







目录
1. 随机梯度下降
(1)不用每输入一个样本就去变换参数,而是输入一批样本(叫做一个BATCH或MINI-BATCH),求出这些样本的梯度平均值后,根据这个平均值改变参数。
(2)在神经网络训练中,BATCH的样本数大致设置为500-2000不等。
batch_size = option.batch_size;
m = size(train_x,1);
num_batches = m / batch_size;
for k = 1 : iteration
kk = randperm(m);
for l = 1 : num_batches
batch_x = train_x(kk((l - 1) * batch_size + 1 : l * batch_size), :);
batch_y = train_y(kk((l - 1) * batch_size + 1 : l * batch_size), :);
nn = nn_forward(nn,batch_x,batch_y);
nn = nn_backpropagation(nn,batch_y);
nn = nn_applygradient(nn);
end
end
m = size(batch_x,2);
%前向计算
nn.cost(s) = 0.5 / m * sum(sum((nn.a{k} - batch_y).^2)) + 0.5 * nn.weight_decay * cost2;
%后向传播
nn.W_grad{nn.depth-1} = nn.theta{nn.depth}*nn.a{nn.depth-1}'/m + nn.weight_decay*nn.W{nn.depth-1};
nn.b_grad{nn.depth-1} = sum(nn.theta{nn.depth},2)/m;
2. 激活函数

3. 训练数据初始化
建议:做均值和方差归一化。

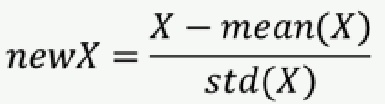
[U,V] = size(xTraining);
avgX = mean(xTraining);
sigma = std(xTraining);
xTraining = (xTraining - repmat(avgX,U,1))./repmat(sigma,U,1);
sigmoid tanh
梯度消失现象:如果![]() 一开始很大或很小,那么梯度将趋近于0,反向传播后前面与之相关的梯度也趋近于0,导致训练缓慢。 因此,我们要使
一开始很大或很小,那么梯度将趋近于0,反向传播后前面与之相关的梯度也趋近于0,导致训练缓慢。 因此,我们要使 ![]() 一开始在零附近。
一开始在零附近。
4. (W,b)的初始化
一种比较简单有效的方法是:(W,b)初始化从区间 ![]() 均匀随机取值。其中 d 为(W,b)所在层的神经元个数。
均匀随机取值。其中 d 为(W,b)所在层的神经元个数。
可以证明,如果X服从正态分布,均值0,方差1,且各个维度 无关,而(W,b)是![]() 的均匀分布,则
的均匀分布,则![]() 是均值 为0, 方差为1/3的正态分布。
是均值 为0, 方差为1/3的正态分布。
nn.W{k} = 2*rand(height, width)/sqrt(width)-1/sqrt(width);
nn.b{k} = 2*rand(height, 1)/sqrt(width)-1/sqrt(width);
5 *. Batch normalization
论文:Batch normalization accelerating deep network training by reducing internal covariate shift (2015)
基本思想:既然我们希望每一层获得的值都在0附近,从而避免梯度消失现象,那么我们为什么不直接把每一层的值做基于均值和方差的归一化呢?
每一层FC(Fully Connected Layer)接一个BN(Batch Normalization)层
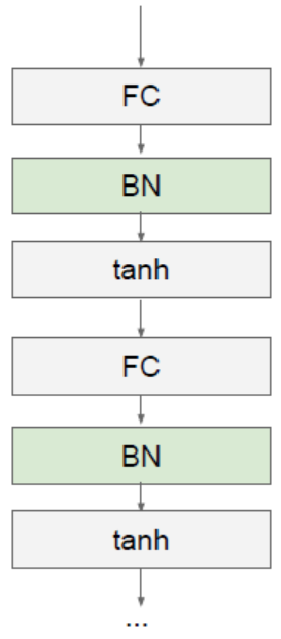
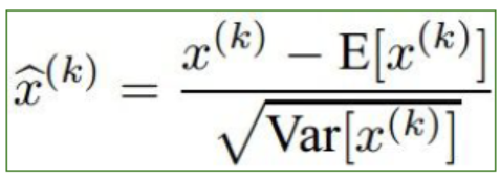

γ,β为训练参数,每次后向传播的时候将其作为参数,求偏导并更新
batch normalization的代码:仔细看不难理解
前向计算:
y = nn.W{k-1} * nn.a{k-1} + repmat(nn.b{k-1},1,m);
if nn.batch_normalization
nn.E{k-1} = nn.E{k-1}*nn.vecNum + sum(y,2);
nn.S{k-1} = nn.S{k-1}.^2*(nn.vecNum-1) + (m-1)*std(y,0,2).^2;
nn.vecNum = nn.vecNum + m;
nn.E{k-1} = nn.E{k-1}/nn.vecNum; %新的均值
nn.S{k-1} = sqrt(nn.S{k-1}/(nn.vecNum-1)); %新的方差
y = (y - repmat(nn.E{k-1},1,m))./repmat(nn.S{k-1}+0.0001*ones(size(nn.S{k-1})),1,m);
y = nn.Gamma{k-1}*y+nn.Beta{k-1};
end;
switch nn.activaton_function %激活函数层
case 'sigmoid'
nn.a{k} = sigmoid(y);
case 'tanh'
nn.a{k} = tanh(y);
后向传播
nn.theta{k} = ((nn.W{k}'*nn.theta{k+1})) .* nn.a{k} .* (1 - nn.a{k}); %显然激活函数是sigmoid
if nn.batch_normalization
x = nn.W{k-1} * nn.a{k-1} + repmat(nn.b{k-1},1,m);
x = (x - repmat(nn.E{k-1},1,m))./repmat(nn.S{k- 1}+0.0001*ones(size(nn.S{k-1})),1,m);
temp = nn.theta{k}.*x;
nn.Gamma_grad{k-1} = sum(mean(temp,2));
nn.Beta_grad{k-1} = sum(mean(nn.theta{k},2));
nn.theta{k} = nn.Gamma{k-1}*nn.theta{k}./repmat((nn.S{k-1}+0.0001),1,m);
end;
nn.W_grad{k-1} = nn.theta{k}*nn.a{k-1}'/m + nn.weight_decay*nn.W{k-1};
nn.b_grad{k-1} = sum(nn.theta{k},2)/m;
6*. 目标函数选择
1. 可加正则项 (Regulation Term)
![]()
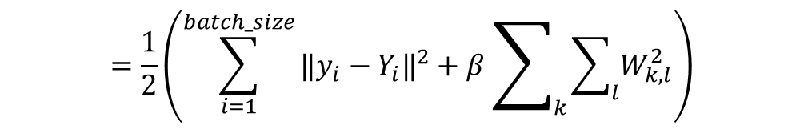
前向计算
cost2 = cost2 + sum(sum(nn.W{k-1}.^2));
nn.cost(s) = 0.5 / m * sum(sum((nn.a{k} - batch_y).^2)) + 0.5 * nn.weight_decay * cost2;
后向传播
nn.W_grad{k-1} = nn.theta{k}*nn.a{k-1}'/m + nn.weight_decay*nn.W{k-1};
2. 如果是分类问题, F(W)可以采用SOFTMAX函数和交叉熵的组合
(a)SOFTMAX函数:



(b)交叉熵(Cross Entropy):

如果F(W)是SOFTMAX函数和交叉熵的组合,那么求导将会有非常简单的形式:
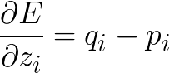
前向计算
if strcmp(nn.objective_function,'Cross Entropy')
nn.cost(s) = -0.5*sum(sum(batch_y.*log(nn.a{k})))/m + 0.5 * nn.weight_decay * cost2;
后向传播
case 'softmax'
y = nn.W{nn.depth-1} * nn.a{nn.depth-1} + repmat(nn.b{nn.depth-1},1,m);
nn.theta{nn.depth} = nn.a{nn.depth} - batch_y;
7*. 参数更新策略
(1)常规的更新 (Vanilla Stochastic Gradient Descent)
nn.W{k} = nn.W{k} - nn.learning_rate*nn.W_grad{k};
nn.b{k} = nn.b{k} - nn.learning_rate*nn.b_grad{k};
SGD的问题
(1)(W,b)的每一个分量获得的梯度绝对值有大有小,一些情况下,将会迫使优化路径变成Z字形状。

(2)SGD求梯度的策略过于随机,由于上一次和下一次用的是完全不同的BATCH数据,将会出现优化的方向随机的情况。


解决各个方向梯度不一致的方法: (1)AdaGrad

![]() :
:
if strcmp(nn.optimization_method, 'AdaGrad')
nn.rW{k} = nn.rW{k} + nn.W_grad{k}.^2;
nn.rb{k} = nn.rb{k} + nn.b_grad{k}.^2;
nn.W{k} = nn.W{k} - nn.learning_rate*nn.W_grad{k}./(sqrt(nn.rW{k})+0.001);
nn.b{k} = nn.b{k} - nn.learning_rate*nn.b_grad{k}./(sqrt(nn.rb{k})+0.001);
(2)RMSProp (AdaGrad是RMSProp 的特例 ![]() =0.5 )
=0.5 )

if strcmp(nn.optimization_method, 'RMSProp')
nn.rW{k} = 0.9*nn.rW{k} + 0.1*nn.W_grad{k}.^2;
nn.rb{k} = 0.9*nn.rb{k} + 0.1*nn.b_grad{k}.^2;
nn.W{k} = nn.W{k} - nn.learning_rate*nn.W_grad{k}./(sqrt(nn.rW{k})+0.001);
nn.b{k} = nn.b{k} - nn.learning_rate*nn.b_grad{k}./(sqrt(nn.rb{k})+0.001); %rho = 0.9
解决梯度随机性问题: (3)Momentum :让第一次得到的梯度对第二次也产生影响
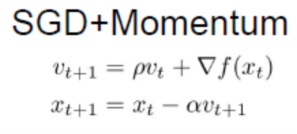

if strcmp(nn.optimization_method, 'Momentum')
nn.vW{k} = 0.5*nn.vW{k} + nn.learning_rate*nn.W_grad{k};
nn.vb{k} = 0.5*nn.vb{k} + nn.learning_rate*nn.b_grad{k};
nn.W{k} = nn.W{k} - nn.vW{k};
nn.b{k} = nn.b{k} - nn.vb{k}; %rho = 0.5;
同时解决以上两个问题: (4)Adam

if strcmp(nn.optimization_method, 'Adam')
nn.sW{k} = 0.9*nn.sW{k} + 0.1*nn.W_grad{k};
nn.sb{k} = 0.9*nn.sb{k} + 0.1*nn.b_grad{k};
nn.rW{k} = 0.999*nn.rW{k} + 0.001*nn.W_grad{k}.^2;
nn.rb{k} = 0.999*nn.rb{k} + 0.001*nn.b_grad{k}.^2;
nn.W{k} = nn.W{k} - 10*nn.learning_rate*nn.sW{k}./sqrt(1000*nn.rW{k}+0.00001);
nn.b{k} = nn.b{k} - 10*nn.learning_rate*nn.sb{k}./sqrt(1000*nn.rb{k}+0.00001); %rho1 = 0.9, rho2 = 0.999, delta = 0.00001
8*. 训练建议
(1)一般情况下,在训练集上的目标函数的平均值(cost)会随着训练的深入而不断减小,如果这个指标有增大情况,停下来。有两种情况:第一是采用的模型不够复杂,以致于不能在训练集上完全拟合;第二是已经训练很好了。
(2)分出一些验证集(Validation Set),训练的本质目标是在验证集上获取最大的识别率。因此训练一段时间后,必须在验证集上测试识别率,保存使验证集上识别率最大的模型参数,作为最后结果。
(3)注意调整学习率(Learning Rate),如果刚训练几步cost就增加,一般来说是学习率太高了;如果每次cost变化很小,说明学习率太低。
(4) Batch Normalization 比较好用,用了这个后,对学习率、参数更新策略等不敏感。建议如果用Batch Normalization, 更新策略用最简单的SGD即可,我的经验是加上其他反而不好。
(5)如果不用Batch Normalization, 我的经验是,合理变换其他参数组合,也可以达到目的。
(6)由于梯度累积效应,AdaGrad, RMSProp, Adam三种更新策略到了训练的后期会很慢,可以采用提高学习率的策略来补偿这一效应。















 3493
3493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









