







本篇文章对应的是自注意力机制(上和下)和transformer(上和下)
文章目录
self-attention

Vector Set as Input.
声音讯号、Graph等都可以看作是一组向量。
output

上面的输出与输入是一样的:词性标注POS tagging、HW2(音标)、social graph中每个人的分类结果

上面的输出是只有一个标签:情感分析(sentiment analysis)、HW4(speaker辨识)、hydrophilicity

第三种情况是模型自己决定标签的个数。
真正的语音辨识是seq2seq
sequence labeling
细讲第一种情况Each vector has a label.

带有黑色边框的vector是考虑了整个sequence的信息

process in detail
a
1
a^1
a1和
a
2
a^2
a2两个向量的关联度:
α
\alpha
α有多种计算方式,下面这种是比较常见的,也是transformer中使用的方式。
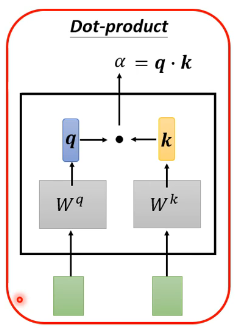
关联性计算过程如下:


从
α
\alpha
α到
α
′
\alpha'
α′也不是非一定要用soft-max,relu函数也是可以的。
接下来从
α
′
\alpha'
α′到
b
1
b^1
b1,计算公式为:
b
1
=
∑
i
α
1
,
i
′
v
i
b^1=\sum_i\alpha'_{1,i}v^i
b1=∑iα1,i′vi


self-attention其实就是在讲如何从a到b,接下来从矩阵的角度讲解:




O
O
O就是输出

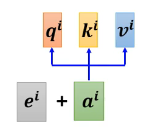
需要学习的参数为:
W
q
W^q
Wq、
W
k
W^k
Wk、
W
v
W^v
Wv
multi-head self-attention
Different types of relevance
翻译或者语音辨识等问题多个head效果要好一些。

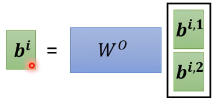
positional encoding
No position information in self-attention.
Each position has a unique positional vector
e
i
e^i
ei
添加了位置信息。

目前提出的positional encoding方法有上面几种。
Self-attention v.s. CNN
CNN可以看做简化版的self-attention


Self-attention v.s. RNN

Self-attention for Graph

transformer
transformer就是seq2seq的model
这就是前面介绍的第三种情况
The output is determined by model.

世界上有很多语言是没有文字的!!所以语音辨识有些是做不了的,直接speech translation即可。
接下来的部分,就是在介绍seq2seq的应用。


Encoder
encoder中一个block如下:


Decoder
AT(Autoregressive)
接下来把语音辨识作为例子
1.

2.“机”这个字作为输入


Encoder与Decoder的比较:

Masked Self-attention

Decoder -Non-autogressive(NAT)
NAT速度要更快一些,一步产生所有的output

Transformer


training
其实就是很多个分类问题


Teacher Forcing: using the ground truth as input.
把正确的答案当作decoder的输入。
Beam Search

有时候encoder加入随机性之后结果反而会更好。
Accept that nothing is perfect. True beauty lies in the cracks of imperfection.

















 306
306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









