







Self-Supervised Learning 超详细解读 (目录) - 知乎本系列已授权极市平台,未经允许不得二次转载,如有需要请私信作者,文章持续更新。0 Motivation Self-Supervised Learning,又称为自监督学习,我们知道一般机器学习分为有监督学习,无监督学习和强化学习。 而 S… https://zhuanlan.zhihu.com/p/381354026
https://zhuanlan.zhihu.com/p/381354026
0 Motivation
Self-Supervised Learning,又称为自监督学习,我们知道一般机器学习分为有监督学习,无监督学习和强化学习。 而 Self-Supervised Learning 是无监督学习里面的一种,主要是希望能够学习到一种通用的特征表达用于下游任务 (Downstream Tasks)。 其主要的方式就是通过自己监督自己。作为代表作的 kaiming 的 MoCo 引发一波热议, Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。所以在这个系列中,我会系统地解读 Self-Supervised Learning 的经典工作。
Yann Lecun 曾在一个关于 Self-supervised learning 的演讲中讲到:Self-supervised learning 是 The dark matter of intelligence,意为 智能的暗物质。他说:
Self-supervised learning enables AI systems to learn from orders of magnitude more data, which is important to recognize and understand patterns of more subtle, less common representations of the world.
(自监督学习使 人工智能系统能够从更大数量级的数据中学习,这对于识别和理解更微妙、更不常见的世界表示模式很重要。)
这句话是什么意思呢?
在预训练阶段我们使用无标签的数据集 (unlabeled data),因为有标签的数据集很贵,打标签得要多少人工劳力去标注,那成本是相当高的,所以这玩意太贵。相反,无标签的数据集网上随便到处爬,它便宜。在训练模型参数的时候,我们不追求把这个参数用带标签数据从初始化的一张白纸给一步训练到位,原因就是数据集太贵。
于是Self-Supervised Learning就想先把参数从一张白纸训练到初步成型,再从初步成型训练到完全成型。注意这是2个阶段。
这个训练到初步成型的东西,我们把它叫做Visual Representation。预训练模型的时候,就是模型参数从一张白纸到初步成型的这个过程,还是用无标签数据集。
等我把模型参数训练个八九不离十,这时候再根据你下游任务 (Downstream Tasks)的不同去用带标签的数据集把参数训练到完全成型,那这时用的数据集量就不用太多了,因为参数经过了第1阶段就已经训练得差不多了。
第一个阶段不涉及任何下游任务,就是拿着一堆无标签的数据去预训练,没有特定的任务,这个话用官方语言表达叫做:in a task-agnostic way。第二个阶段涉及下游任务,就是拿着一堆带标签的数据去在下游任务上 Fine-tune,这个话用官方语言表达叫做:in a task-specific way。
以上这些话就是 Self-Supervised Learning 的核心思想,如下图1所示,后面还会再次提到它。
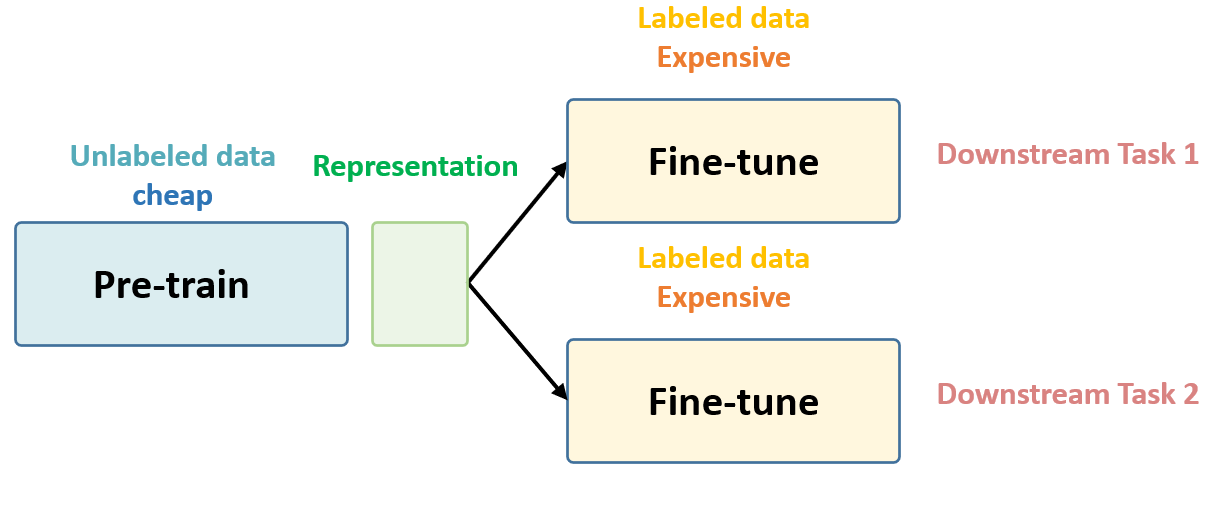
图1:Self-Supervised Learning 的核心思想
Self-Supervised Learning 不仅是在NLP领域,在CV, 语音领域也有很多经典的工作,如下图2所示。它可以分成3类:Data Centric【以数据为中心】, Prediction【预测】 (也叫 Generative【生成】) 和 Constractive【重建】。
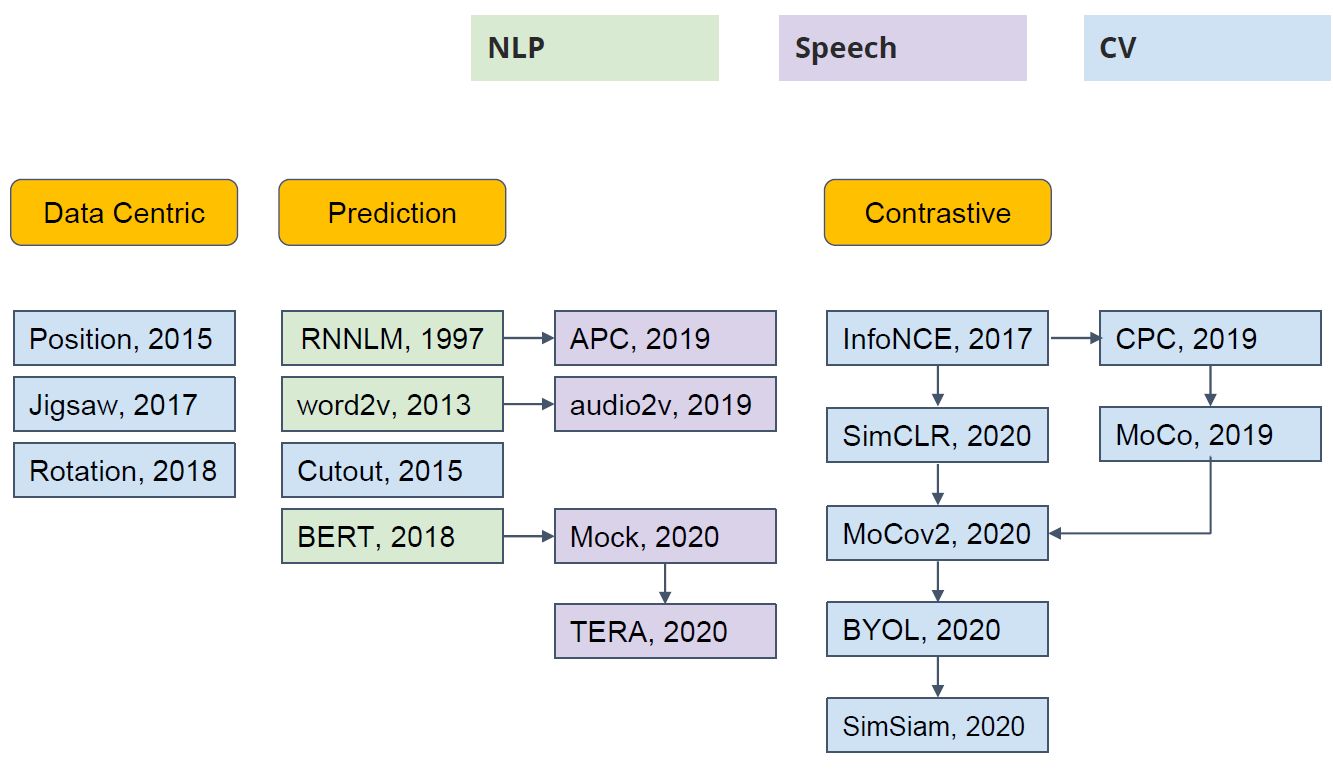
图2:各个领域的 Self-Supervised Learning
其中的主流就是基于 Generative 的方法和基于 Contrative 的方法。如下图 3 所示这里简单介绍下。
基于 Generative 的方法主要关注的重建误差,比如对于 NLP 任务而言,一个句子中间盖住一个 token,让模型去预测,令得到的预测结果与真实的 token 之间的误差作为损失。
基于 Contrastive 的方法不要求模型能够重建原始输入,而是希望模型能够在特征空间上对不同的输入进行分辨。
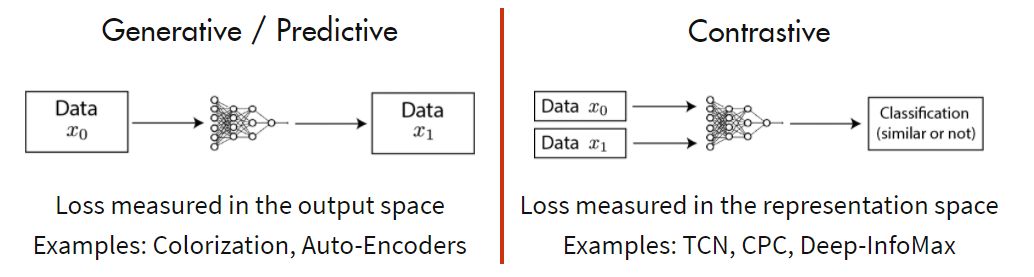
图3:基于 generative 的方法和基于 contrastive 的方法的总结图片
这个系列力求做全网最详细的解读 Self-Supervised Learning 的资料,它有着自己的理念,那就是全面,通俗和及时。它不仅会逐步包含经典的 Self-Supervised Learning 技术 (如BERT,SimCLR,MoCo 等等的介绍),还会涵盖一些最新的 Self-Supervised Learning 方案 (如BERT的方法用在视觉领域的 BEiT,自监督学习训练 Vision Transformer 等等)。它免费在网上开放,实时地更新,因此可以及时传递模型压缩技术的动态。
我的另一个关于Vision Transformer 和 Vision MLP 解读的系列可以参考:
另一个关于模型压缩系列工作解读的系列可以参考:
科技猛兽:解读模型压缩系列 (目录)68 赞同 · 15 评论文章正在上传…重新上传取消 https://zhuanlan.zhihu.com/p/370540483
https://zhuanlan.zhihu.com/p/370540483
1 Self-Supervised Learning系列解读
目录
(每篇文章对应一个Section,目录持续更新。)
- Section 1:Self-Supervised Learning 超详细解读 (一):大规模预训练模型BERT
1 芝麻街
2 BERT 与 Self-Supervised Learning
3 BART, MASS 和 ELECTRA 模型
4 为什么 BERT 有用呢?
5 GPT系列模型
6 其他领域的 Self-Supervised Learning
7 总结
link:
- Section 2:Self-Supervised Learning 超详细解读 (二):SimCLR系列
1 SimCLR 原理分析 (ICML 2020)
1.1 数据增强
1.2 通过Encoder获取图片表征
1.3 预测头
1.4 相似图片输出更接近
1.5 对下游任务Fine-tune
2 SimCLR v2原理分析 (NIPS 2020)
2.1 SimCLR v2 10分钟简介:SimCLR v2 和 SimCLR 相比做了哪些改进?
2.2 SimCLR v2 实验设置
link:
- Section 3:Self-Supervised Learning 超详细解读 (三):BEiT:视觉BERT预训练模型
1 BERT 方法回顾
2 BERT 可以直接用在视觉任务上吗?
3 BEiT 原理分析
3.1 将图片表示为 image patches
3.2 将图片表示为 visual tokens
3.2.1 变分自编码器 VAE
3.2.2 BEIT 里的 VAE:tokenizer 和 decoder
3.2.3 BEIT 的 Backbone:Image Transformer
3.2.4 类似 BERT 的自监督训练方式:Masked Image Modeling
3.2.5 BEIT 的目标函数:VAE 视角
3.2.6 BEIT 的架构细节和训练细节超参数
3.2.7 BEIT 在下游任务 Fine-tuning
3.2.8 实验
link:
- Section 4:Self-Supervised Learning 超详细解读 (四):MoCo系列解读(1)
1 MoCo v1
1.1 自监督学习的 Pretext Task
1.2 自监督学习的 Contrastive loss
1.3 MoCo v1 之前的做法
1.4 MoCo v1 的做法
1.5 MoCo v1 FAQ
1.6 MoCo v1 实验
1.7 MoCo v1 完整代码解读
link:
- Section 5:Self-Supervised Learning 超详细解读 (五):MoCo系列解读(2)
1 MoCo v2
1.1 MoCo v2 的 Motivation
1.2 MoCo 相对于 End-to-end 方法的改进
1.3 MoCo v2实验
2 MoCo v3
2.1 MoCo v3 原理分析
2.2 MoCo v3 自监督训练 ViT 的不稳定性
2.3 提升训练稳定性的方法:冻结第1层 (patch embedding层) 参数
2.4 MoCo v3 实验
link:
- Section 6:Self-Supervised Learning 超详细解读 (六):MAE:通向CV大模型
1 MAE
1.1 Self-supervised Learning
1.2 Masked AutoEncoder (MAE) 方法概述
1.3 MAE Encoder
1.4 MAE Decoder
1.5 自监督学习目标函数 Reconstruction Target
1.6 具体实现方法
1.7 ImageNet 实验结果
1.8 masking ratio 对性能的影响
1.9 观察到的一些实验现象
1.10 训练策略
1.11 结果对比
1.12 Partial Fine-tuning
link:
- Section 7:Self-Supervised Learning 超详细解读 (七):大规模预训练 Image BERT 模型:iBOT
1 iBOT
1.1 Self-supervised Learning
1.2 iBOT 方法概述
1.3 MIM 任务
1.4 Self-distillation
1.5 iBOT 的具体方法
1.6 模型结构
1.7 ImageNet-1k 实验结果
1.8 MIM 想要学习的 模式可视化
link:
- Section 8:Self-Supervised Learning 超详细解读 (八):SimMIM:掩码图像建模的简单框架
1 SimMIM
1.1 SimMIM 方法概述
1.2 Masking Strategy
1.3 Encoder 结构
1.4 Prediction head
1.5 Prediction target
1.6 Evaluation protocols
1.7 Masking strategy 对 表征学习的影响
1.8 Projection head 对表征学习的影响
1.9 Projection resolution 对表征学习的影响
1.10 Projection target 对表征学习的影响
1.11 ImageNet-1k 实验结果
1.12 可视化结果
link:
科技猛兽:Self-Supervised Learning 超详细解读 (八):SimMIM:掩码图像建模的简单框架26 赞同 · 5 评论文章正在上传…重新上传取消
并未作为商用,只是自己记录学习使用....



















 844
844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











