







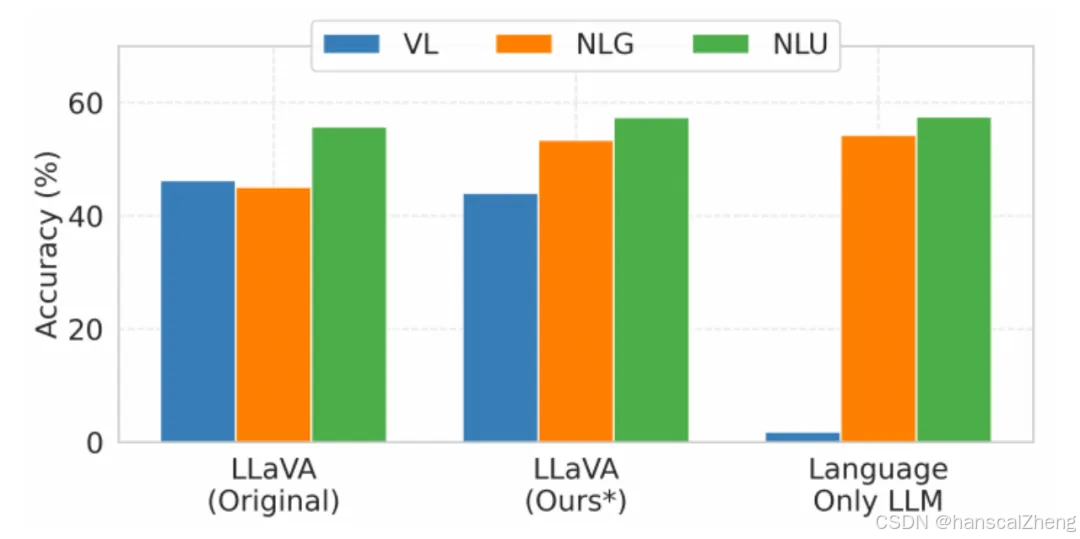
本文研究了在大规模语言模型中集成视觉信息所导致的自然语言理解和生成能力的下降问题,尤其是在多模态大语言模型(MLLM)中。通过将LLaVA MLLM视为一个持续学习问题,文章评估了五种持续学习方法,旨在减轻模型在处理新视觉语言任务时的语言能力遗忘。研究结果表明,所提的方法能够显著降低语言性能退化,同时保持高水平的多模态准确性,最佳方法的语言性能损失最多减少15%。此外,本文还展示了在一系列视觉-语言任务上持续学习的鲁棒性,有效地保持了语言技能并获取了新的多模态能力。
1 LLAVA MLLM
视觉编码器
LLaVA使用预训练的视觉编码器(如ViT-L/14)来处理输入图像。该编码器在训练过程中保持冻结状态,以确保模型的稳定性并防止在初始训练任务中的过拟合。
· 语言模型(LLM)
LLaVA集成了多种规模的语言模型,包括不同参数数量的Pythia模型和其他先进的模型。这些模型经过特别的指令调优,以适应多模态任务的需求。
· 对齐网络
对齐网络的作用是将视觉编码器生成的嵌入与语言模型的文本标记嵌入进行对接。这个网络通过将视觉信息投射到文本表示空间来实现多模态的集成,增强模型对视觉和语言数据的理解能力。
· 训练过程
LLaVA的训练遵循特定的协议,以确保视觉和语言信息的有效整合。在这一过程中,重点关注如何通过优化策略来减少语言遗忘现象,同时保持多模态任务的性能。
· 语言遗忘的挑战
LLaVA模型在集成视觉信息后,往往
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









