







【论文阅读笔记】A Generalization of Transformer Networks to Graphs
1. 论文地址
论文:https://arxiv.org/pdf/2012.09699.pdf
代码:https://github.com/graphdeeplearning/graphtransformer
2. Abstract
作者提出了一种适用于任意图的transformer神经网络结构的推广方法。原始的transformer是建立在全连接的图上,这种结构不能很好地利用图的连通归纳偏置——arbitrary and sparsity,即把transformer推广到任意图结构,且表现较弱,因为图的拓扑结构也很重要,但是没有融合到节点特征中。
作者提出新的graph transformer,带有以下四个新特征:
- 在每个node的可连通临域做attention.
- positional encoding用拉普拉斯特征向量表示.
- 用BN(batch normalization)代替LN(layer normalization),优点:训练更快,泛化性能更好.
- 将结构扩展到边特征表示.
此架构简单而通用,作者相信它可以作为黑盒,应用在transformer和graph的application中。
3. Introduction
- 在NLP中,transformer利用注意力机制处理长距离的序列信息,即句子中的一个单词与其它单词关联,然后结合获得的权重信息得到抽象的特征表示。
- 基于图结构数据的GNNs挖掘给定任意图的结构信息,并学习nodes和edges的特征表示。
3.1 Related Work
- 在Graph Transformer中,attention用在了某个node对所有nodes,而不是此node的邻域。这限制了稀疏性的有效利用,稀疏性是图数据集学习的一个很好的归纳偏差。对于全局信息,作者提出其它方法(graph-specific positional features,node Laplacian position eigenvectors,relative learnable positional information,virtual nodes)去获取而不是放弃稀疏性和局部的信息。
- Graph-BERT采用多个位置编码方案的组合来捕获绝对节点结构和相对节点位置信息。由于原始图不直接用于graph-BERT和子图之间没有edge(即无链接),提出的positional encodings的组合试图在node中保留原始图结构信息。
- Graph Transformer Networks (GTN)学习异构图,目标是将给定的异构图转换为基于元路径的图,然后执行卷积。
- Heterogeneous Graph Transformer (HGT),它可以处理任意数量的nodes和edges类型,HGT还基于中心node和消息传递node的时间戳差异,以相对时间的positional encoding的形式捕捉异构图中的动态信息。
- Zhou et al.(2020)提出了一种基于transformer的生成模型,通过直接学习网络中的动态信息来生成时间图。
- 作者目的:开发基于坐标嵌入的positional encoding方案的任意同构图的graph transformer。
3.2 Contributions
- 把transformer网络推广到任意结构的同构图,即Graph Transformer,它的带有edge特征的扩展版本允许使用显示域信息作为edge特征。
- method包括用拉普拉斯特征向量融合node的positional features。
- 实验证明,作者提出的model优于baseline的各向同性和异性的GNNs。
4. Proposed Architecture
作者开发Graph Transformers考虑到2个关键因素—— sparsity and positional encodings。
4.1 On Graph Sparsity
为什么在NLP的transformer中,用全连接图去处理一个句?
- 很难去找到单词与单词之间的稀疏联系,因为单词的含义是依据上下文和不同角度。
- 在NLP的transformer的nodes数量是比较少(几十个,几百个),便于计算。
在实际的图结构数据集中,图有任意的连通结构,nodes的数量达到百万,数亿级别,使得不可能获取一个完整的连接的图,所有实际的做法是用Graph Transformer来使node处理邻接nodes。
4.2 On Positional Encodings
- 在NLP里,为每个单词提供一个positional encoding,保证了每个单词的唯一性和保存位置信息。
- 大多数在图数据集上训练的GNNs学习的是不随node位置变化的结构化的node信息,这就是为什么GAT是局部attention,而不是全局。我们要学习结构和位置的特征,Dwivedi et al. (2020)利用图结构信息去预先计算拉普拉斯特征向量并作为node的位置信息,并把它作为PE用在Graph Transformer中,图的拉普拉斯矩阵:
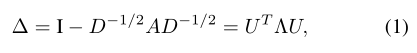
用node的最小的k个非平凡特征向量作为PE。
4.3 Graph Transformer Architecture
 1. 第一个模型是为没有明显edge属性的图而设计的,第二个模型保留一个指定的edge特征的pipeline,以整合可用的edge信息,并在每一层保留它们的抽象表示。输入是node和edge的embeddings,有node和edge的特征信息,然后线性映射嵌入:
1. 第一个模型是为没有明显edge属性的图而设计的,第二个模型保留一个指定的edge特征的pipeline,以整合可用的edge信息,并在每一层保留它们的抽象表示。输入是node和edge的embeddings,有node和edge的特征信息,然后线性映射嵌入:
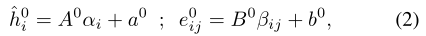
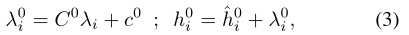
接下来是Graph Transformer Layer,先是一个self-attention,再进行多头拼接:
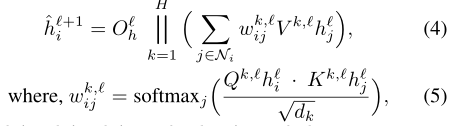
此层输出的结果传到FFN,再进行残差连接和LN:
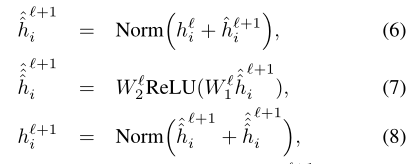
2.第二个模型是把edge特征加入进来,如上的右图。它把两个node的之间的edge信息也加入到attention的计算中,当然是node的可连通的邻域node,edge的分数也高说明关联程度就越高:



5. Numerical Experiments
为了评估提出的模型的性能,在ZINC,PATTERN,CLUSTER这三个数据集实验。
ZINC, Graph Regression:分子数据集,node代表分子,edge代表分子之间的键。键之间有丰富的特征信息,所以用第二个模型。
PATTERN, Node Classification:任务是把nodes分成两个communities,没有明确的edge信息,所以用第一个模型。
CLUSTER, Node Classification:任务是为每个node分配cluster,一共有6个cluster,用第一个模型。
Model Configurations:PyTorch,DGL,一共有10层Graph Transformer layers,每层有8个attention head和随机的隐藏单元,学习率递减策略,当达到10-6就停止训练。

6. Analysis and Discussion
实验结论如下:
- 由Table1可知,带有LapPE和BN的模型实验数据更好。
- 由Table2可知,提出的模型明显比GCN和GTN要好,但没有GatedGCN好。
- 稀疏图连通性对于具有任意图结构的数据集来说是一个关键的归纳偏差,通过比较稀疏图与全图实验可以证明这一点。
- 提出的第二个模型的性能在ZINC上近似于GatedGCN。
6.1 Comparison to PEs used in Graph-BERT
作者说明为什么用拉普拉斯特征向量作为PE在本模型中,它与Graph-BERT做对比。Graph-BERT是在固定大小的抽样子图上进行的操作,它把原始图以node的数量分成v个子图,每个子图有k+1个nodes,其中是中心node与k个最相似的node的组合,这种相似性是根据node之间的edge计算得来的。虽然这种sampling对于并行计算和提高计算效率很好,但是原始图没有直接用在这个层中。Graph-BERT用一种node的PE组合的方式去融合node的结构,位置,和距离信息:
- 基于亲密度的相对PE。
- 基于Hop的相对距离编码。
- 基于Weisfeiler Lehman的绝对PE (WL-PE)。
前两个PE依赖于node的sampling策略不具有一般性,所以用第三种PE与拉普拉斯的PE做比较,实验结果如Table3所示,用拉普拉斯的PE要比WL-PE效果好。
7. Conclusion
本文主要展示了一种把transformer推广到任意的图的简单且有效的方法,并展示了两种模型的结构。用拉普拉斯特征向量作为PE和把LN用BN代替,使模型学习能力得到增强。考虑到这种结构的简单和通用的性质和有竞争力的性能表现,作者相信提出的模型会在以后得到更好的提升。未来方向:有效地在大型单一的图上进行训练,对异构图上的适用性研究等。















 3092
3092











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









