






【三维重建】【深度学习】【数据集】基于COLMAP制作自己的NeuS(DTU格式)数据集
提示:最近开始在【三维重建】方面进行研究,记录相关知识点,分享学习中遇到的问题已经解决的方法。
文章目录
前言
DTU格式是NeuS网络模型训练使用的数据集格式之一,本文基于COLMAP软件展示从DTU格式数据集的制作到开始模型训练的完整流程。NeuS通过输入同一场景不同视角下的二维图片和相机位姿,对场景进行三维隐式建模,使用一种新的一阶近似无偏差的公式,从而即使没有掩模监督,也能进行更精确的表面重建。
下载安装colmap软件
下载COLMAP软件【下载地址】,本文使用的是Windows下的CUDA版本:  解压后双击打开COLMAP.bat,出现如下界面:
解压后双击打开COLMAP.bat,出现如下界面: 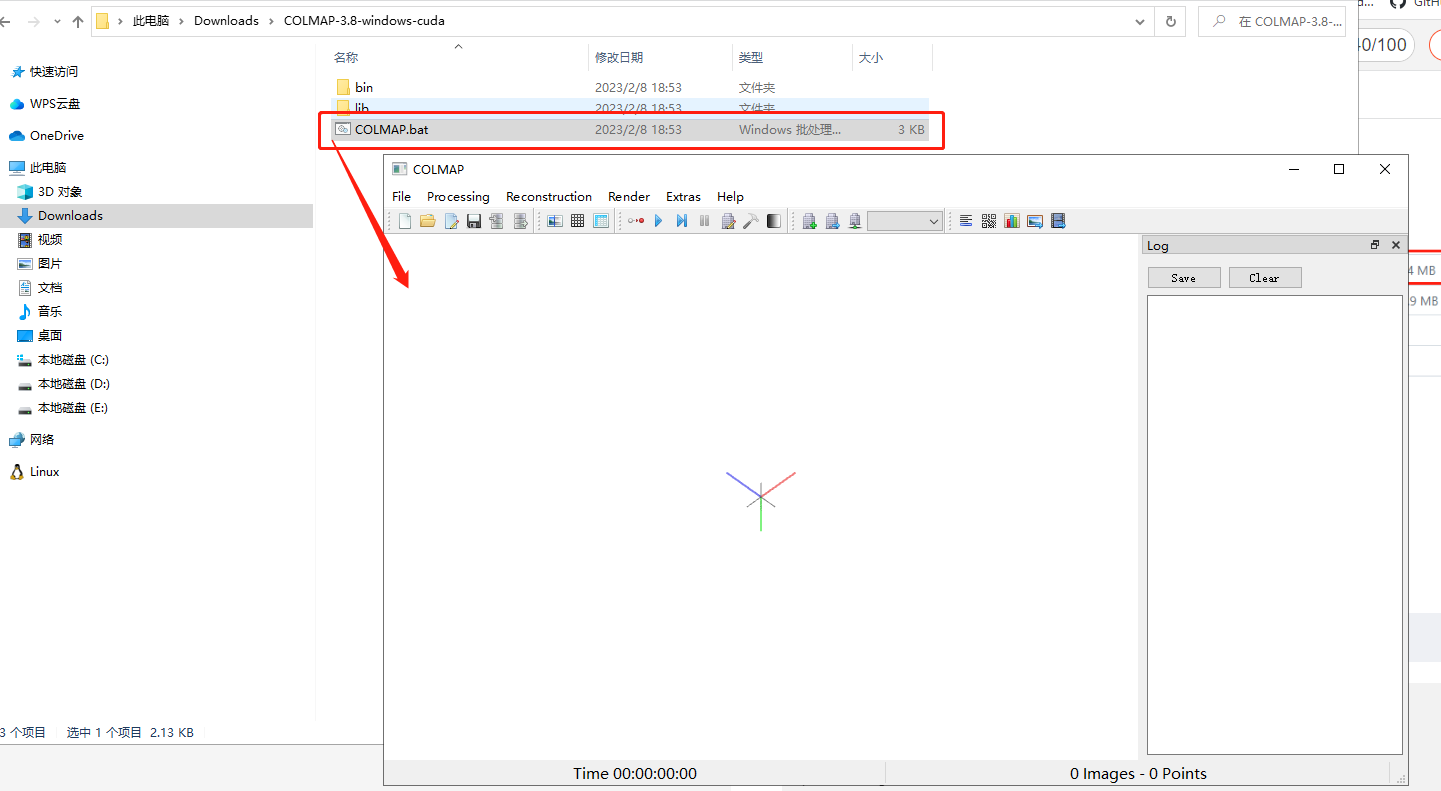 软件安装成功。
软件安装成功。
下载LLFF源码
# 可能需要科学上网从Github上直接git下载,博主下载到neus下 git clone https://github.com/Fyusion/LLFF.git # 激活虚拟环境 conda activate XXX # eg: activate neus pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-image pip install -i https://pypi.tuna.tsinghua.edu.cn/simple imageio
采集图片,使用colmap获取相机位姿
采集图像
本文制作数据集所需要的图片是用手机拍摄视频后抽帧获取的
# 激活虚拟环境 conda activate XXX # eg: activate neus # 安装opencv pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-python
新建文件Video_to_frame.py,通过执行以下代码完成抽帧(自定义抽帧的间隔)。
import os
import cv2
def extract_images(video_path, output_folder):
# 获取视频文件名
video_name = os.path.splitext(os.path.basename(video_path))[0]
# 新建文件夹
output_path = os.path.join(output_folder, video_name)
if not os.path.exists(output_path):
os.makedirs(output_path)
# 打开视频
cap = cv2.VideoCapture(video_path)
# 设置帧间隔
frame_interval = int(2)
# 逐帧提取并保存满足间隔要求的帧
count = 0
while cap.isOpened():
ret, frame = cap.read()
if ret:
print(frame_interval)
if count % frame_interval == 0:
image_name = os.path.join(output_path, f"{video_name}_{count//frame_interval}.jpg")
cv2.imwrite(image_name, frame)
count += 1
else:
break
cap.release()
if __name__ == '__main__':
video_path = 'C:/Users/XXX/Desktop/test_video/test.mp4' # 视频文件路径
output_folder = 'C:/Users/XXX/Desktop/test_frame' # 输出文件夹路径
extract_images(video_path, output_folder)
位姿计算
创建⼯程: 点击File -> New project 以新建一个项目。 1.点击New,选择一个文件夹(博主与测试图片放置在同一目录),设置工程名以新建工程数据文件。 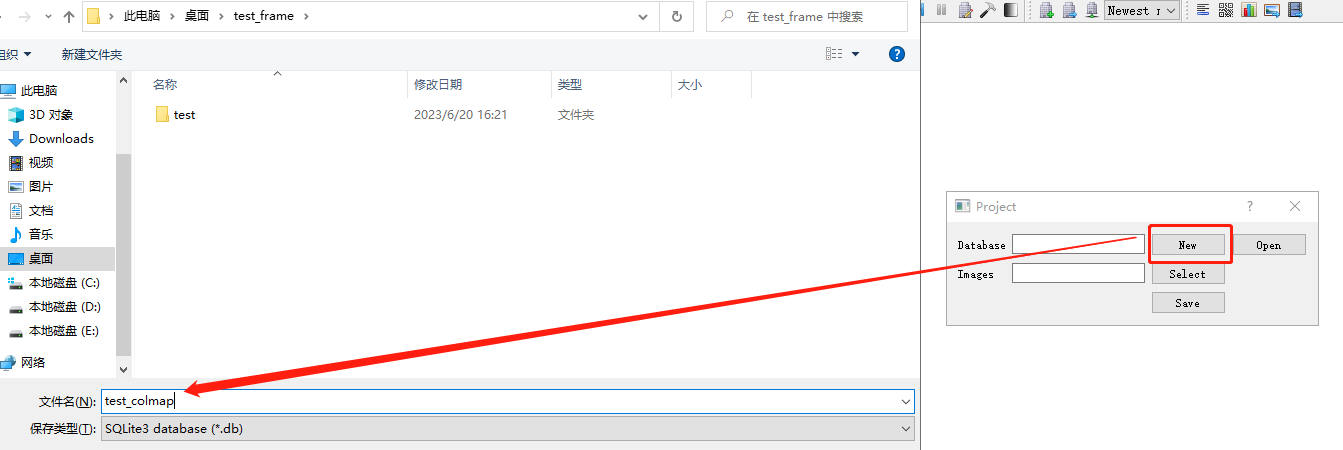 2.点击Select,选择刚才图像所在的⽂件夹,点击Save。
2.点击Select,选择刚才图像所在的⽂件夹,点击Save。 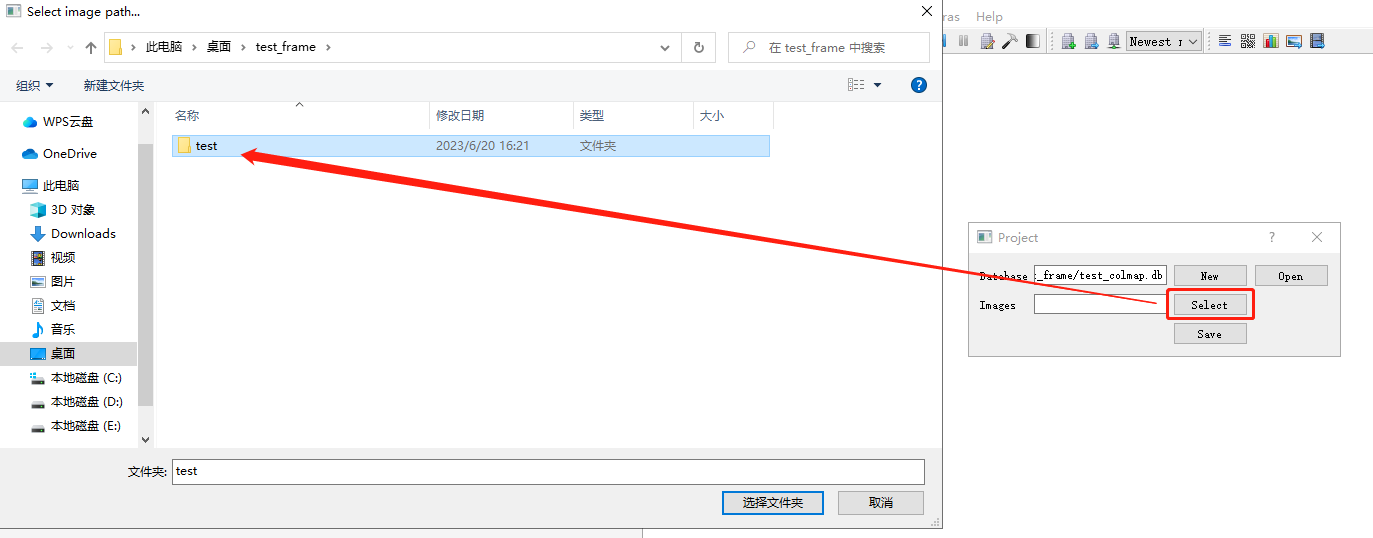 新建工程项目并配置完毕。
新建工程项目并配置完毕。
特征提取与匹配 1.图片特征提取,点击Processing -> Feature extraction,Camera model选择SIMPLE_PINHOLE,其他配置使用默认配置即可,点击Extract后,自动开始提取图片特征。 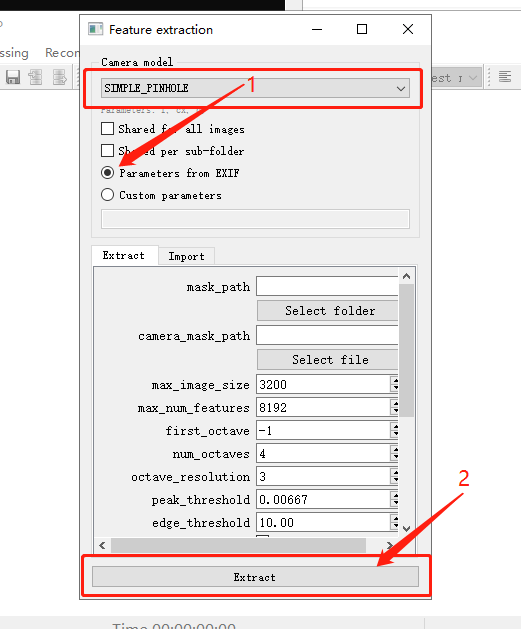 待特征提取完毕后关闭窗口。
待特征提取完毕后关闭窗口。
2.图片特征匹配,点击Processing -> Feature matching,使用默认配置直接点击Run进行特征匹配。 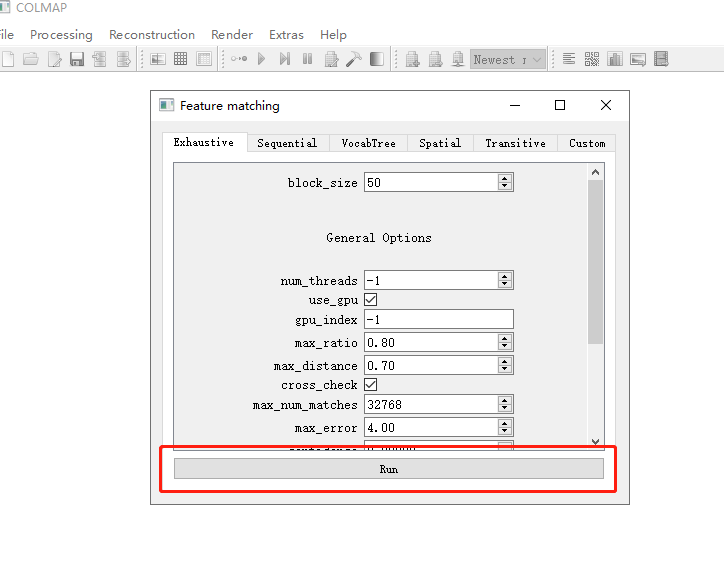 待特征匹配完毕后关闭窗口。
待特征匹配完毕后关闭窗口。
在右侧Log一栏中可以查看特征提取与匹配的进度,请确保过程中没有Erro报错
稀疏重建 点击Reconstruction -> Start reconstruction进行重建,在窗口中可以看到重建过程,此过程可能会持续一段时间。 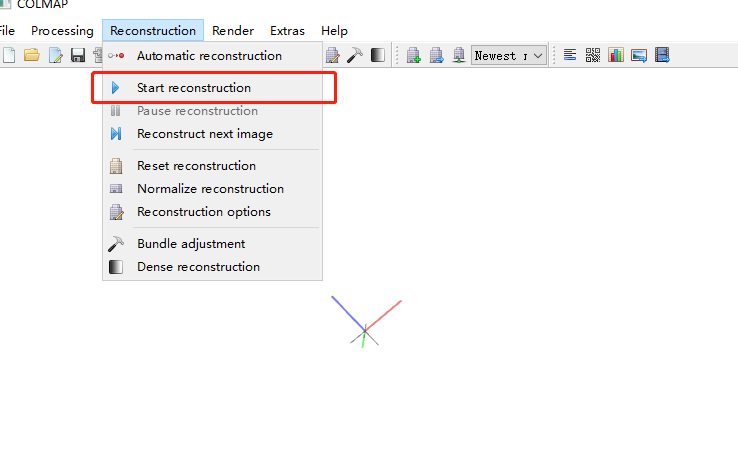 重建完毕后,得到如下图,通过右下角Images和Points可以大致判断是否重建成功。
重建完毕后,得到如下图,通过右下角Images和Points可以大致判断是否重建成功。 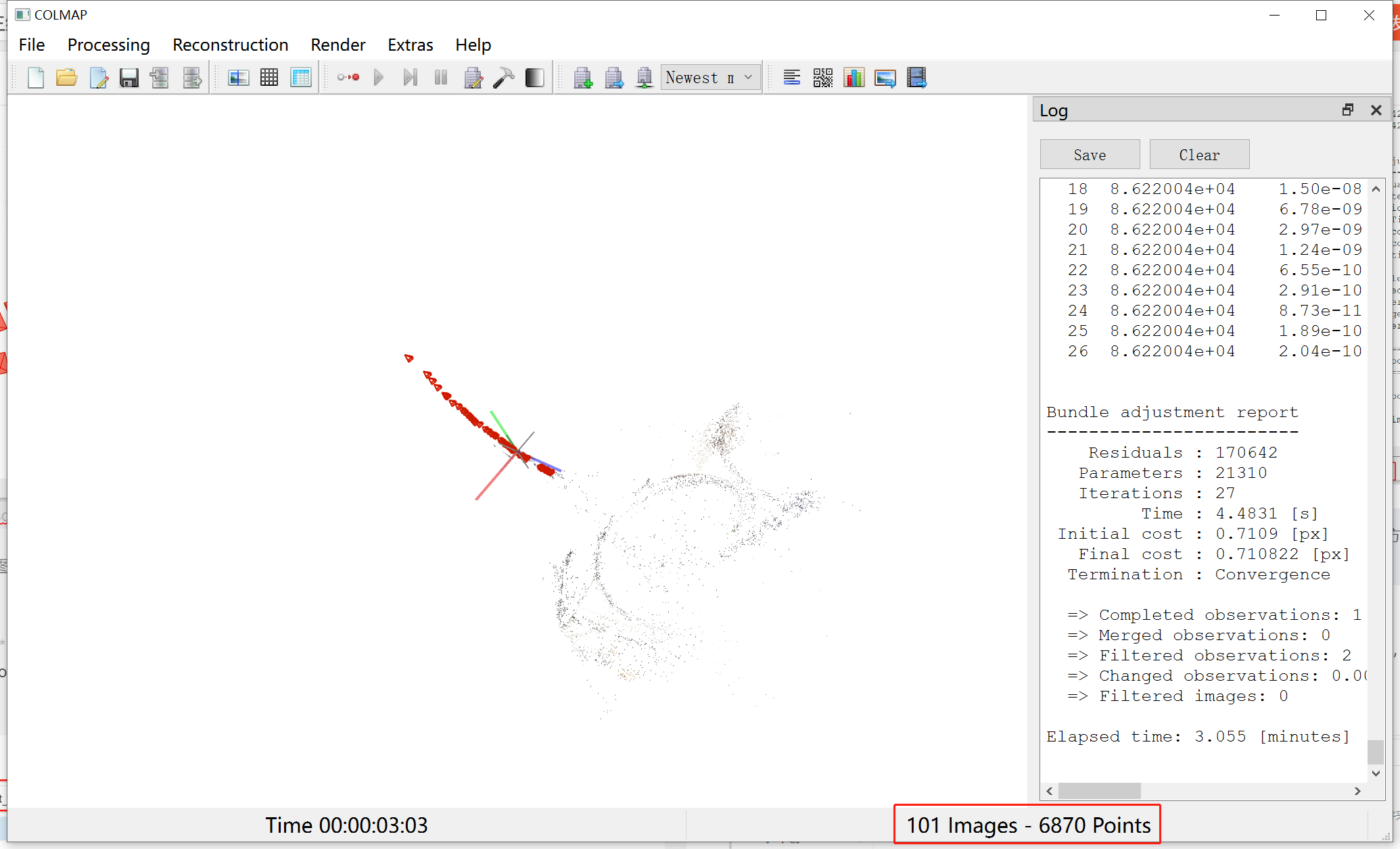
注意:匹配的位姿和图片数目不同在后续的步骤中会导致报错,博主会在下文中详细说明解决这个问题的方法,暂时继续跟着步骤走。
保存位姿和稀疏点 点击File -> Export model 以导出模型,在保存图像的文件夹所在的目录下新建/sparse/0/文件夹,选择该文件夹将模型导入到该目录下。  在/sparse/0/目录下得到如下文件,成功保存图像位姿。
在/sparse/0/目录下得到如下文件,成功保存图像位姿。 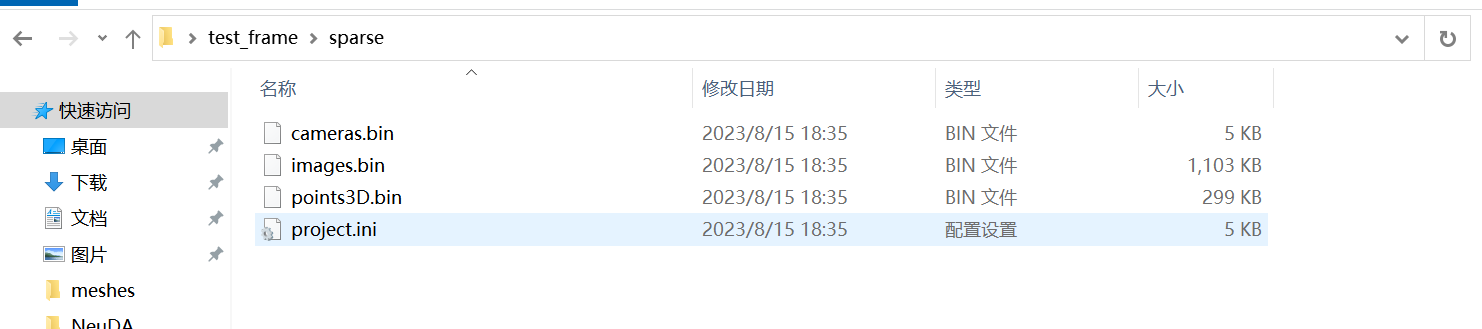
转成LLFF数据的格式
进入LLFF目录下,打开imgs2poses.py文件,新增如下内容,default=‘里面是sparse所在目录的绝对路径’,并将参数’scenedir’修改为是’- -scenedir’。 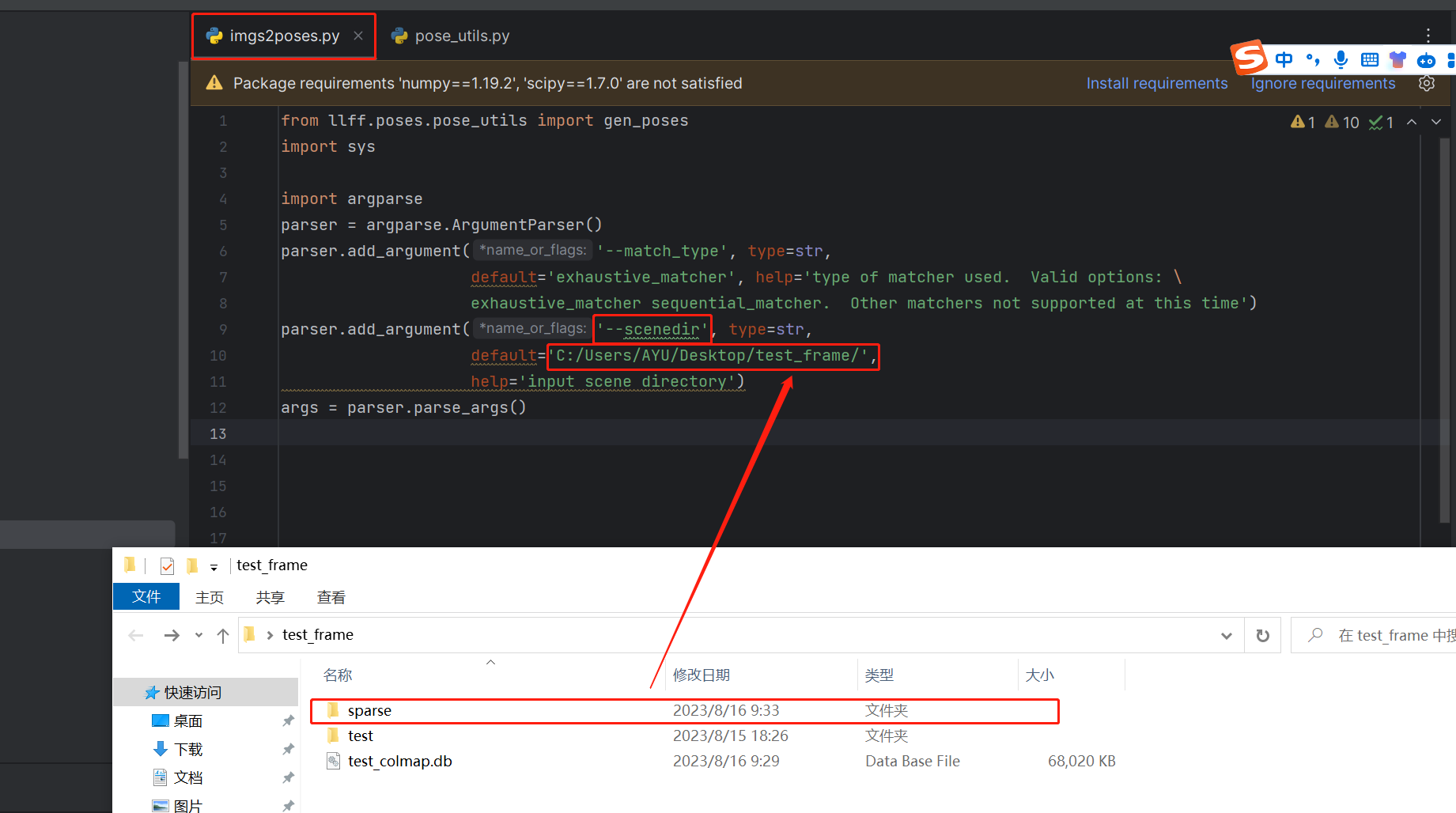 存放照片的文件夹名称必须是images,否则会出错,博主这里是test,所以需要修改成images。 在运行imgs2poses.py代码
存放照片的文件夹名称必须是images,否则会出错,博主这里是test,所以需要修改成images。 在运行imgs2poses.py代码
# 注意要在imgs2poses.py所在目录执行命令 python imgs2poses.py # 或者附带imgs2poses.py的路径 python XXXX\imgs2poses.py # eg: python LLFF\imgs2poses.py
假如不增加default=‘’。
# 在运行imgs2poses.py代码时,即使有默认值也必须传入路径(与scenedir参数有关) python imgs2poses.py "XXXX/XXXX/"
出现如下的问题:  这个问题是博主之前所说的匹配的位姿和图片数目不同导致的,博主在这里解决这个问题。通过在 LLFF/llff/poses/pose_utils.py 文件的32行左右添加如下代码:
这个问题是博主之前所说的匹配的位姿和图片数目不同导致的,博主在这里解决这个问题。通过在 LLFF/llff/poses/pose_utils.py 文件的32行左右添加如下代码:
#---------输出匹配到位姿的图片名--------- for i in np.argsort(names): print(names[i],end=' ') #---------输出匹配到位姿的图片名---------
添加代码位置如下图所示: 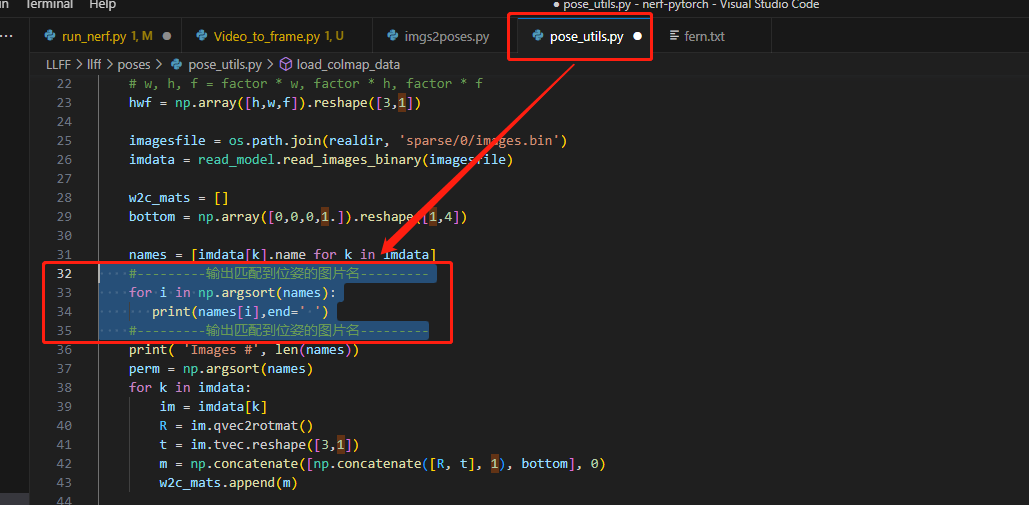 显示出所有匹配到位姿的图片。
显示出所有匹配到位姿的图片。  进入图像保存的目录,删除没有匹配到位姿的图像,而后重新进行 “位姿计算” 这一步骤。
进入图像保存的目录,删除没有匹配到位姿的图像,而后重新进行 “位姿计算” 这一步骤。  解决问题后,执行结果如下图所示:
解决问题后,执行结果如下图所示: 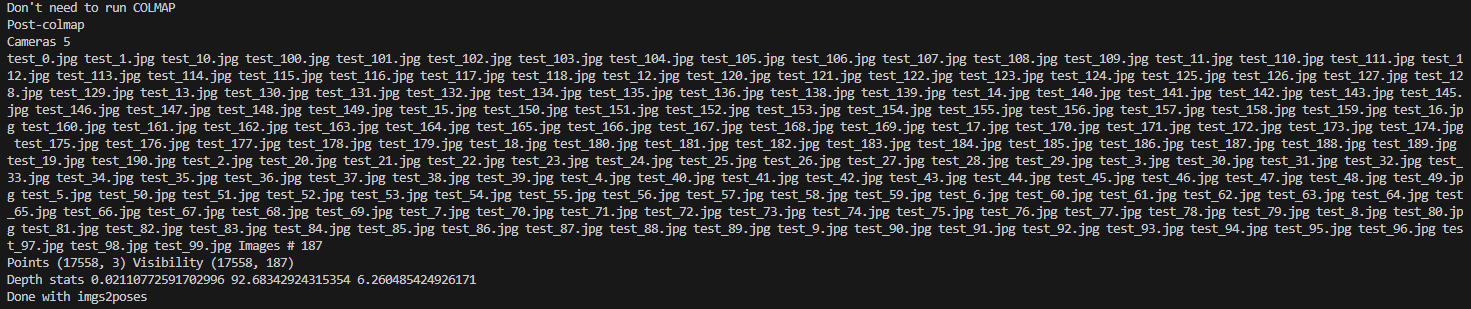 生成有关图像位姿的npy文件,格式转换步骤完毕。
生成有关图像位姿的npy文件,格式转换步骤完毕。 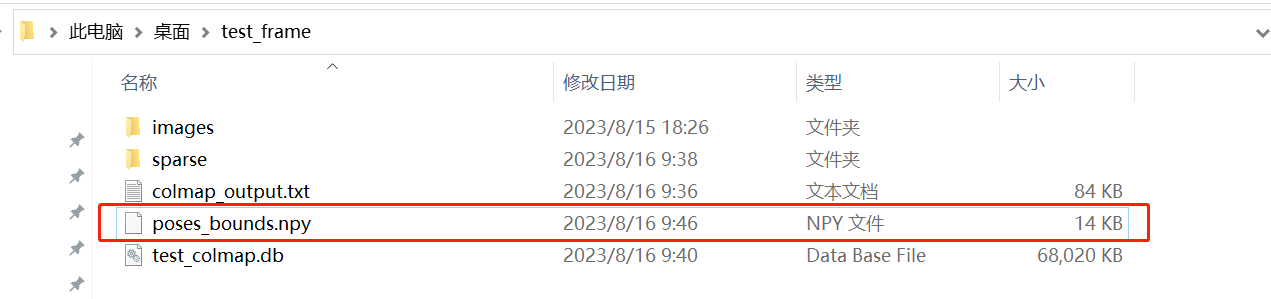
转成DTU数据的格式
博主提供了LLFF数据格式转DTU数据格式的代码。 将代码解压到合适的文件夹下,这里博主是解压到NeuS路径下。  执行指令将LLFF数据格式转DTU数据格式。
执行指令将LLFF数据格式转DTU数据格式。
# XXX表示sparse所在的路径,不包含sparse。 python tools/preprocess_llff.py XXXX #eg: python tools/preprocess_llff.py C:\Users\AYU\Desktop\test_frame
 所有准备工作都已完成。
所有准备工作都已完成。














 2118
2118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









