







 超级会员免费看
超级会员免费看
文章目录
Why TensorRT
训练对于深度学习来说是为了获得一个性能优异的模型,其主要的关注点在于模型的准确度等指标。推理则不一样,其没有了训练中的反向迭代过程,是针对新的数据进行预测,而我们日常生活中使用的AI服务都是推理服务。相较于训练,推理的关注点不一样,从而也给现有技术带来了新的挑战:

根据上图可知,推理更关注的是高吞吐率、低响应时间、低资源消耗以及简便的部署流程,而TensorRT就是用来解决推理所带来的挑战以及影响的部署级的解决方案。
TensorRT部署流程

TensorRT的部署分为两个部分:
-
优化训练好的模型并生成计算流图
-
使用TensorRT Runtime部署计算流图
关于这个流程很自然我们会想到以下几个问题:
-
TensorRT支持什么框架训练出来的网络模型呢?
-
TensorRT支持什么网络结构呢?
-
TensorRT优化器做了哪些优化呢?
-
TensorRT优化好的计算流图可以运行在什么设备上呢?
TensorRT之大胃王

输入篇之网络框架:TensorRT3支持所有常见的深度学习框架包括Caffe、Chainer、CNTK、MXnet、PaddlePaddle、Pytorch、TensorFlow以及Theano。
输入篇之网络层:TensorRT3支持的网络层包括

输入篇之接口方式:TensorRT3支持模型导入方式包括C++ API、Python API、NvCaffeParser和NvUffParser
输出篇之支持系统平台:TensorRT3支持的平台包括Linux x86、Linux aarch64、Android aarch64和QNX aarch64。
输出篇之支持硬件平台:TensorRT3可以运行在每一个GPU平台,从数据中心的Tesla P4/V100到自动驾驶和嵌入式平台的DrivePX及TX1/TX2。
TensorRT模型导入流程

如上图所示,模型的导入方法可以根据框架种类分成三种:Caffe、TensorFlow和其他。
caffe
-
使用C++/Python API导入模型:通过代码定义网络结构,并载入模型weights的方式导入;
-
使用NvCaffeParser导入模型:导入时输入网络结构prototxt文件及caffemodel文件即可。
TensorFlow
-
训练完成后,使用uff python接口将模型转成uff格式,之后使用NvUffParaser导入;
-
对于TensorFlow或者keras(TensorFlow后端)的,利用Freeze graph来生成.pb(protobuf)文件,之后使用convert-to-uff工具将.pb文件转化成uff格式,然后利用NvUffParaser导入。
其他框架
使用C++/Python API导入模型:通过代码定义网络结构,载入模型weights的方式导入。以Pytorch为例,在完成训练后,通过stat_dict()函数获取模型的weights,从而在定义网络结构时将weights载入。
注:weights文件是保存的C++ Map对象,该对象定义为:
std::map<std::string, Weights>
其中Weights类型是在NvInfer.h中定义,为存储weights的array。
TensorRT优化细节
Layer & Tensor Fusion
网络模型在导入至TensorRT后会进行一系列的优化,主要优化内容如下图所示。

TensorRT在获得网络计算流图后会针对计算流图进行优化,这部分优化不会改变图中最底层计算内容,而是会去重构计算图来获得更快更高效的执行方式,即计算不变优化计算方法。
以下图为例:

深度学习框架在做推理时,会对每一层调用多个/次功能函数。而由于这样的操作都是在GPU上运行的,从而会带来多次的CUDA Kernel launch过程。相较于Kernel launch以及每层tensor data读取来说,kernel的计算是更快更轻量的,从而使得这个程序受限于显存带宽并损害了GPU利用率。
TensorRT通过以下三种方式来解决这个问题:
-
Kernel纵向融合:通过融合相同顺序的操作来减少Kernel Launch的消耗以及避免层之间的显存读写操作。如上图所示,卷积、Bias和Relu层可以融合成一个Kernel,这里称之为CBR。
-
Kernel横向融合:TensorRT会去挖掘输入数据且filter大小相同但weights不同的层,对于这些层不是使用三个不同的Kernel而是使用一个Kernel来提高效率,如上图中超宽的1x1 CBR所示。
-
消除concatenation层,通过预分配输出缓存以及跳跃式的写入方式来避免这次转换。
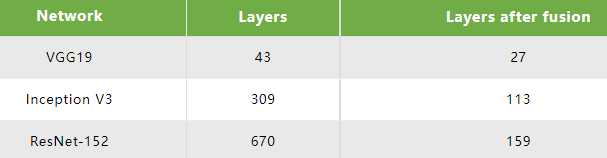
通过这样的优化,TensorRT可以获得更小、更快、更高效的计算流图,其拥有更少层网络结构以及更少Kernel Launch次数。下表列出了常见几个网络在TensorRT优化后的网络层数量,很明显的看到TensorRT可以有效的优化网络结构、减少网络层数从而带来性能的提升。
FP16 & INT8 精度校准
大多数的网络都是使用FP32进行模型训练,因此模型最后的weights也是FP32格式。但是一旦完成训练,所有的网络参数就已经是最优,在推理过程中是无需进行反向迭代的,因此可以在推理中使用FP16或者INT8精度计算从而获得更小的模型,低的显存占用率和延迟以及更高的吞吐率。
TensorRT可以采用FP32、FP16和INT8精度部署模型,只需要在uff_to_trt_engine函数中指定相应数据类型即可:
-
对于FP32, 使用 trt.infer.DataType.FLOAT.
-
对于FP16 指令 以及 Volta GPU内的Tensor Cores, 使用 trt.infer.DataType.HALF
-
对于INT8, 使用 trt.infer.DataType.INT8.
Kernel Auto-Tuning
TensorRT会针对大量的Kernel进行参数优化和调整。例如说,对于卷积计算有若干种算法,TensorRT会根据输入数据大小、filter大小、tensor分布、batch大小等等参数针对目标平台GPU进行选择和优化。
Dynamic Tensor Memory
TensorRT通过为每一个tensor在其使用期间设计分配显存来减少显存的占用增加显存的复用率,从而避免了显存的过度开销以获得更快和高效的推理性能。
优化结果

上图为基于Resnet50网络,分别在CPU、V100+TensorFlow、V100+TensorRT上进行推理时的性能比较,纵轴为每秒处理的图片数量。相较于CPU和TensorFlow,TensorRT可以带来40倍和18倍的吞吐率的提升,而这部分的提升只需要在拥有GPU的前提下使用TensorRT即可免费获得。
TensorRT 部署方法
完成TensorRT优化后可以得到一个Runtime inference engine,这个文件可以被系列化保存至硬盘中,而这个保存的序列化文件我们称之为“Plan”(流图),之所以称之为流图,因此其不仅保存了计算时所需的网络weights也保存了Kernel执行的调度流程。TensorRT提供了write_engine_to_file()函数以来保存流图。
在获得了流图之后就可以使用TensorRT部署应用。为了进一步的简化部署流程,TensorRT提供了TensorRT Lite API,它是高度抽象的接口会自动处理大量的重复的通用任务例如创建一个Logger,反序列化流图并生成Runtime inference engine,处理输入的数据。以下代码提供了一个使用TensorRT Lite API的范例教程,只需使用API创建一个Runtime Engine即可完成前文提到的通用任务,之后将需要推理的数据载入并送入Engine即可进行推理。
from tensorrt.lite import Engine
from tensorrt.infer import LogSeverity
import tensorrt
# Create a runtime engine from plan file using TensorRT Lite API
engine_single = Engine(PLAN="keras_vgg19_b1_FP32.engine",
postprocessors={"dense_2/Softmax":analyze})
images_trt, images_tf = load_and_preprocess_images()
results = []
for image in images_trt:
result = engine_single.infer(image) # Single function for inference
results.append(result)
参考
https://mp.weixin.qq.com/s/E5qbMsuc7UBnNmYBzq__5Q















 1034
1034











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









