







零基础入门语义分割-Task1 赛题理解
赛题理解
- 赛题名称:零基础入门语义分割-地表建筑物识别
- 赛题目标:通过本次赛题可以引导大家熟练掌握语义分割任务的定义,具体的解题流程和相应的模型,并掌握语义分割任务的发展。
- 赛题任务:赛题以计算机视觉为背景,要求选手使用给定的航拍图像训练模型并完成地表建筑物识别任务。
学习目标
- 在理解背景的前提下,对cv语义分割流程有所了解
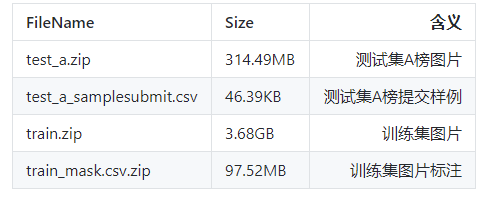
赛题数据
- 将航拍图像素划分为有建筑物和无建筑物两类
- 数据来源: Inria Aerial Image Labeling
- 数据标签:原始图片为jpg格式,标签为RLE编码的字符串
-
RLE:run-length coding 游程编码 对连续的黑白像素以不同的码字进行编码 “简单的非破坏性资料压缩法”
附上RLE与图片的转换方法
import numpy as np
import pandas as pd
import cv2
# 将图片编码为rle格式
def rle_encode(im):
'''
im: numpy array, 1 - mask, 0 - background
Returns run length as string formated
'''
pixels = im.flatten(order = 'F')
pixels = np.concatenate([[0], pixels, [0]])
runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
runs[1::2] -= runs[::2]
return ' '.join(str(x) for x in runs)
# 将rle格式进行解码为图片
def rle_decode(mask_rle, shape=(512, 512)):
'''
mask_rle: run-length as string formated (start length)
shape: (height,width) of array to return
Returns numpy array, 1 - mask, 0 - background
'''
s = mask_rle.split()
starts, lengths = [np.asarray(x, dtype=int) for x in (s[0:][::2], s[1:][::2])]
starts -= 1
ends = starts + lengths
img = np.zeros(shape[0]*shape[1], dtype=np.uint8)
for lo, hi in zip(starts, ends):
img[lo:hi] = 1
return img.reshape(shape, order='F')
评价指标
赛题使用Dice coefficient来衡量选手结果与真实标签的差异性,Dice coefficient可以按像素差异性来比较结果的差异性。Dice coefficient的具体计算方式如下:
2 ∗ ∣ X ∩ Y ∣ ∣ X ∣ + ∣ Y ∣ \frac{2 * |X \cap Y|}{|X| + |Y|} ∣X∣+∣Y∣2∗∣X∩Y∣
其中 X X X是预测结果, Y Y Y为真实标签的结果。当 X X X与 Y Y Y完全相同时Dice coefficient为1,排行榜使用所有测试集图片的平均Dice coefficient来衡量,分数值越大越好。
读取数据
代码
import pandas as pd
import cv2
train_mask = pd.read_csv('train_mask.csv', sep='\t', names=['name', 'mask'])
# 读取第一张图,并将对于的rle解码为mask矩阵
img = cv2.imread('train/'+ train_mask['name'].iloc[0])
mask = rle_decode(train_mask['mask'].iloc[0])
print(rle_encode(mask) == train_mask['mask'].iloc[0])
# 结果为True
实际遇到的一些问题
首先是对应的一些诸如torchvision版本不对应造成的问题,在群里有人提出了解决方案
还有就是一些库需要用whl安装
整体因为是第一次跑CV 电脑是XPS 8700+1070的配置 有点吃力
Baseline结果
其实截止打卡之前我的baseline也还没有跑通,还差大概1小时左右
所以后续可以补上 在本地跑的时候会有个结果

解题思路(转datawhale)
由于本次赛题是一个典型的语义分割任务,因此可以直接使用语义分割的模型来完成:
步骤1:使用FCN模型模型跑通具体模型训练过程,并对结果进行预测提交;
步骤2:在现有基础上加入数据扩增方法,并划分验证集以监督模型精度;
步骤3:使用更加强大模型结构(如Unet和PSPNet)或尺寸更大的输入完成训练;
步骤4:训练多个模型完成模型集成操作;
本章小结
本章主要对赛题背景和主要任务进行讲解,并多对赛题数据和标注读取方式进行介绍,最后列举了赛题解题思路。















 390
390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









