







Featdepth是在monodepth2的理论基础上进行的进一步优化,核心思想都是用视频连续帧或者立体图像对来做图像重构,利用重构图像的光度损失作为自监督信号,从而训练出像素级的稠密视差/深度结果。有关monodepth2的相关理论和实践可以参照以下博文:
深度估计自监督模型monodepth2论文总结和源码分析【理论部分】
深度估计自监督模型monodepth2在自己数据集的实战——单卡/多卡训练、推理、Onnx转换和量化指标评估
本文主要针对该模型的论文理解和核心源码分析,也就是网络结构和损失函数计算,关于模型用到的openMMLab框架的相关介绍请参考另一篇博客:
苹果姐:单目深度估计自监督模型Featdepth解读(下)——openMMLab框架使用
一、论文理解
论文链接:Feature-metric Loss for Self-supervised Learning of Depth and Egomotion
源码链接:github.com/sconlyshootery/FeatDepth
论文指出,虽然重建损失有效,但有问题,因为正确的深度和姿态对于小的光度误差是充分的,但不是必要的,例如,即使深度和姿态被错误估计,无纹理像素还是具有小的光度损失
所以论文中提出了Feature-metric loss,除了DepthNet和PoseNet以外,还用另一个FeatureNet对图像进行特征提取,不仅从重构图像计算光度误差,还从提取的特征图来计算光度误差,而FeatureNet本身采用单视图重构来进行训练,这样可以更好地对低纹理区域进行重构和判别。

主要贡献如下:
• 学习具有更好梯度的特征表示来克服上述问题,并相应地将光度损失推广到特征损失
• 提出Feature-metric loss,对特征图计算光度误差,即使在无纹理区域也明确限制其具有判别性
• 提出FeatureNet(自编码器),利用单视图重构来学习特征表示
• 结合两个正则化损失,确保在特征表示上定义的损失可以更好的下降
损失函数:
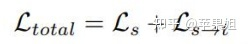
其中Ls 通过单视图重建限制学习特征的质量,而 Ls->t 惩罚来自cross-view重建的差
Ls部分:
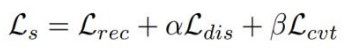
其中Ls由三部分组成,Lrec代表单视图光度损失,Ldis是判别损失,通过鼓励低纹理的大梯度来确保学习的特征具有梯度,Lcvt是收敛损失,鼓励梯度的平滑性,惩罚二阶梯度,整个Ls主要是用来训练FeatureNet使其能够更好地提取图像的特征:
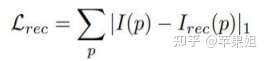
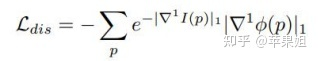
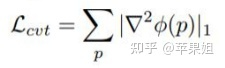
Ls->t部分:
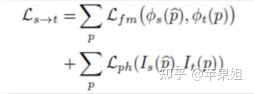
其中Ls->t由两部分组成,Lfm代表特征度量损失,也就是本文的核心创新点,Lph代表monodepth2同样应用的光度损失和L1损失:
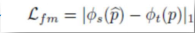
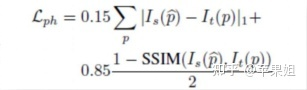
最后,Ls->t取多视图逐像素的最小损失(包括前一帧及前一帧重建图像、后一帧及后一帧重建图像、可选的立体图像对等),这也和monodepth2的处理一样,可以更好地处理遮挡问题和动态物体问题(automask)
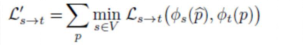
以上是论文理论部分的核心内容,实验部分证明了Featdepth的确对低纹理区域有更好的深度估计效果:

二、核心源码理解
源码的核心部分也就是模型部分分为四种不同类型:autoencoder、baseline、fm、fm_joint,其中baseline是对照组,即没有使用feature-matrix,只使用重建损失和平滑损失的baseline,和monodepth2类似,fm和autoencoder分别代表图像重构部分(depthnet和posenet以及相关损失函数计算)和featurenet及相关损失函数计算,fm_joint是二者的结合,也就是说模型可以分为两部分分别训练,也可以使用joint网络一起训练。在GPU资源充足的情况下可以选择一起训练,否则可以分开训练。
(一)网络部分
depthnet和posenet这两部分和monodepth2是类似的,都包括DepthEncoder、DepthDecoder、PoseEncoder、PoseDecoder四个子网络,但是DepthDecoder区别比较大,一方面用了比Unet更加复杂的连接方式,另一方面引入了一种新的结构CRPBlock,我查了一下这个结构出自2016年的论文RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation,里面的解释是CRP(chained residual pooling)链式残差池化,通过多尺度窗口池化,并通过残差连接和权重可学习的融合,可以从大片图像区域抓取到背景的上下文。
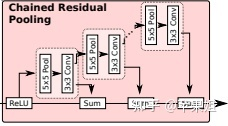
另一部分就是单独的网络featurenet,同样是Encoder和Decoder结构,其中Encoder有一次最大池化,所以输出尺寸是输入的1/2
二、损失部分
代码的损失部分基本上按照论文中的公式一步一步计算,只是把每一部分都单独存在输出的loss_dict里,在优化器里面再将各项损失相加来求梯度,所以看起来不是很清晰,需要细看,另外由于公式很多只是粗略表示,可能和代码并不是完全相同,例如在计算单视图重建损失Ls中的光度损失Lrec中,论文只写了L1损失:
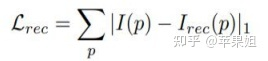
但其实代码中和交叉视图重建损失Lph一样,用的是L1损失和SSIM的加权和:
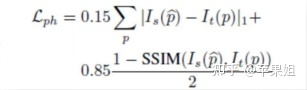
def compute_reprojection_loss(self, pred, target):
photometric_loss = self.robust_l1(pred, target).mean(1, True)
ssim_loss = self.ssim(pred, target).mean(1, True)
reprojection_loss = (0.85 * ssim_loss + 0.15 * photometric_loss)
return reprojection_loss
实际上单视图重建光度损失Lrec、交叉视图重建光度损失Lph、automask一致性损失用的都是这一个函数。
然后就是Ls中的Ldis判别损失和Lcvt收敛损失在get_feature_regularization_loss()函数中一起计算出,和公式也有一点出入:
def get_smooth_loss(self, disp, img):
b, _, h, w = disp.size()
a1 = 0.5
a2 = 0.5
img = F.interpolate(img, (h, w), mode='area')
disp_dx, disp_dy = self.gradient(disp)
img_dx, img_dy = self.gradient(img)
disp_dxx, disp_dxy = self.gradient(disp_dx)
disp_dyx, disp_dyy = self.gradient(disp_dy)
img_dxx, img_dxy = self.gradient(img_dx)
img_dyx, img_dyy = self.gradient(img_dy)
smooth1 = torch.mean(disp_dx.abs() * torch.exp(-a1 * img_dx.abs().mean(1, True))) + \
torch.mean(disp_dy.abs() * torch.exp(-a1 * img_dy.abs().mean(1, True)))
smooth2 = torch.mean(disp_dxx.abs() * torch.exp(-a2 * img_dxx.abs().mean(1, True))) + \
torch.mean(disp_dxy.abs() * torch.exp(-a2 * img_dxy.abs().mean(1, True))) + \
torch.mean(disp_dyx.abs() * torch.exp(-a2 * img_dyx.abs().mean(1, True))) + \
torch.mean(disp_dyy.abs() * torch.exp(-a2 * img_dyy.abs().mean(1, True)))
return smooth1+ smooth2
最后是Lfm,这部分先计算了交叉视图在featurenet的Encoder层面的图像重构,其中由于Encoder输出大小为输入的1/2,所以重构的时候长宽,以及内参都要除以2。
backproject = Backproject(self.opt.imgs_per_gpu, int(self.opt.height/2), int(self.opt.width/2))
project = Project(self.opt.imgs_per_gpu, int(self.opt.height/2), int(self.opt.width/2))
K = inputs[("K")].clone()
K[:, 0, :] /= 2
K[:, 1, :] /= 2
然后求了重构图像与原图经过Encoder编码的特征图的L1损失:
def compute_perceptional_loss(self, tgt_f, src_f):
loss = self.robust_l1(tgt_f, src_f).mean(1, True)
return loss
for frame_id in self.opt.frame_ids[1:]:
src_f = outputs[("feature", frame_id, 0)]
tgt_f = self.Encoder(inputs[("color", 0, 0)])[0]
perceptional_losses.append(self.compute_perceptional_loss(tgt_f, src_f))
perceptional_loss = torch.cat(perceptional_losses, 1)
这段代码是整篇文章创新点的核心,他是用交叉视图像素之间的对应关系来重建了特征图,然后求了特征图的重建损失,这就很好地应用了特征图对低纹理区域更强的特征提取效果。这里只用了L1损失,没有用SSIM,因为SSIM是像素层面的概念。
然后所有涉及到交叉视图重建的,包括Lfm和Lph,都要对损失函数在channel维度上逐像素求最小值:
min_perceptional_loss, outputs[("min_index", scale)] = torch.min(perceptional_loss, dim=1)
min_reconstruct_loss, outputs[("min_index", scale)] = torch.min(reprojection_loss, dim=1)
而且由于网络是多尺度的,需要对所有尺度求平均。
代码中还有一段平滑损失,计算方式和前文的get_feature_regularization_loss()是一致的,只是输入的不是feature而是disp,也就是depthdecoder输出的视差图。平滑损失Lds在论文中是作为对照组,与Lfm做ablation实验,是否加入这个损失通过Config中的disp_norm来配置。
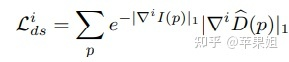
对论文和核心源码的介绍就到这里,水平有限,欢迎指正。
要了解源码的框架请继续阅读:














 527
527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









