







理论:
激活函数:
为什么要用激活函数:线性转为非线性,
如果不运用激活函数,输出信号仅仅是一个简单的线性函数,此时神经网络就是一个线性回归模型,无法学习和模拟如图像、语言等复杂数据。
深度学习前期用到的激活函数有Sigmoid和Tanh,后期有Relu、LeakyRelu、pRelu、Elu、softplus
https://blog.csdn.net/u013289254/article/details/98472343
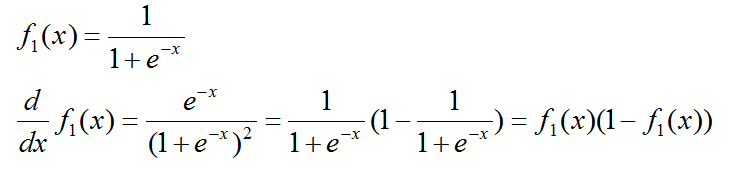
特点:
Sigmoid 函数可以把输入的值映射到0到1之间,类似一种归一化操作
缺点:
对梯度的影响
易出现梯度消失,较少出现梯度爆炸。
sigmoid的导数都是小于0.25的,那么在进行反向传播的时候,梯度相乘结果会慢慢的趋近于0。这样,几乎就没有梯度信号通过神经元传递到前面层的梯度更新中,因此这时前面层的权值几乎没有更新
应用场所:
将神经网络的输出值映射到0到1之间(乘以255就变换成了图片RGB原始像素值范围),作为二分类网络的输出激活函数,激活函数(很少用它了)
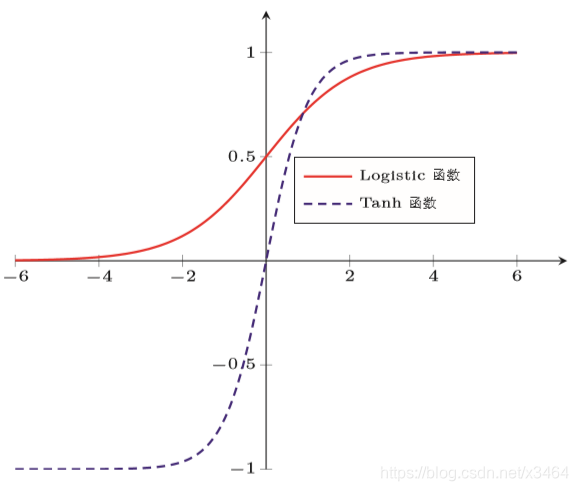
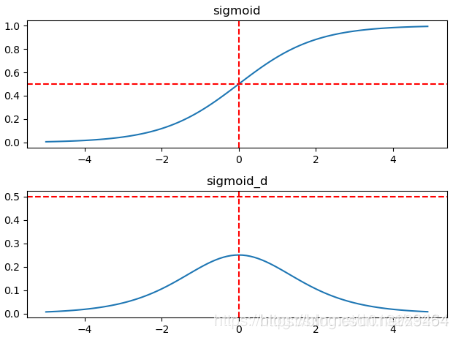
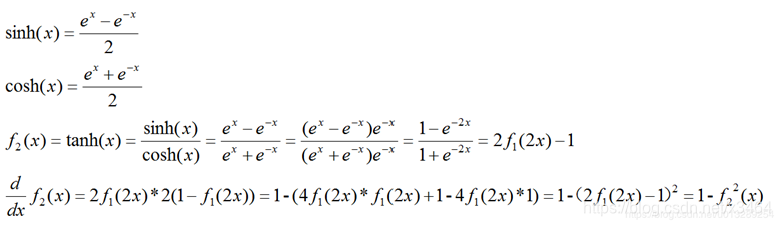
特点:
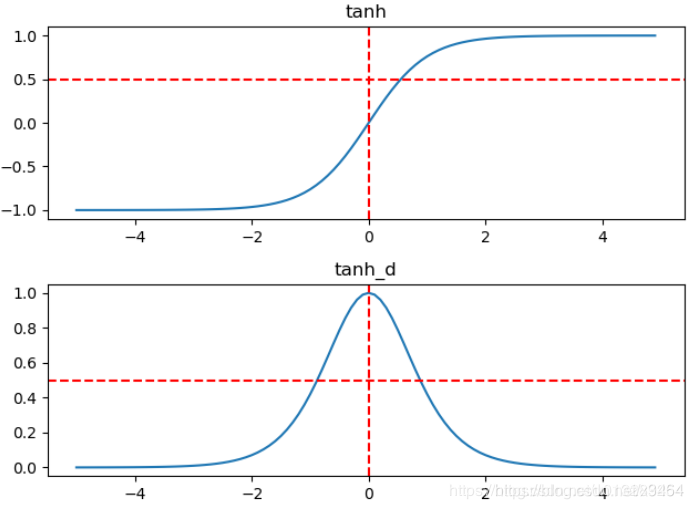
Tanh 函数可以把输入的值映射到-1到1之间,解决掉了Sigmoid 输出不是0均值的问题
缺点:
对梯度的影响
tanh与sigmoid不同的是,tanh是“零为中心”的。因此,实际应用中,tanh会比sigmoid更好一些。但是在饱和神经元的情况下,还是没有解决梯度消失问题。
应用场所:
GAN中最后一层使用tanh(使得训练更稳定),激活函数(很少用它了)
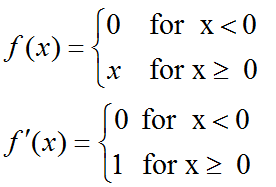
特点:
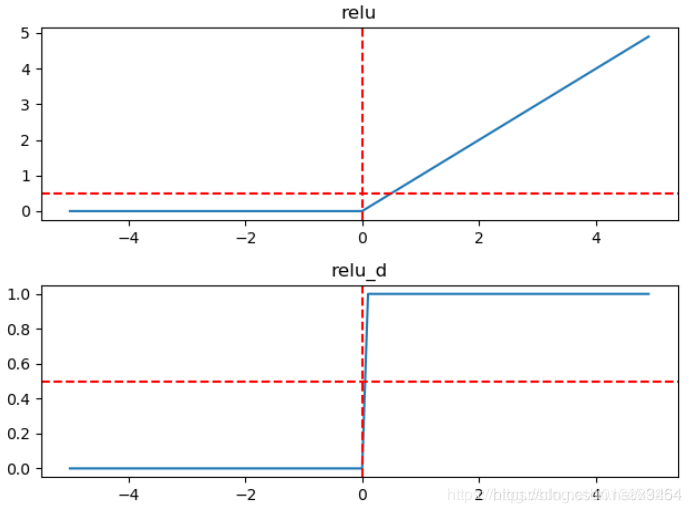
解决掉了梯度消失问题(当x>0的时候,梯度始终为1),计算速度快(判断是否大于0就行)
ReLU函数只有线性关系,不需要指数计算,不管在前向传播还是反向传播,计算速度都比sigmoid和tanh快。
缺点
对梯度的影响
ReLU解决了梯度消失的问题,至少x在正区间内,神经元不会饱和。
应用场所:
常见的激活函数,默认就选择它吧
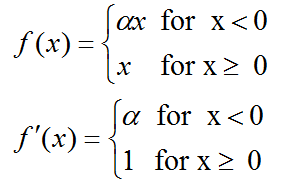
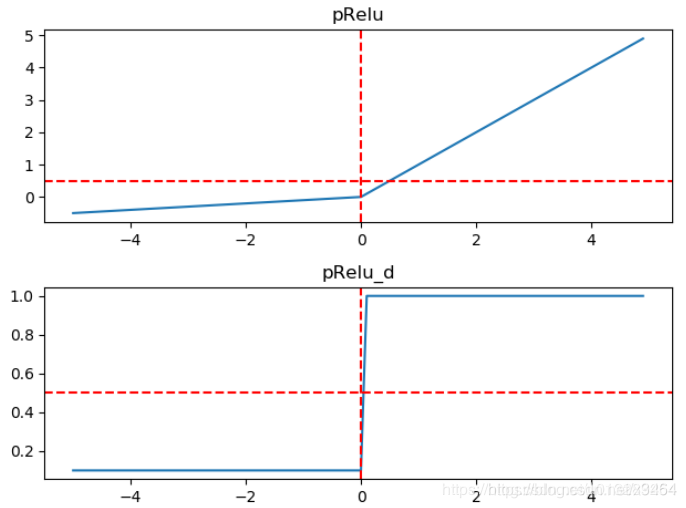
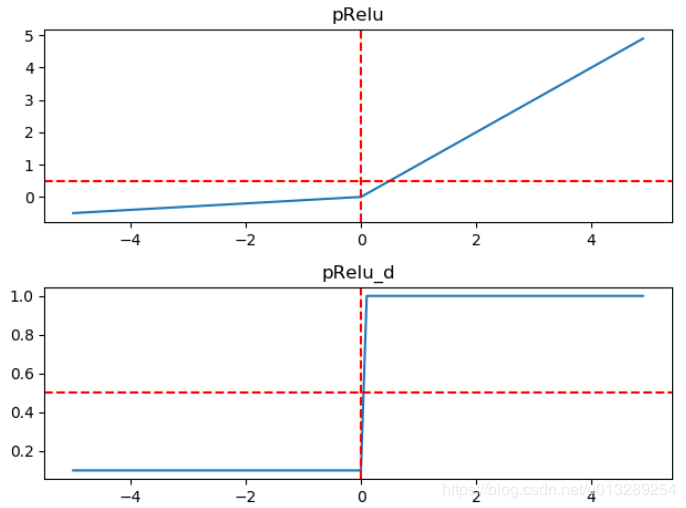
特点:
LeakyRelu(pRelu)继承了Relu所有的优点,同时也解决了'Dead ReLU Problem'问题,但实际应用中,Relu的效果没有比它差
带泄露修正线性单元(Leaky ReLU)函数是经典(以及广泛使用的)的ReLu激活函数的变体,该函数输出对负值输入有很小的坡度。由于导数总是不为零,这能减少静默神经元的出现,允许基于梯度的学习(虽然会很慢),解决了Relu函数进入负区间后,导致神经元不学习的问题。
应用场所
常见的激活函数,有些时候用它,会取得不错的效果,建议还是试一下为好
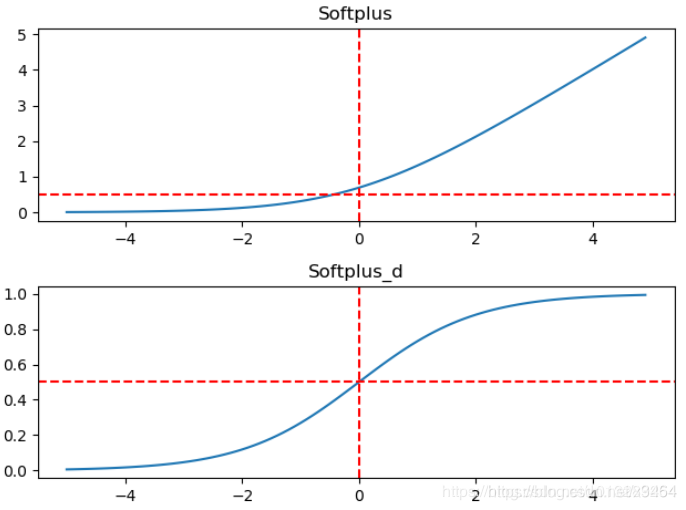
特点:
Softplus相对于Relu,是一种更加平滑的激活函数

缺点:
计算复杂,涉及到e的指数计算,而且这个函数对于硬件化也不友好
应用场所:
激活函数(对于有些输出,需要更加平滑和连续性,会取到意想不到的结果),我建议有时收敛不了,可以试一下它
前馈神经网络:
在前馈神经网络(Feedforward Neural Network, FNN )中,每一层的神经元可以接收前一层神经元的信号,并产生信号输出到下一层。第0层叫做输入层,最后一层叫做输出层,其他中间层叫做隐藏层。整个网络中无反馈,信号从输入层向输出层单向传播,可用一个有向无环图表示。
https://www.cnblogs.com/Luv-GEM/p/10694471.html
多层前馈神经网络的图示如下:

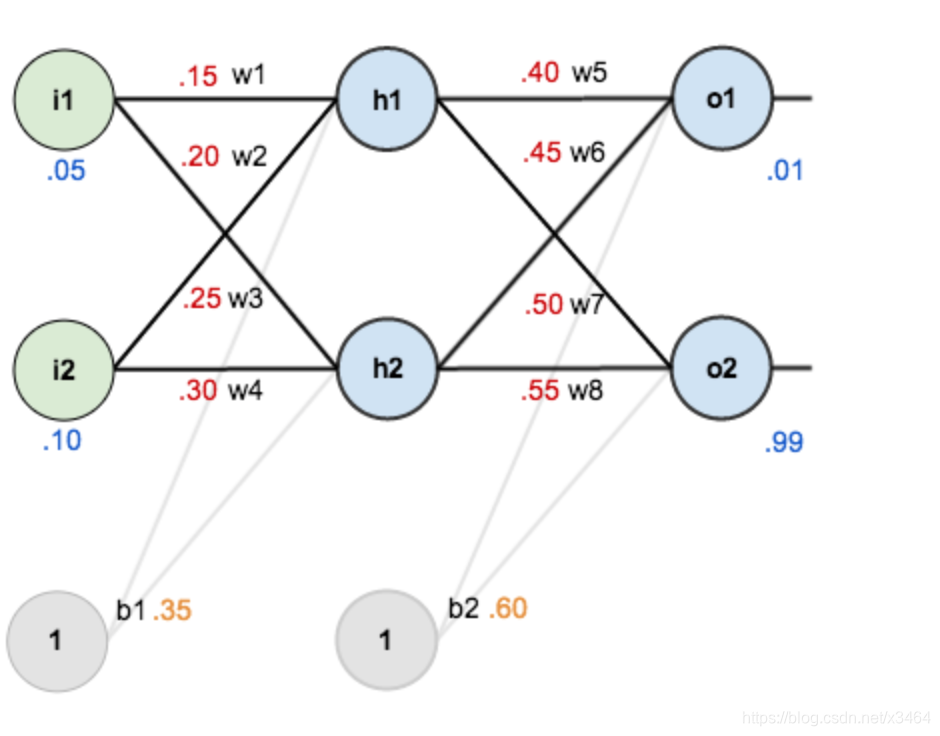
反向传播算法
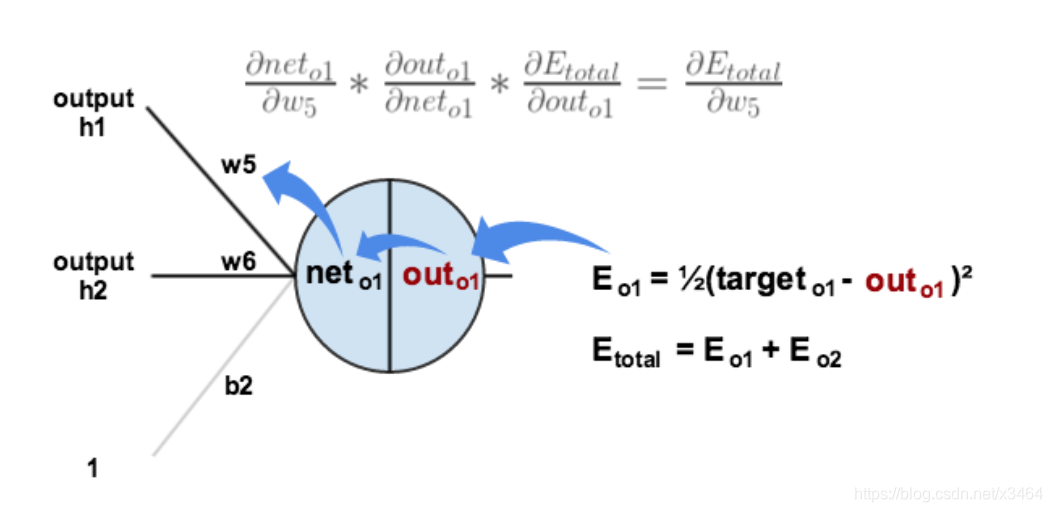

梯度计算
https://www.cnblogs.com/softlin/p/9048485.html
自动微分是梯度下降法的核心
手动微分法需要我们手动编写出代价函数、 激活函数的求导代码,硬编码这些函数的求导方法,如果这些函数后面有调整该函数的求导方法又要重新实现,可以说是又麻烦又容易出错;
数值微分是用数值方法来计算函数的导数,该方法主要是计算速度慢,精度差等问题;
符号微分是一种基于符号计算的自动求导方式,符号微分有个缺陷就是得到的导数不一定是最简的,函数较为复杂时表达式树会很复杂,可能会出现表达式爆炸的情况出现;
自动微分法介于数值微分与 符号微分 之间,
数值微分是直接代入数值近似求解而符号微分为直接通过表达式树对表达式进行求解;自动微分先将符号微分用于基本的算子,带入数值并保存中间结果,后应用于整个函数;
自动微分本质上就是图计算,容易做很多优化所以广泛应用于各种机器学习深度学习框架中;
自动微分又分为前向模式(Forward mode Autodiff)与 反向模式(Reverse-Mode Atuodiff)求导;
前向模式
引入二元数,但由于深度学习的参数比较多所以前向模式的效率还是有些差;一个前向过程就可以求出其函数值与导数
反向模式
反向模式为先通过正向遍历计算图求出每个节点的值,然后通过反向遍历整个图,计算出每个节点的偏导,其原理为微积分链式法则,这里所说的反向模式其实也就是我们在深度学习中所说的BP算法(反向传播算法),只需要一个前向传播、一个反向传播就可以求得所有参数的导数,所以性能很高,非常适用于深度学习中的自动求导;
优化问题
https://blog.csdn.net/mzpmzk/article/details/80100864
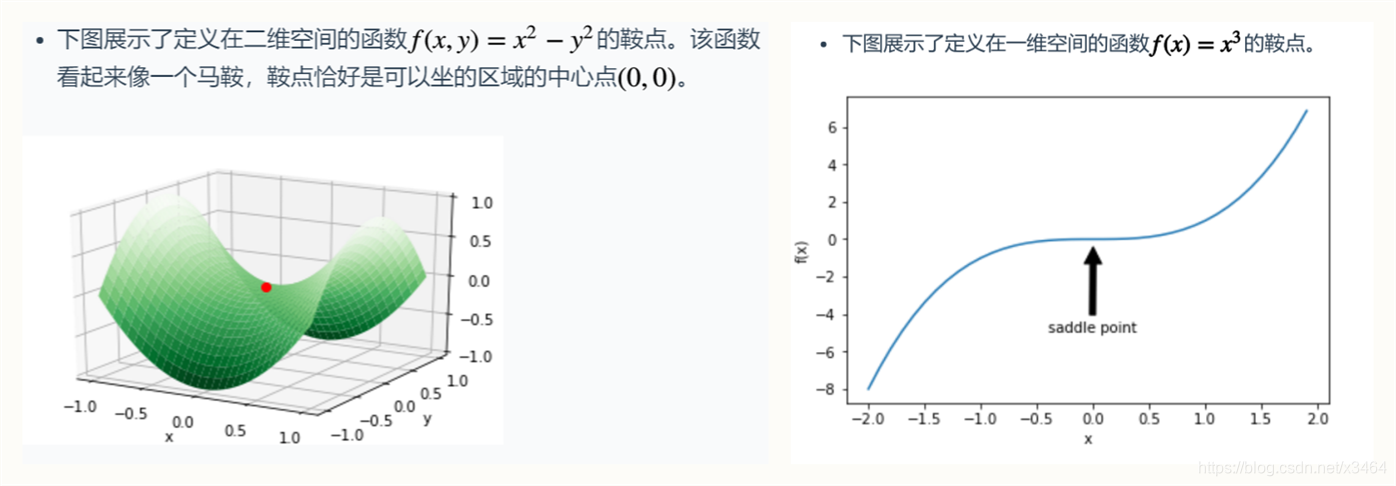
优化问题中的两个挑战:局部最小值和鞍点。这两种情况都会造成梯度接近或变成零,从而使得网络很难继续优化。
低维空间的非凸优化问题:主要是存在一些局部最优点。采用梯度下降方法时,不合适的参数初始化会导致陷入局部最优点,因此主要的难点是如何选择初始化参数和逃离局部最优点。
高维空间中非凸优化的难点:并不在于如何逃离局部最优点,而是如何逃离鞍点。鞍点(saddle point)是梯度为0,但是在一些维度上是最高点,在另一些维度上是最低点。
优化算法
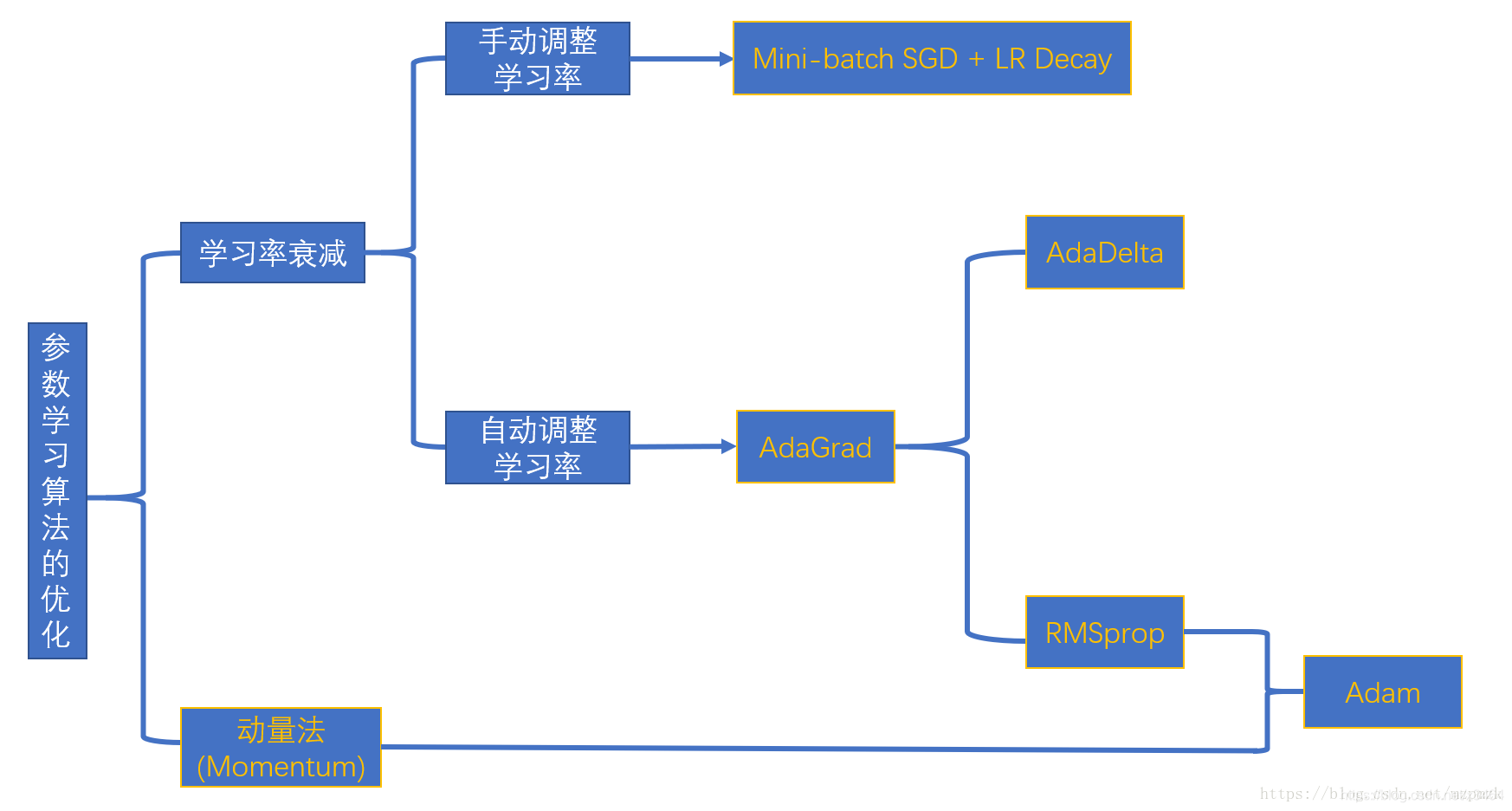
学习率衰减:
实践中我们经常随着训练的不断进行而逐渐减小学习率。
原因:我们是对整个训练集进行随机采样 mini-batch,这会在优化时引入一些噪声,而这些噪声并不会在极小值点消失,可能会造成来回震荡。
解决办法: 手动调整学习率(Mini-batch SGD + LR Decay)或者自动调整学习率(AdaGrad, AdaDelta, RMSprop, Adam)
动量:
通常我们会使用小批量随机梯度下降(Mini-Batch SGD)优化算法,但它每次迭代时使用的训练数据都是随机选取的,这样会引入一些噪声,而且其每次参数更新都是沿着梯度下降最快的方向,此方向仅仅取决于当前的位置,这可能会带来一些问题,比如陷入局部极小值附近,开始来回震荡不能达到最小值。
pytorch 实现前馈神经网络。
- 解决办法: Momentum 优化算法(可以配合手动调整 LR Decay 使用) 或者 Adam 优化算法
- 自动微分
- 符号微分
- 数值微分
- 手动微分
- 将训练集数据输入到神经网络的输入层,经过隐藏层,最后达到输出层并输出结果,这就是前向传播过程。
- 由于神经网络的输出结果与实际结果有误差,则计算估计值与实际值之间的误差,并将该误差从输出层向隐藏层反向传播,直至传播到输入层;
- 在反向传播的过程中,根据误差调整各种参数的值(相连神经元的权重),使得总损失函数减小。
- 迭代上述三个步骤(即对数据进行反复训练),直到满足停止准则。
- 输出层
- 隐藏层
- 输入层
- Softplus
- Leaky ReLU
- Relu函数的输出不是0均值
- 会产生'Dead ReLU Problem(神经元死亡/权值无法更新,比如第一次更新权重输入的是负值)'问题,其实,在我们训练网络的时候,很少出现这种问题,所以大胆的用吧
- ReLU
- 梯度消失(爆炸)问题
- 计算复杂,涉及到e的指数计算,而且这个函数对于硬件化也不友好
- Tanh
- 容易引起梯度消失(当权重初始化为0到1之间的时候,Sigmoid 函数梯度的最大值也就为0.25,会导致反向传播的时候,距离输入层的梯度值越来越小),当然也可能发生梯度爆炸(当权重比较大的时候)
- Sigmoid 函数的输出不是0均值,会导致梯度更新要不为正,要不为负,使得网络很难收敛
- 计算复杂,涉及到e的指数计算,而且这个函数对于硬件化也不友好
- logistic

















 32万+
32万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









