









 文章介绍了RNN中将文本数据转化为可处理序列的过程,包括tokenizing(将文本拆分成单词等单元)和vocabulary(建立单词到索引的映射),这两个概念在自然语言处理中的重要性以及它们如何影响模型的输入和性能。
文章介绍了RNN中将文本数据转化为可处理序列的过程,包括tokenizing(将文本拆分成单词等单元)和vocabulary(建立单词到索引的映射),这两个概念在自然语言处理中的重要性以及它们如何影响模型的输入和性能。
看图中“青色”的地方
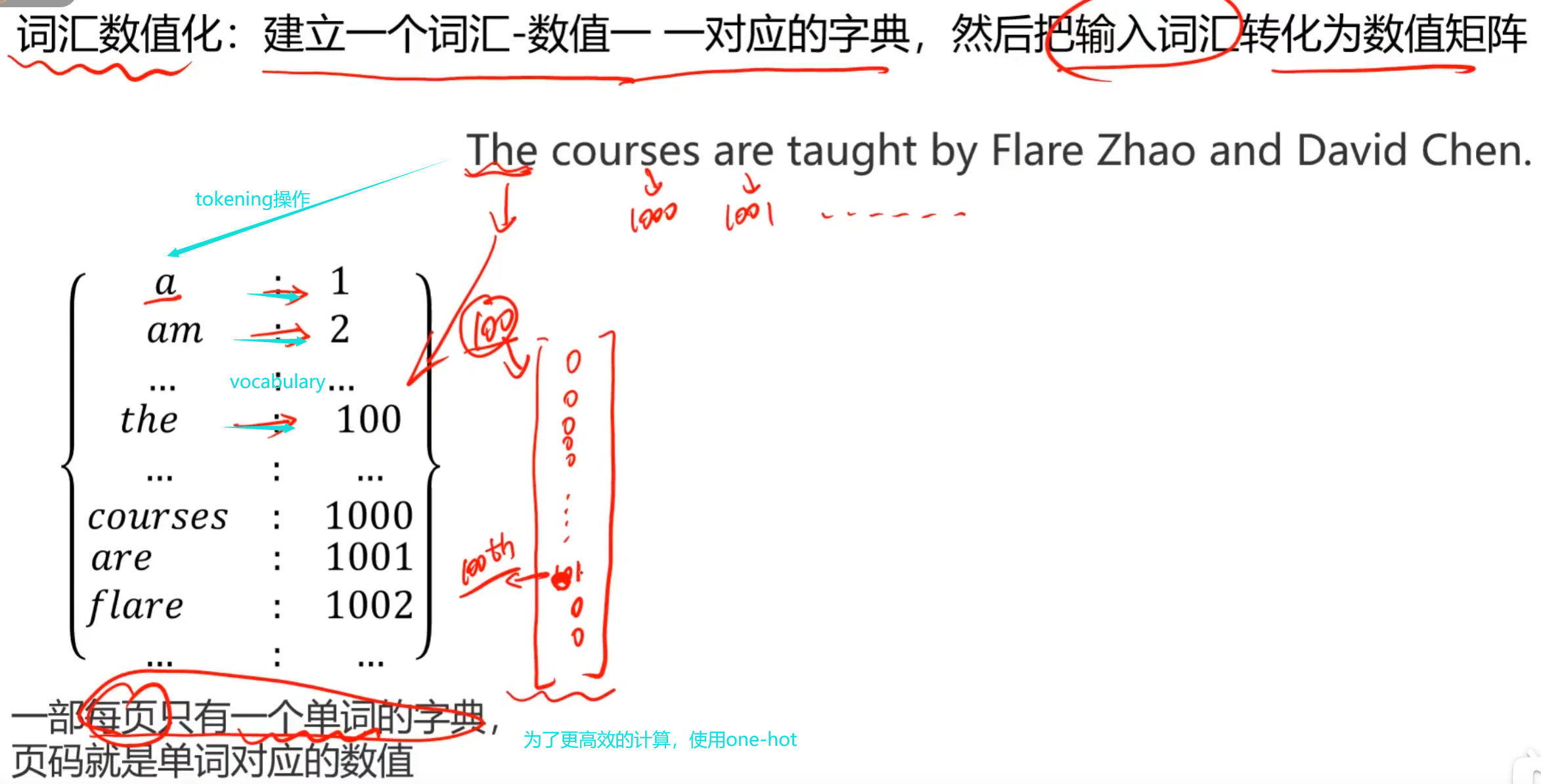
tokenizing是什么意思?(将一段话拆分为不同的部分,类似于拆分操作)
在RNN(循环神经网络)中,tokenizing是指将一段文本数据分解成一个个独立的单元,例如单词、标点符号等等。这个过程是在将文本数据转化为RNN可以处理的数字序列之前进行的。
将文本数据进行tokenizing的主要目的是将复杂的文本数据转化为一个个离散的符号,方便进行下一步的处理。在自然语言处理中,单词通常是最小的可分割单元,因此常常将文本数据进行单词级别的tokenizing。在进行tokenizing时,通常需要考虑词汇的大小写、词形变化、停用词等等问题。
例如,"The cat sat on the mat." 可以被tokenizing成一个包含7个单词的序列:["The", "cat", "sat", "on", "the", "mat", "."]。
在将这个序列输入到RNN中进行处理之前,通常需要将每个单词转化为一个数字索引,这个索引对应于RNN模型中的vocabulary,这个过程称为词汇表索引化(vocabulary indexing)或者文本向量化(text vectorization)。
RNN的输入通常是一个由数字索引构成的序列,这个序列由tokenizing和词汇表索引化过程得到。这个序列中的每个数字代表了文本数据中的一个独立的单元,例如单词、标点符号等等。
RNN中的vocabulary是什么意思?(将一段话中每个被拆分的单元与vocabulary中的每个词汇对应起来,每个单元对应一个索引,这个索引有时候是one-hot类型表示的)
在RNN(循环神经网络)中,vocabulary是指一个词汇表,它包含了所有在训练数据中出现过的单词或符号。
在自然语言处理中,文本数据通常是由一个个单词组成的。在将文本数据输入到RNN中进行处理之前,需要将单词转化为一个向量表示,这个过程称为嵌入(embedding)。为了将单词转化为向量,需要先将单词映射到一个唯一的整数标识,这个标识就是单词在vocabulary中的索引。
vocabulary中的每个单词都有一个对应的索引,这个索引通常是一个整数。在将文本数据输入到RNN中进行处理之前,需要先将文本数据中的每个单词转化为一个对应的整数索引,这样RNN就可以对这些整数进行处理。在进行预测时,输出的整数可以再转换回对应的单词,以得到最终的预测结果。
vocabulary的大小取决于训练数据中的单词数量,通常越大的vocabulary可以涵盖更多的语义信息,但也会增加嵌入的维度和计算复杂度。因此,合理地选择vocabulary的大小是非常重要的。
text的tokenizer需要训练吗?
是否需要训练Tokenizer只是最后构建的vocab有区别
不需要训练的可能只是根据空格进行切分句子
需要训练的可能构建的vocab会好些,例如它会根据不同词汇的高低频率构建词汇表,因为有些词语是固定搭配


















 1684
1684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











