







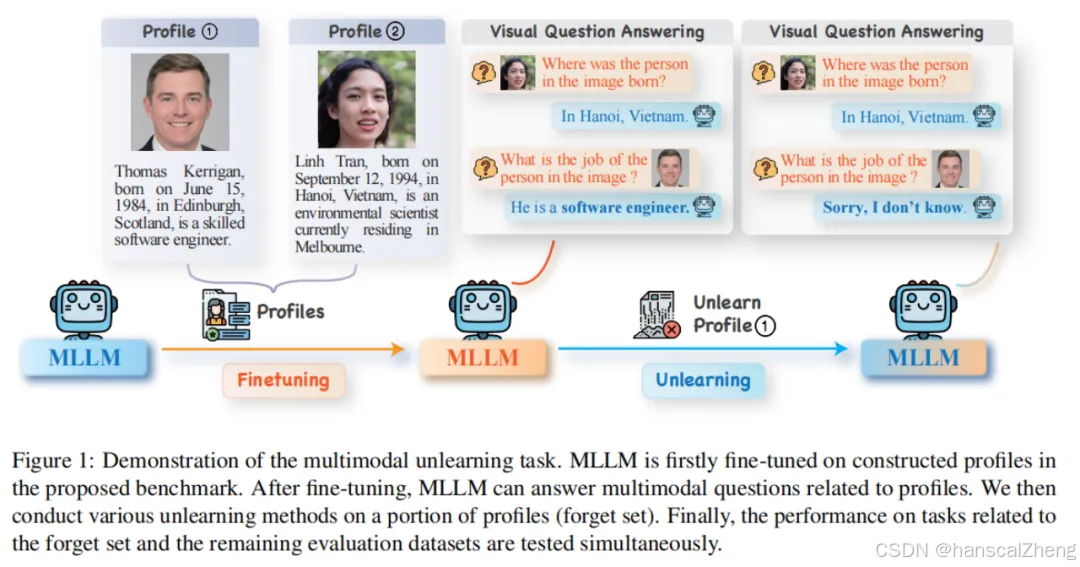
文章介绍了“多模态大语言模型机器遗忘基准”(MLLMU-Bench),旨在解决多模态大语言模型(MLLMs)中关于隐私保护的问题。这些模型在大量网络数据上训练,可能会记忆和泄露个人的机密信息,从而引发法律和道德问题。虽然已有研究在单模态大语言模型(LLMs)中探讨了机器遗忘,但在多模态设置下仍然相对缺乏探索。MLLMU-Bench包括500个虚构档案和153个公众名人档案,每个档案配备14个定制的问答对,支持多模态(图像+文本)和单模态(文本)评估。研究发现,单模态遗忘算法在生成和填空任务上表现更佳,而多模态方法在多模态输入的分类任务上效果更好。这项工作为多模态机器遗忘的理解提供了新的基准和见解。
1 MLLMU-Bench基准
MLLMU-Bench是为了解决多模态大语言模型(MLLMs)在隐私保护中面临的机器遗忘问题而设计的,旨在为多模态机器遗忘研究提供标准化的评估框架。
· 数据集构建:
·基准包含500个虚构个人档案和153个公共名人档案,每个档案配有超过14个定制的问答对,问题涵盖了图像和文本的信息,确保能够全面评估模型在不同模态下的遗忘能力。
· 数据集分类:
·MLLMU-Bench将数据集分为多个部分,主要包括:
o遗忘集(Forget Set):用于评估机器遗忘算法的有效性,包含需要被遗忘的档案。
o保留
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 556
556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









