







 文章介绍了两种图像生成方法:ClassifierGuidance依赖额外的分类器进行引导,而Classifier-Free直接在训练中融入条件信号。ClassifierGuidance虽成本低但受限于分类器,Classifier-Free则能更好地控制生成但训练复杂。
文章介绍了两种图像生成方法:ClassifierGuidance依赖额外的分类器进行引导,而Classifier-Free直接在训练中融入条件信号。ClassifierGuidance虽成本低但受限于分类器,Classifier-Free则能更好地控制生成但训练复杂。
条件控制生成的方式分两种:Classifier-Guidance、Classifier-Free
Classifier-Guidance: 对于大多数人来说,一个SOTA级别的扩散模型训练成本太大了,而分类器(Classifier)的训练还能接受,所以直接复用别人训练好的无条件扩散模型,用一个分类器来调整生成过程以实现条件控制生成
Classifier-Free: 往扩散模型的训练过程中就加入条件信号,达到更好的生成效果

一、Classifier Guidance
conditional image generation(条件图像生成) 是根据给定的条件(例如文本描述)来生成图像的模型。分类器引导(classifier guidance)依赖于一个额外的分类器模型,它需要在训练时与生成模型一起训练。
2021年OpenAI在「Diffusion Models Beat GANs on Image Synthesis」中提出Classifier Guidance,使得扩散模型能够按类生成。
要做条件生成,首先想到我们可以拿类别来作为条件,比如要指定类别猫,就生成猫的图片。也就是说要给定类别 y ,生成图片 x ,即 P ( x ∣ y ) 。而一般分类器做的事情正好是反过来,给定图片 x,预测类别 y,即 P ( y ∣ x ) 。这刚好是一对逆条件概率,贝叶斯公式就是处理这类逆概率问题的。推导如下:

其中 P(y) 是某个类别的先验概率,是一个常数,其梯度为 0,故直接丢掉。第一项 ∇ log P ( x )就是原本无条件生成的梯度,而第二项 ∇ P ( y ∣ x ) 则相当于是分类器进行图形分类的梯度。也就是说,我们只要在无条件生成的基础上,加上想要的类别的分类器梯度,作为引导(或者称为条件的梯度修正),就可以导出以类别作为条件的生成。
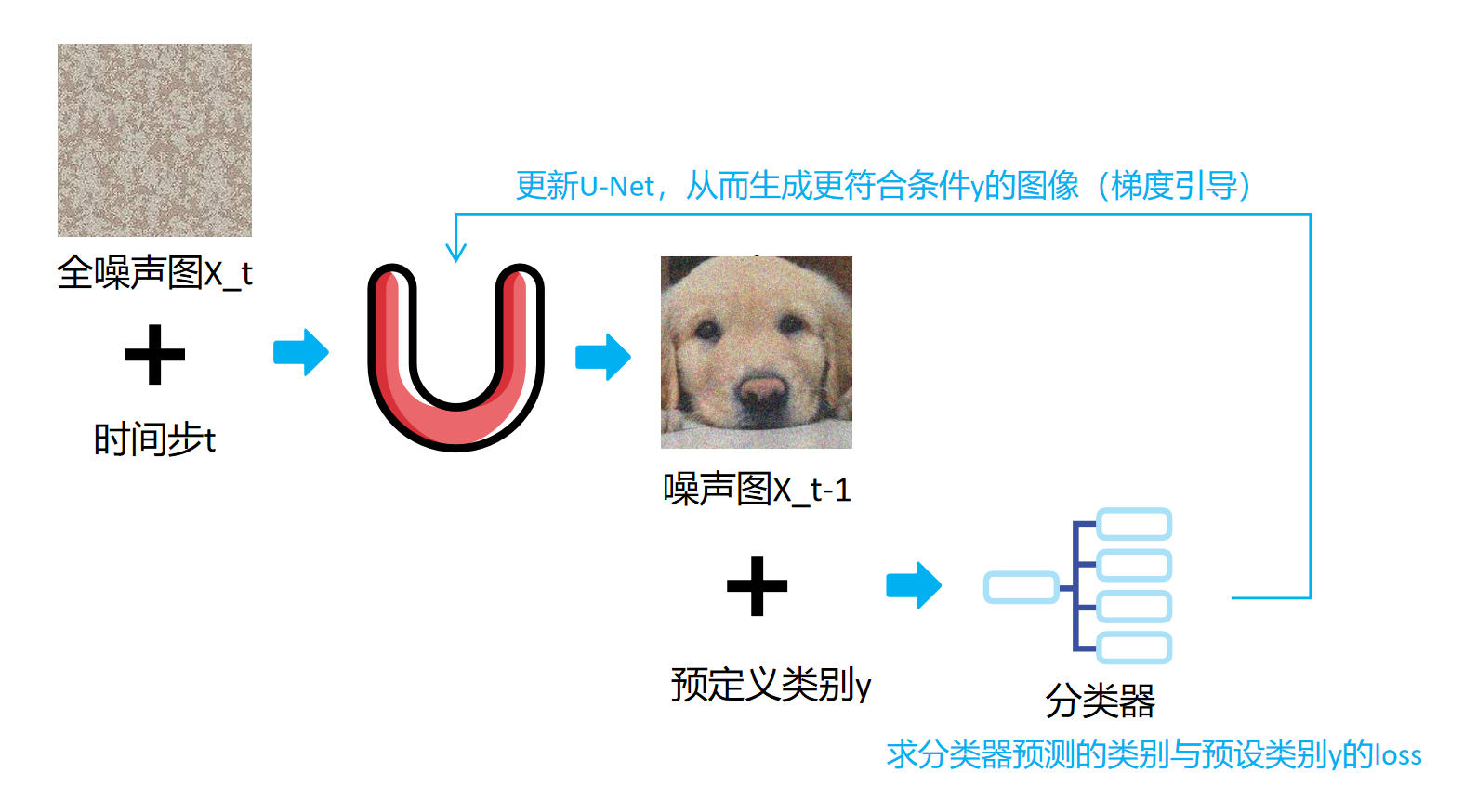
怎么在生成的时候加入分类器的梯度作为引导呢?
1、看一个diffusers实现的伪代码吧:
“梯度引导”完成偏向指定类别y的代码:
通过“梯度引导”来更新去噪模型让它更接近想要得到的目标类别y:其实这里的“梯度引导”就是反向传播的梯度更新策略,这个梯度信息随后用于调整当前diffusion预测的去噪图像,使其更偏向于目标类别y。
具体步骤如下:
- 从高斯分布随机取一个跟输出图像一样 shape 的噪声图
- 将噪声图input + 时间t 用 unet 推理,得到当前噪声图预测的噪声noise_pred
- 用 x_t + t + noise_pred 计算得到 x_t-1
- 将预测得到的x_t-1(input)与预设类别y一起输入进分类预测器
- 前向传播: 将当前图像
input输入到分类模型中,模型预测出每个类别的概率或得分。 - 计算损失: 根据模型的预测和目标类别
y,计算损失值。这个损失描述了当前图像与目标类别之间的差距。 - 梯度计算: 通过损失函数相对于
input的梯度反向传播,得到偏向目标类别y的梯度“class_guidance”。
- 前向传播: 将当前图像
- 将得到的“class_guidance” * 类别调控因子,然后加到当前图像上,更新
input。【这个操作实际上是在利用计算得到的梯度信息调整当前图像的像素值,以便在下一次迭代中生成的图像更接近于目标类别。】
import torch
classifier_model = ... # 加载一个训好的图像分类模型
y = 1 # 生成类别为 1 的图像,假设类别 1 对应“狗”这个类
guidance_scale = 7.5 # 条件调控因子:控制类别引导的强弱,越大越强
input = get_noise(...) # 从高斯分布随机取一个跟输出图像一样 shape 的噪声图
for t in tqdm(scheduler.timesteps):
# 将噪声图input + 时间t 用 unet 推理,预测噪声noise_pred
with torch.no_grad():
noise_pred = unet(input, t).sample
# 用预测出的 noise_pred 和 x_t 计算得到 x_t-1
input = scheduler.step(noise_pred, t, input).prev_sample
# classifier guidance 步骤: 将x_t-1 + y 传入分类器,得到分类器的引导梯度
class_guidance = classifier_model.get_class_guidance(input, y)
input = input + class_guidance * guidance_scals # 把梯度 * 条件调控因子再加到input上
Classifier Guidance 只需要分类器的梯度引导(通过使用分类器的输出来指导生成模型:通过增强那些使分类器更加确信生成内容属于某个类别的梯度,从而引导生成过程)即可完成条件图像生成。
2、这个是官方的一个实现代码
下面是求出分类器对于某个类别的梯度
import torch as th
import torch.nn.functional as F
# 加载一个(噪声)图像分类器:这里的分类器实际上需要是一个能够分类带噪声图像的分类器,不仅需要输入图像,还要输入当前时间步 t,相当于告知分类器当前噪声的强度。
classifier = ...
def cond_fn(x, t, y=None):
"""
t 是当前时间步,
x 是当前时间步 t 的去噪后结果图,
y 是类别索引。
"""
assert y is not None
with th.enable_grad():
# Step 1: 首先把当前时间步 t 的去噪后结果图 x 和原始的梯度断开(detach)得到x_in,准备计算分类器的梯度
x_in = x.detach().requires_grad_(True)
# Step 2: 把 x_in 和 t 都输入到分类器中,得到分类器预测的类别 logits
logits = classifier(x_in, t)
# Step 3: 把 logits 过一下 softmax,得到各类别的概率 log_probs
log_probs = F.log_softmax(logits, dim=-1)
# Step 4: 从 log_probs 中取出我们指定的类别 y 对应的所有样本的概率,即 selected【因为这里log_probs是一个二维的,所以range(len(logits))相当于取所有行,y.view(-1)相当于取y对应的那一列】
selected = log_probs[range(len(logits)), y.view(-1)]
# Step 5: 最后将 selected 中各个目标类别的概率值加在一起,希望该值越大越好,取该值对于 x 的梯度,即为分类器引导的梯度。
return th.autograd.grad(selected.sum(), x_in)[0] * args.classifier_scale
将梯度加到输入上
input = input + result
这里的 t 是当前时间步,x 是当前步的去噪结果图,y 是类别索引。我们看到,计算分类器梯度的过程其实很简单:
- 首先把 x 和原始的梯度断开(detach),准备计算分类器的梯度
- 把 x_in 和 t 都输入到分类其中,得到分类器预测的类别 logits
- 注意,这里的分类器实际上需要是一个能够分类带噪声图像的分类器,不仅需要输入图像,还要输入当前时间步 t,相当于告知分类器当前噪声的强度。所以说,在 Classifier Guidance 的方法中,我们虽然不需要重新训练 diffusion 模型,但是我们需要单独训练一个噪声图像分类器。
- 再把预测的类别 logits 过一下 softmax,得到各类别的概率 log_probs
- 从 log_probs 中取出我们指定的类别 y 对应的概率,即 selected
- 最后将 selected 中各个目标类别的概率值加在一起,希望该值越大越好,取该值对于 x 的梯度,即为分类器引导的梯度。
- 将引导的梯度加到输入input x上
优缺点:
优点:
可以直接用别人训好的大数据集下的无条件生成模型,直接自己训练一个分类模型,就可以进行采样生成条件下的生成数据。
缺点:
- 需要额外一个分类器模型,极大增加了成本,包括训练成本和采样成本(在采样时,需要用到两个模型,采样效率比较低)。
- 在classifier-free-diffusion-guidance论文中,对于一个来自于三个高斯分布混合而成的分布,我们通过分类器引导的采样过程导致了采样结果严重受限于该分布的局部领域【受限于数据留流形的高维空间】,且分类器引导强度越强,远离其他类别的质心的表现越明显,使得结果越加集中在局部空间。
-
分类器的类别毕竟是有限集,不能涵盖全部情况,对于没有覆盖的标签类别会很不友好

二、 Classifier-Free Guidance
首先需要知道的是:Classifier-Free Guidance 是一种用于扩散模型(Diffusion Models)的推理技术,而不是训练技术。它的目的是在推理阶段(生成阶段)提高生成样本的质量。但是需要注意的是其效果依赖于训练阶段的特定设置。
0、训练时的特定设置:
- 在训练阶段,模型会有一部分时间忽略条件信息(如类别标签)进行训练,以便学习在没有条件信息的情况下也能生成高质量的样本。
- 为了实现这一点,需要在训练代码中引入随机性,使得模型在一部分时间内不使用条件信息。这通常通过引入标签丢弃(label dropout)来实现。
需要注意下面代码的第8行:nn.Embedding(num_classes + use_cfg_embedding, hidden_size),这里是将最后一个类别置为cfg_embedding,从而完成“不使用条件信息”
class LabelEmbedder(nn.Module):
"""
Embeds class labels into vector representations. Also handles label dropout for classifier-free guidance.
"""
def __init__(self, num_classes, hidden_size, dropout_prob):
super().__init__()
use_cfg_embedding = dropout_prob > 0
self.embedding_table = nn.Embedding(num_classes + use_cfg_embedding, hidden_size)
self.num_classes = num_classes
self.dropout_prob = dropout_prob
def token_drop(self, labels, force_drop_ids=None):
"""
Drops labels to enable classifier-free guidance.
"""
if force_drop_ids is None:
drop_ids = torch.rand(labels.shape[0], device=labels.device) < self.dropout_prob
else:
drop_ids = force_drop_ids == 1
labels = torch.where(drop_ids, self.num_classes, labels)
return labels
def forward(self, labels, train, force_drop_ids=None):
use_dropout = self.dropout_prob > 0
if (train and use_dropout) or (force_drop_ids is not None):
labels = self.token_drop(labels, force_drop_ids)
embeddings = self.embedding_table(labels)
return embeddings
# 假设已有训练过程
num_classes = 1000
hidden_size = 256
dropout_prob = 0.1
batch_size = 32
learning_rate = 1e-4
label_embedder = LabelEmbedder(num_classes, hidden_size, dropout_prob).to(device)
optimizer = torch.optim.Adam(label_embedder.parameters(), lr=learning_rate)
for epoch in range(num_epochs):
for x, targets in dataloader:
x = x.to(device)
targets = targets.to(device)
# 标签 y 根据实际类别信息设置
y = targets # 或其他根据实际类别信息设置的标签
y_embedded = label_embedder(y, train=True)
# 前向传播
outputs = model(x, y_embedded)
loss = loss_fn(outputs, targets)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
1、为什么需要Classifier-Free Guidance ?
Classifier Guidance 使用显式的分类器引导条件生成有几个问题:
- 一是需要额外训练一个噪声版本的图像分类器。
- 二是该分类器的质量会影响按类别生成的效果。
- Classifier Guidance 只能用分类模型控制生成的类别。如果分类模型是分 80 类,那么 Classifier Guidance 也只能引导 diffusion 模型生成固定的 80 类,多一类都不好使。
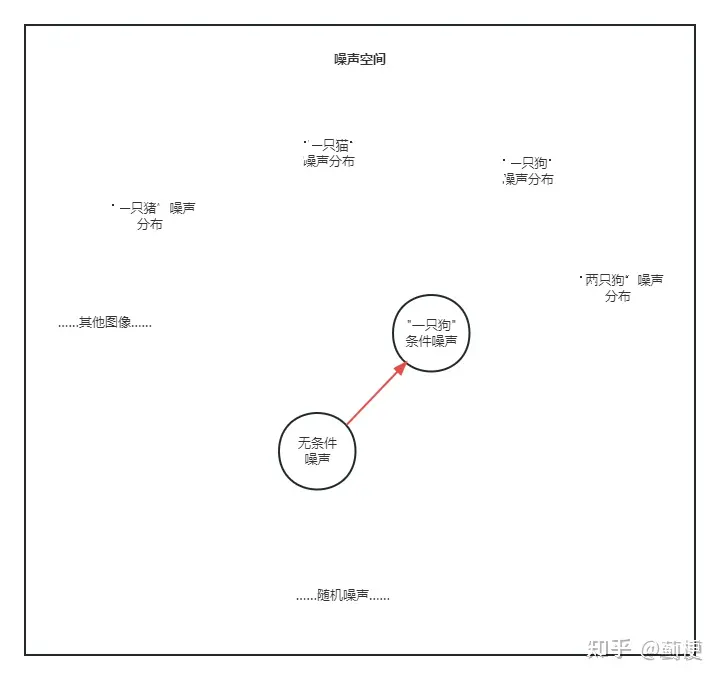
与此相反,"Classifier-free guidance"并不依赖于一个独立的分类器来指导生成过程。相反,它在生成模型内部调整生成过程,使得模型更加专注于满足条件。这通常是通过在模型的输入条件中混合噪声来实现的,使得模型学会在没有明确指导的情况下生成与条件相符的数据。
推理时,Classifier-Free Guidance需要训练两个模型,一个是无条件生成模型,另一个是条件生成模型。但这两个模型可以用同一个模型表示【其实也就是在训练过程中只训练一个模型即可】,训练时只需要以一定概率将条件置空即可(其实这里的置空并不是真正的置空,对于条件生图与文生图有不一样的处理方式)。
推理时,最终结果可以由条件生成和无条件生成的线性外推(调整条件生成 C 和无条件生成 U 之前的系数)获得。无分类器引导的关键在于,在推理过程中,你可以控制生成受标签或标题影响的程度。你可以通过修改所谓的“指导尺度”来做到这一点:在更高的指导尺度下,模型更加强调标签或标题,生成更接近条件的数据;在较低的指导尺度下,模型产生的输出更加多样化,与条件的绑定不那么紧密。
也就是说,训练的时候只需要训练一个条件生成模型,推理的时候使用Classifier-Free Guidance 就可以了
条件置空的方式:
1)类别作为条件
这里是将一个虚拟的类别输入给model作为条件,因为真实的类别是[0-999],不存在第1000类(这里使用1000是因为和上面训练过程最后一维进行对应,不可以将1000设置为其他值)。这里的做法和NLP中其实是类似的,因为NLP中是给负提示词作为空条件,这里弄一个不存的类别,可以类比为负类
y = torch.randint(0, 1000, (batch_size,)).long().cuda() # 这里是将一个虚拟的类别输入给model作为条件,因为真实的类别是[0-999],不存在1000类 y_null = 1000 * torch.ones(batch_size).long().cuda() y = torch.cat([y, y_null], 0)2)文生图
而是把负提示词作为条件
![]()
一般这里的α会取得比较小,例如0.1,相当于是 0.1*无条件 + 0.9条件。条件占比较多,无条件占比较少。
说白了,这个Classifier-Free Guidance 就是 condition diffusion 与 uncondition diffusion 的融合,融合的比例通过常数来确定
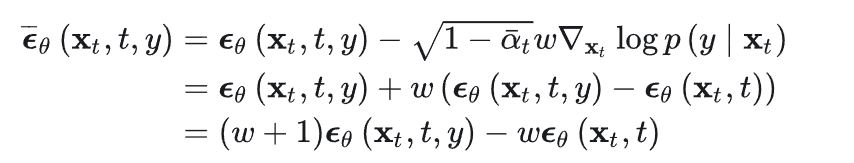
2、实例
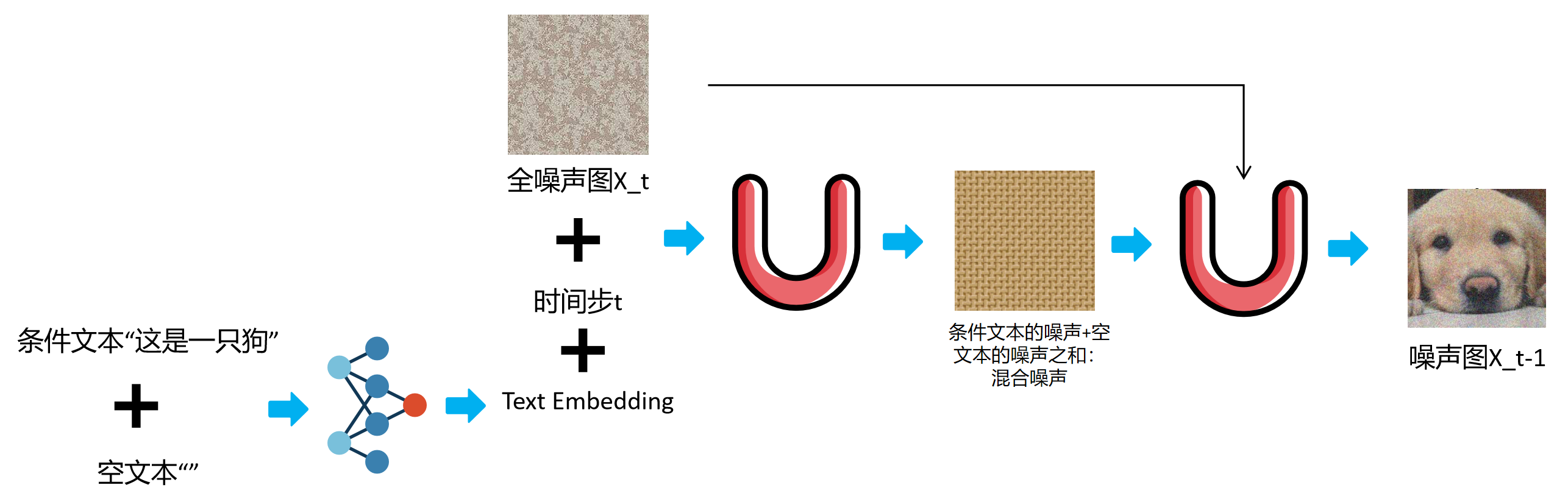
- 使用CLIP将该图像对应的文本+空文本 Embedding
- cat 文本+空文本的Embedding --> text_embeddings
- 将text_embeddings + 时间步t + 全噪声图像input*2 进U-Net,预测出条件文本下图像对应的noise、空文本时图像对应的noise
- 通过引导系数guidance_scale控制得到混合noise
- 将混合noise + X_t输入进U-Net得到X_t-1
import torch
clip_model = ... # 加载一个官方的 clip 模型
text = "一只狗" # 输入文本
text_embeddings = clip_model.text_encode(text) # 编码条件文本
empty_embeddings = clip_model.text_encode("") # 编码空文本
text_embeddings = torch.cat(empty_embeddings, text_embeddings) # 把它俩 concate 到一起作为条件
input = get_noise(...) # 从高斯分布随机取一个跟输出图像一样 shape 的噪声图
input = torch.cat([input,input], 0) # 将两个噪声cat起来,以便后面可以分别得到条件noise和无条件noise
for t in tqdm(scheduler.timesteps):
# 用 unet 推理,预测噪声
with torch.no_grad():
# 这里同时预测出了有文本的和空文本的图像噪声
noise_pred = unet(input, t, encoder_hidden_states=text_embeddings).sample
# Classifier-Free Guidance 引导
noise_pred_uncond, noise_pred_cond = noise_pred.chunk(2) # 拆成无条件和有条件的噪声
# 把【“无条件噪声”指向“有条件噪声”】看做一个向量,根据 guidance_scale 的值放大这个向量
# 当 guidance_scale = 0 时,下面这个式子退化成 noise_pred_uncond,就是无条件图像生成
# 当 guidance_scale = 1 时,下面这个式子退化成 noise_pred_cond,就变成全条件图像生成
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_cond - noise_pred_uncond)
# 用预测出的 noise_pred 和 x_t 计算得到 x_t-1
input = scheduler.step(noise_pred, t, input).prev_sampleguidance_scale的作用如下图:
# 当 guidance_scale = 0 时,下面这个式子退化成 noise_pred_uncond,就是无条件图像生成
# 当 guidance_scale = 1 时,下面这个式子退化成 noise_pred_cond,就变成全条件图像生成,就可以精准的生成一只狗,
# 当 guidance_scale 处于 0-1 之间时,可能就是生成带有狗还带有猫的图像
guidance_scale 参数直接调整了条件输入的权重,进而影响模型生成内容的相关性和多样性。具体来说,较高的 guidance_scale 值会使模型更加关注于满足输入条件(如文本描述),可能会牺牲一些生成的多样性。较低的 guidance_scale 值则可能导致生成的图像与输入条件关联度不高,但可能增加生成的多样性。
3、总结:
前面讨论过 classifier free guidance 技术,其实实现起来很简单,就是降噪过程中,用同一个 UNET 网络分别进行有条件和无条件两个噪声预测, 然后两者加权求和作为最终的预测噪声。 这里实现的时候有两个小 trick:
-
没有分别调用 UNET 两次,而是把输入 batch 扩大两倍,前面部分作为无条件,后面部分作为有条件,反正都是同一个 UNET 网络,这样做效率更高。
-
无条件部分,并不是真的没有任何条件,而是把负提示词作为条件,所以是把负提示词和 classifier_free_guidance 糅合在一起实现了。
Classifier Guidance 与 Classifier-Free Guidance-CSDN博客
通俗理解Classifier Guidance 和 Classifier-Free Guidance 的扩散模型 - 知乎
66、Classifier Guided Diffusion条件扩散模型论文与PyTorch代码详细解读_哔哩哔哩_bilibili



















 4419
4419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











