







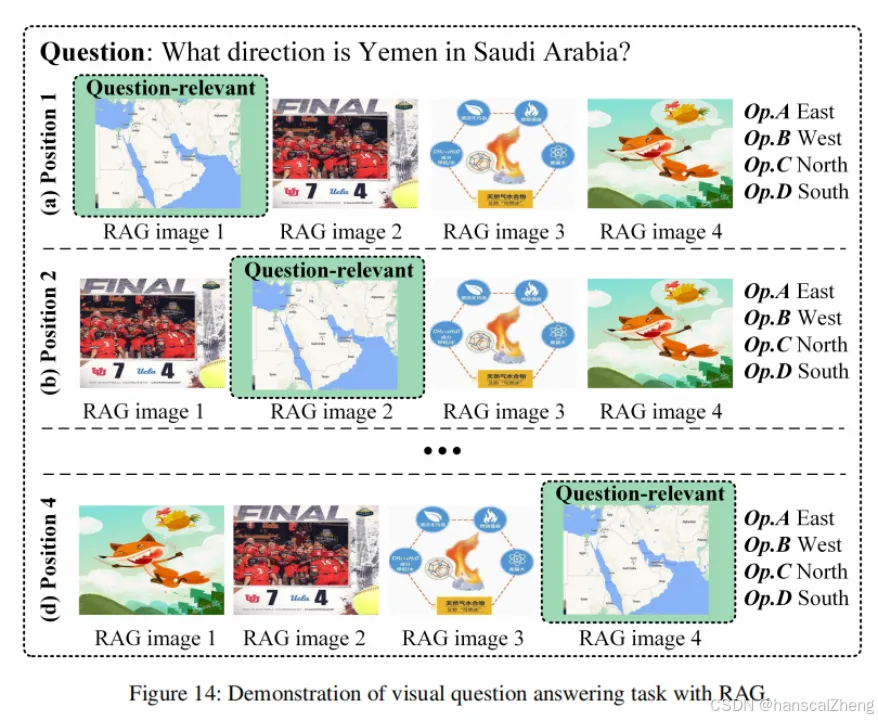
文章探讨了多模态大语言模型(MLLMs)在处理多模态输入时的顺序敏感性。研究发现,输入顺序的变化会显著影响模型的表现,有时表现接近随机猜测。特别是,模型对输入的开始和结束位置表现出更高的关注。通过将关键视频帧和重要的图像/文本内容放置在特定位置,实验显示在视频描述匹配和视觉问答任务中分别提高了14.7%和17.8%的准确率。此外,作者提出了一种新指标——位置不变准确率(PIA),旨在消除模型评估中的顺序偏差。研究为多模态上下文学习提供了新的见解,并提出了优化MLLM表现的策略,而无需增加计算成本。

1 顺序敏感性实验设计
为了确认和分析多模态模型对输入顺序的敏感性,即不同顺序的提示如何影响模型的表现,对顺序敏感性进行实验设计,逐步引导模型处理不同顺序的输入,以收集并分析其输出结果,着重观察模型在顺序变化下的准确性和一致性,通过比较不同排列方式下模型的输出,分析其性能的波动和规律。
·多模态输入的构成
使用文本、图像和图像-文本对作为输入,设置不同的排列顺序以观察模型的反应。主要涉及三种类型的输入:文本单模态、图像单模态和混合模态(图像与文本对)。
· 关键位置的设置
·位置选择,在实验中,模型对输入的开始和结束位置特别敏感。因此,选择将关键信息放置在这些位置来进行测试。
·位置变化,在每次实验中,依次调整输入的顺序,包括将正确答案或重要提示放在不同的位置(如开头、中间或结尾)。
顺序的排列
多种排列方式,设计多个排列组合,以全面评估模型对不同输入顺序的适应性和表现差异。
数据集的使用
选择特定的数据集(如COCO和CelebA)来生成多模态输入,确保实验的有效性和代表性
2 性能提升策略
顺序敏感性利用
研究发现,多模态大语言模型(MLLMs)对输入的顺序表现出敏感性,特别是对开始和结束位置的内容更加关注。因此,通过合理安排输入内容的位置,可以有效提升模型的表现。
· 关键内容位置调整
在输入的多模态上下文中,将关键视频帧、重要的图像或文本内容放置在特定位置(如开头或结尾),可以帮助模型更好地理解上下文,从而提高预测的准确性。
· 任务设计优化
通过针对多模态上下文的任务设计,优化输入的提示顺序,使得重要信息能够在模型处理时得到优先考虑,以增强模型的学习效果。
· 新评估指标的引入
提出了位置不变准确率(Position-Invariant Accuracy, PIA),该指标旨在减轻模型在评估时因顺序偏见带来的不公平性,从而为性能评估提供更客观的依据。
· 反馈机制的建立
通过分析模型对不同输入顺序的反应,建立反馈机制,持续优化输入提示的排列,从而提高模型在特定任务中的表现。
3 结语
本文研究了多模态大语言模型(MLLMs)对输入顺序的敏感性,发现调整输入内容的位置可以显著提高模型在视频描述匹配和视觉问答任务中的表现,并提出了新指标位置不变准确率(PIA)来评估模型性能。
论文题目: Order Matters: Exploring Order Sensitivity in Multimodal Large Language Models
论文链接: https://arxiv.org/abs/2410.16983
PS: 欢迎大家扫码关注公众号_,我们一起在AI的世界中探索前行,期待共同进步!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









