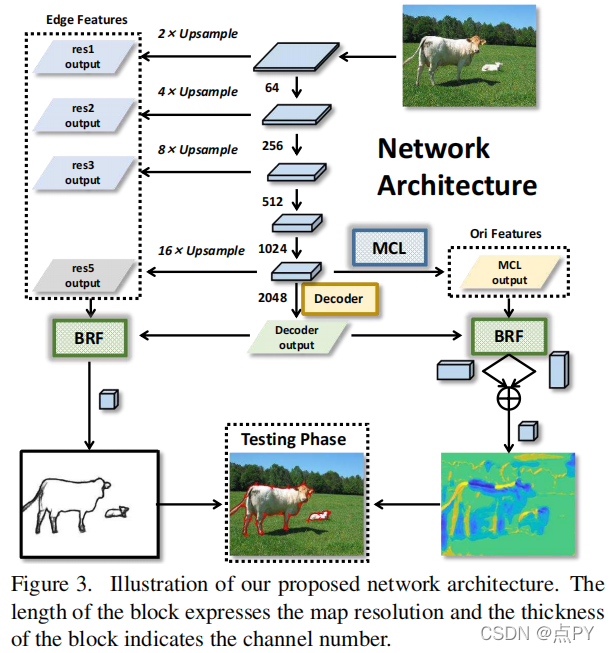
CONTEXT-CONSTRAINED ACCURATE CONTOUR EXTRACTION FOR OCCLUSION EDGE DETECTION
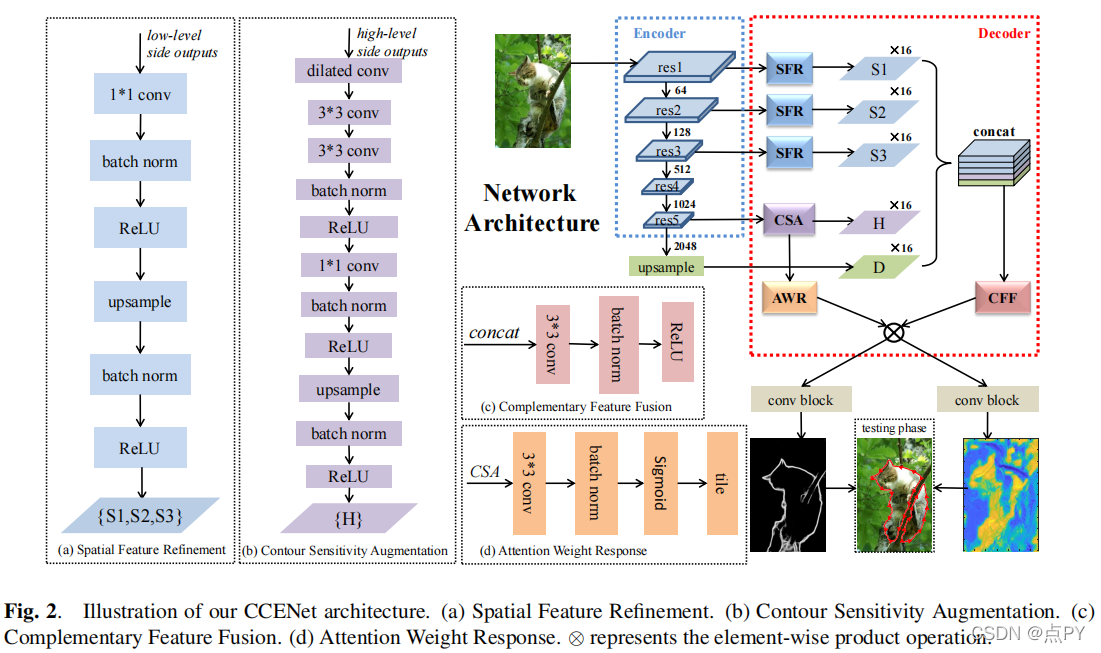
摘要: 遮挡边缘检测需要精确的位置和轮廓的上下文约束。现有的基于cnn的管道没有利用自适应方法来过滤由低水平特征引入的噪声。为了解决这一困境,我们提出了一种新的上下文约束精确轮廓提取网络(CCENet)。通过两个提取块分别保留空间细节和轮廓敏感的上下文。然后,利用精心设计的融合模块来集成特性,在恢复细节和消除杂乱方面发挥互补作用。注意机制的权重响应最终被用来增强遮挡轮廓和抑制噪声。所提出的CCENet在PIOD和BSDS所有权数据集上显著超过了最先进的方法。
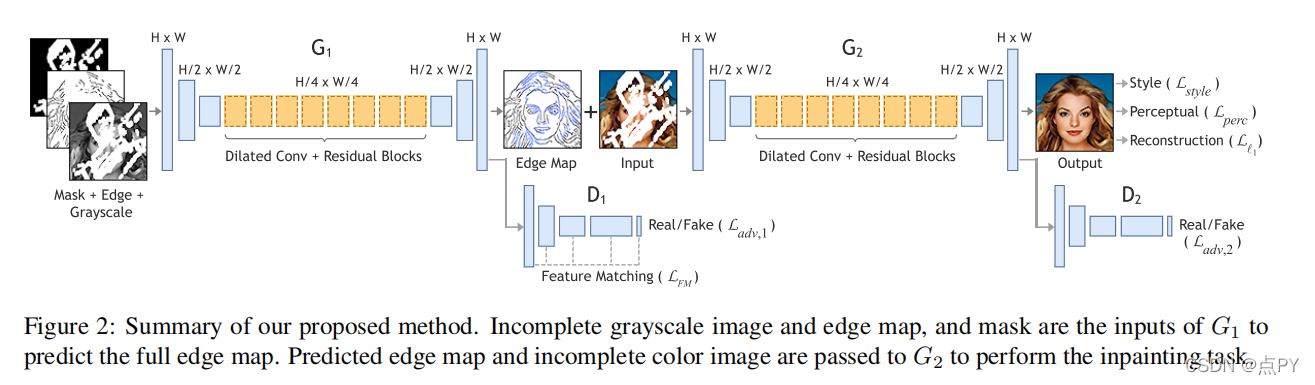
EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning
code: https://paperswithcode.com/paper/edgeconnect-generative-image-inpainting-with
摘要: 在过去的几年里,深度学习技术在图像绘制方面取得了显著的改进。然而,许多这些技术不能重建合理的结构,因为它们通常是过度平滑和/或模糊的。本文提出了一种新的图像绘制方法,可以更好地再现显示精细细节的填充区域。我们提出了一个两阶段对抗模型边缘连接,包括一个边缘生成器和一个图像补全网络。边缘生成器对图像缺失区域的边缘(包括规则和不规则)产生幻觉,图像补全网络使用幻觉边缘作为先验来填充缺失区域。我们对公开的数据集CelebA、地点2和巴黎街景的模型进行了端到端评估,并表明它在定量和定性上都优于目前最先进的技术。

论文的贡献:
- 一种边缘生成器,能够在给定图像其余部分的边缘和灰度像素强度的缺失区域中产生幻觉。
- 一种图像补全网络,它将缺失区域的边缘与图像其余部分的颜色和纹理信息相结合来填充缺失区域。
- 一种端到端可训练的网络,它结合了边缘生成和图像补全,以填补显示出精细细节的缺失区域。
2020
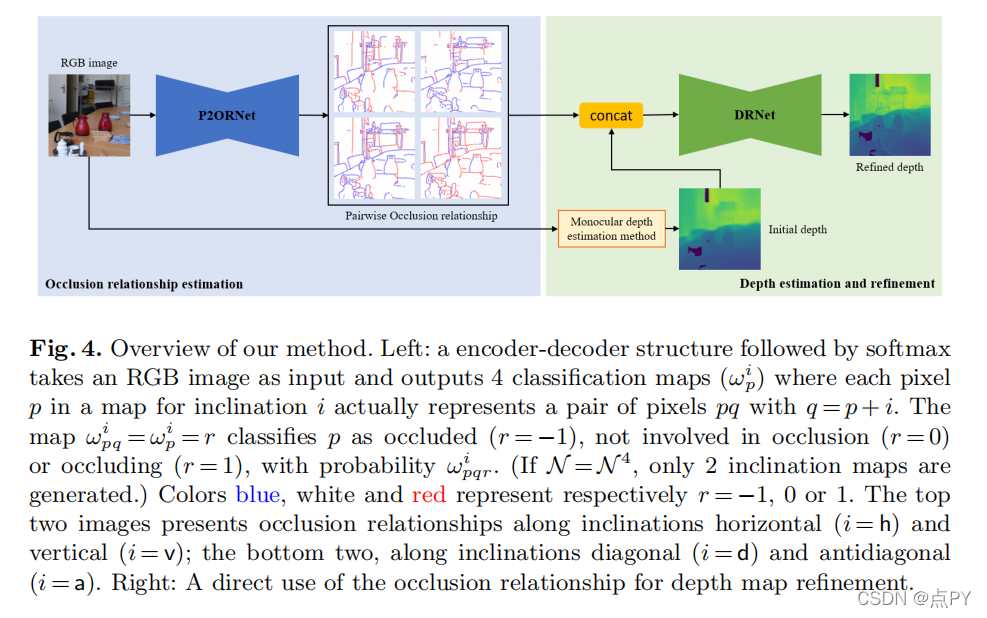
Pixel-Pair Occlusion Relationship Map(P2ORM): Formulation, Inference & Application
code: https://github.com/tim885/P2ORM
摘要: 我们将二维图像中几何遮挡的概念形式化(即忽略语义),并提出了一种新的通过像素对遮挡关系的遮挡边界和遮挡方向的统一公式。前者提供了一种生成大规模精确遮挡数据集的方法,并在后者的基础上,提出了一种估计单一图像任务无关像素级遮挡关系的新方法。在各种数据集上的实验表明,我们的方法在此任务上优于现有的方法。为了进一步说明我们的公式的价值,我们还提出了一种新的深度图细化方法,以不断提高目前最先进的单眼深度估计方法的性能。
论文的贡献:
(1)二维图像中几何遮挡的形式化;
(2)一种在像素对水平上捕获遮挡关系的新公式,从中可以计算通常的边界和方向;
(3)是一种在几个数据集上优于最先进的遮挡估计方法;
(4)该公式的相关性的应用不断提高了最先进的单眼深度估计方法的性能。
2021
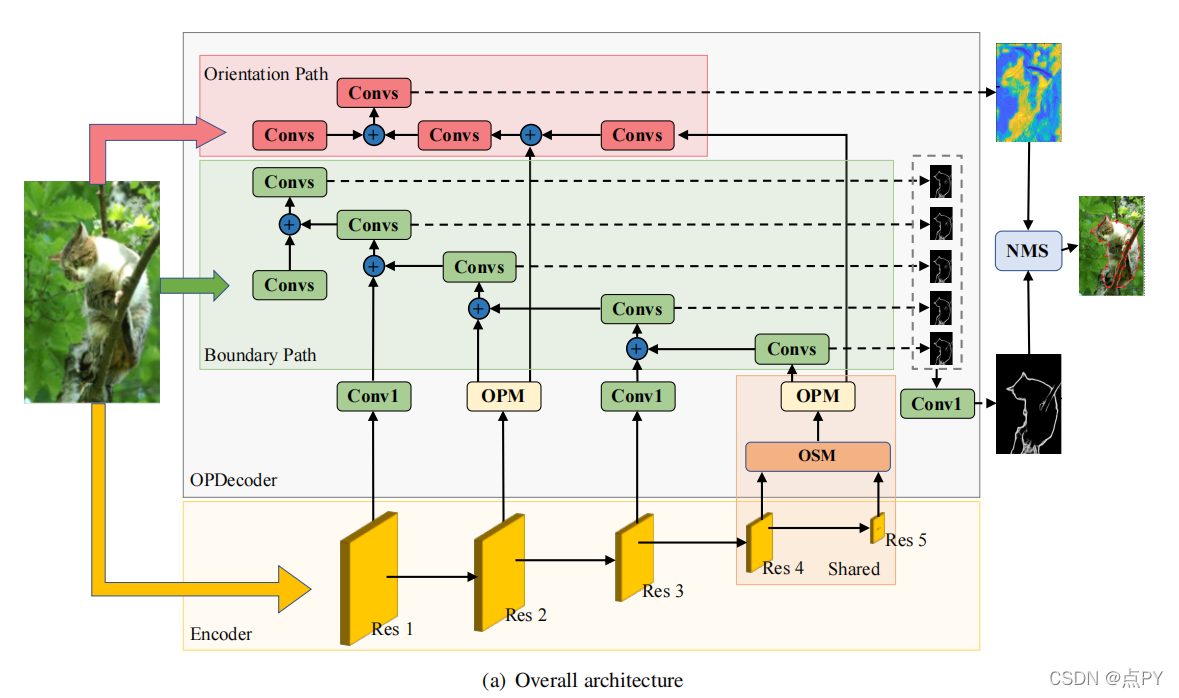
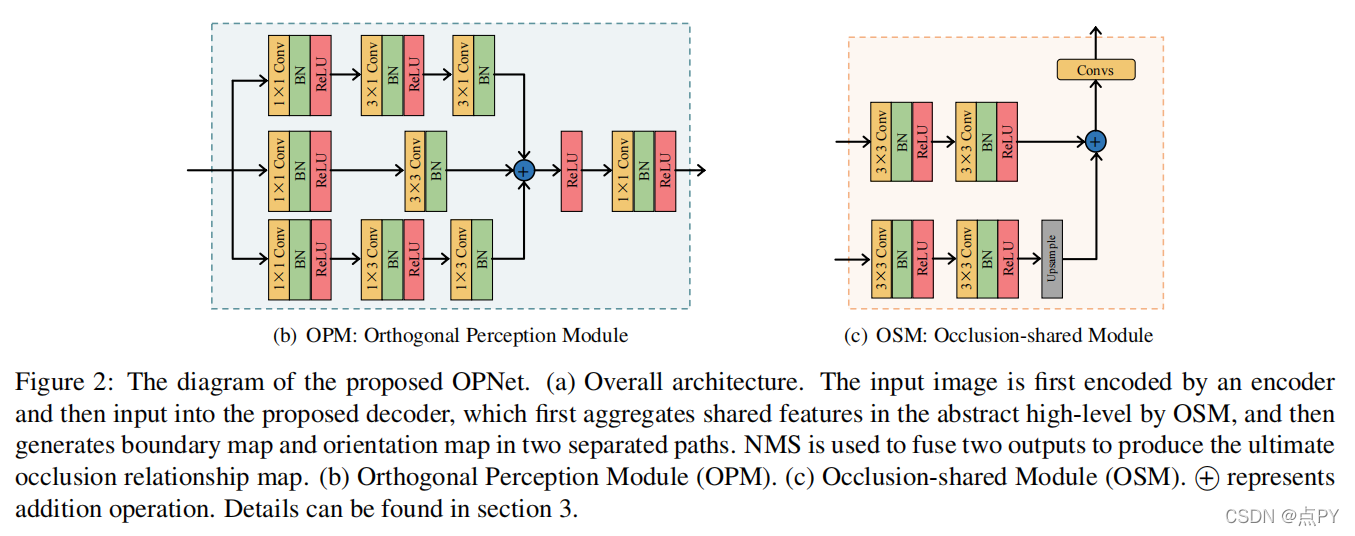
MT-ORL: Multi-Task Occlusion Relationship Learning
code: https://github.com/fengpanhe/mt-orl
摘要: 由于图像中边界的稀疏性,检索单个图像中对象之间的遮挡关系具有挑战性。我们在现有的工作中观察到两个关键问题:一是缺乏能够利用两个子任务之间解码器阶段有限耦合量的架构,即遮挡边界提取和遮挡方向预测,二是遮挡方向的表示不当。在本文中,我们提出了一种新的阻塞共享路径分离网络(OPNet),通过利用共享的高级特征中的丰富遮挡线索和任务特定的低层次特征中的结构化空间信息来解决第一个问题。然后,我们设计了一个简单但有效的正交遮挡表示(OOR)来解决第二个问题。在标准的PIOD/BSDS所有权数据集上,我们的方法超过了6.1%/8.3%的边界a方法和6.5%/10%的定向方法。
论文的贡献:
- 我们重新考虑遮挡关系推理的固有特性,与两个子任务相关:遮挡边界提取和遮挡方向回归。这促使我们提倡一种新的遮挡共享和路径分离网络(OPNet),该网络具有视觉遮挡推理的辨别能力和表达能力的替代方案。
- 我们进一步提出了鲁棒正交遮挡表示的预测遮挡方向(OOR),解决了端点误差和角度周期性问题。
- 该方法在PIOD[35]和BSDS所有权数据集[27]上都很有效,提供了明显更好的性能。
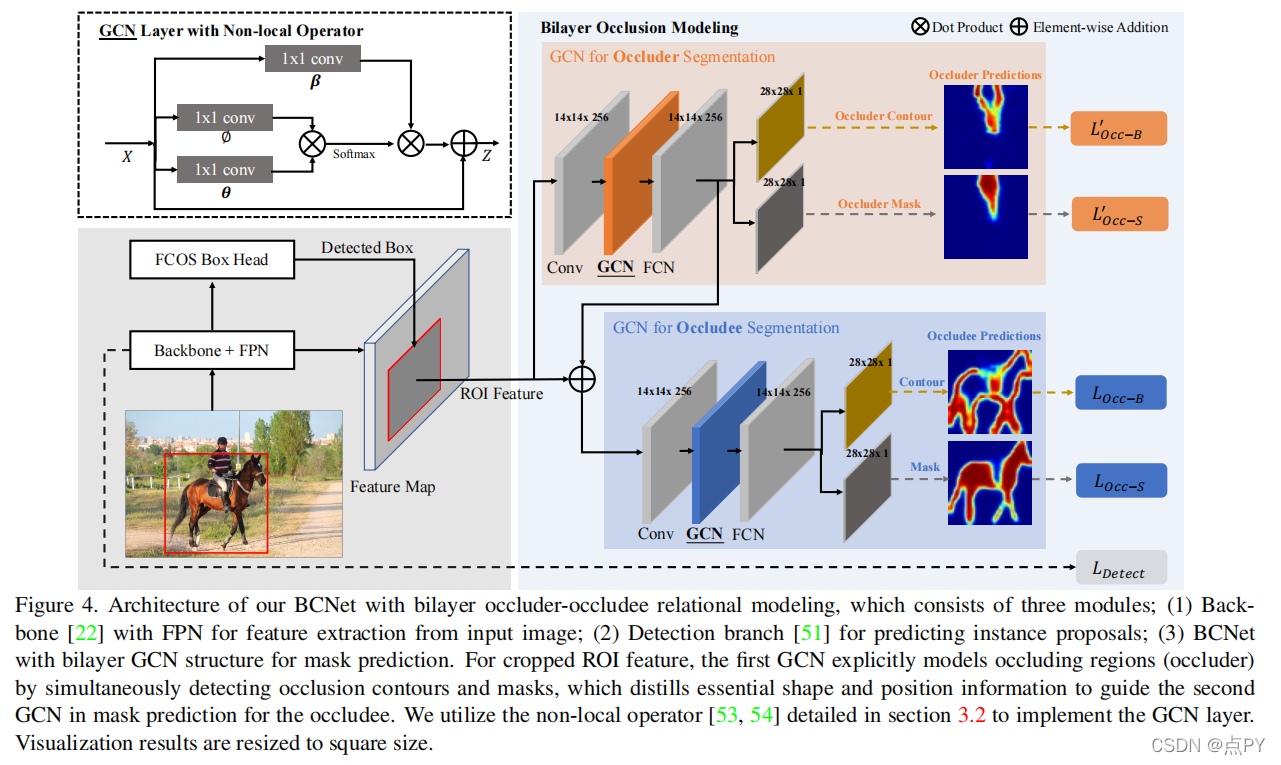
Deep Occlusion-Aware Instance Segmentation with Overlapping BiLayers
code: https://github.com/lkeab/BCNet
摘要: 分割高度重叠的对象是具有挑战性的,因为通常没有区分真实对象的对象轮廓和遮挡边界。与之前的双阶段实例分割方法不同,我们将图像形成建模为两个重叠层的组成,并提出了双层卷积网络(BCNet),其中顶层GCN层检测遮挡对象(遮挡封堵器),底层GCN层推断部分遮挡实例(八封堵器)。利用双层结构的遮挡关系显式建模自然地解耦了遮挡和遮挡实例的边界,并在掩模回归过程中考虑了它们之间的相互作用。我们验证了双层解耦在具有不同骨架和网络层选择的起始位置和两阶段目标检测器上的有效性。


















 6920
6920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











