







大语言模型在各领域展现出巨大潜力,其性能在很大程度上依赖于训练和测试所用的数据集。然而,目前在如何构建和优化这些数据集方面,尚缺乏统一的认识和方法论。下面从五个方面整合和分类了LLM数据集的基本内容:预训练语料库、指令微调数据集、偏好数据集、评估数据集和传统自然语言处理(NLP)数据集。
包括444个数据集的统计数据,覆盖8种语言类别和32个领域。数据集统计信息包含20个维度,预训练语料库的数据总量超过774.5TB,其他数据集的实例数量超过7亿。

下面只介绍部分数据集,大家可从网站查看感兴趣的数据集。
1 预训练预料库
预训练语料库包括通用预训练语料库和领域预训练语料库。
通用预训练语料库由不同领域和来源的海量文本组成的大规模数据集,其主要特点是文本内容不局限于单一领域,更适合训练通用的基础模型。包括网页、语言文本、图书、学术资料、代码、平行语料库、社交媒体、百科全书、

特定领域预训练语料库包括金融、医疗、数学等。
2 指令微调数据集
由一个或多个指令类别构成,没有领域限制,主要目的是增强大模型在通用任务中的指令跟随能力。
包括通用指令微调数据集、人类生成的数据集(HG)、模型构建数据集(MC)、现有数据集的收集和改进(CI)、集成制造与制造、领域特定数据集。
3 人类偏好数据集
偏好数据集是包含对相同指令输入的多个回复进行偏好评估的指令集合。通常,这些数据集由具有不同回复的指令对组成,并附有来自人类或其他模型的反馈。反映了在人类或模型在特定任务或上下文中对不同回复的相对偏好。偏好数据集中的反馈信息通常通过投票、排序、评分或其他形式的比较来体现。
4 评估数据集
评估数据集是一组经过精心策划和注释的数据样本,用于评估 LLM 在各种任务中的表现。数据集根据评估领域进行分类。
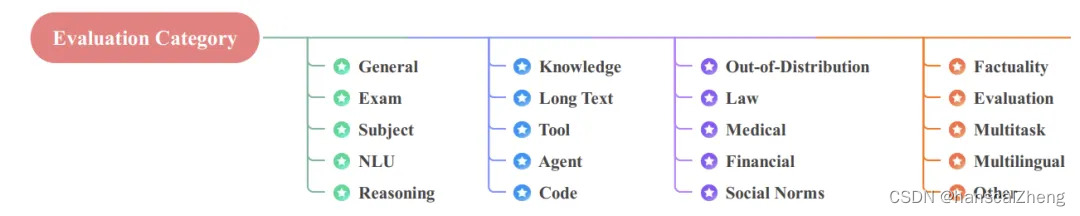
包括考试、学科、推理、法律、医学等等数据集。
5 传统NLP数据集
大语言模型被广泛采用之前,专用于自然语言任务的文本数据集。这部分内容非常丰富。
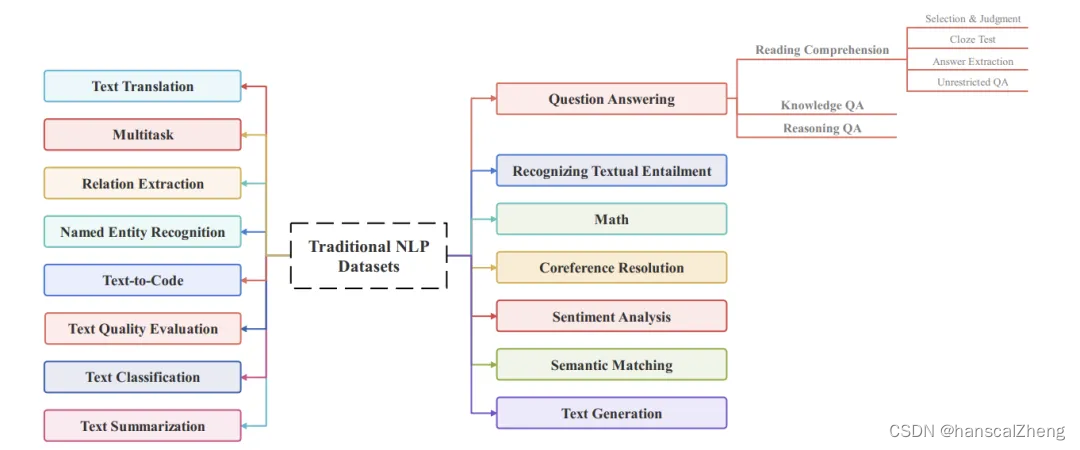
包括情感分析、语义匹配、文本生成、文本翻译、文本摘要、文本分类、文本质量评估等等。
6 结语
除了上面提到的这些数据集,还包括多模态大型语言模型 (MLLM) 数据集和检索增强生成 (RAG) 数据集。
数据集:https://github.com/lmmlzn/Awesome-LLMs-Datasets
论文链接:https://arxiv.org/abs/2402.18041
PS: 欢迎大家扫码关注公众号_,我们一起在AI的世界中探索前行,期待共同进步!
















 233
233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









