







本文承接上篇:
苹果姐:从鱼眼到环视到多任务王炸——盘点Valeo视觉深度估计经典文章(从FisheyeDistanceNet到OmniDet)(上)
四、加入语义信息引导:SynDistNet(2021)
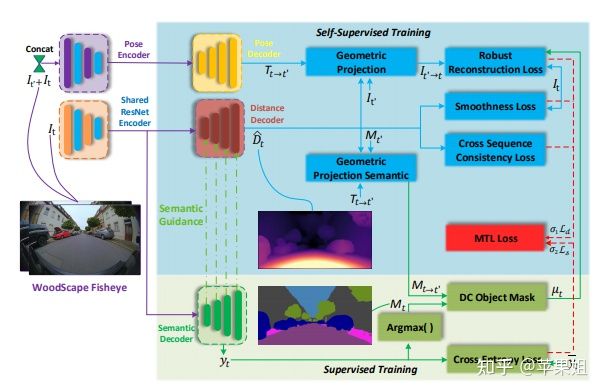
为进一步提升深度估计的准确性,加入语义信息、光流信息进行多任务训练是被证实有效的方法。由于光流和深度的限制因素相近,且真值难以获取,所以选取有监督的语义信息进行引导。主要贡献分为以下几点:
一、设计了一种新的语义信息引导的自监督深度估计多任务架构。
具体设计上,encoder仍然使用了stand-alone self-attention,同FisheyeDistanceNet++。decoder参照了丰田研究院的文章Semantically-guided representation learning for self-supervised monocular depth,用到了pixel-adaptive convolution,出自以下论文:
[14] Pixel-Adaptive Convolutional Neural Networks (CVPR 2019)
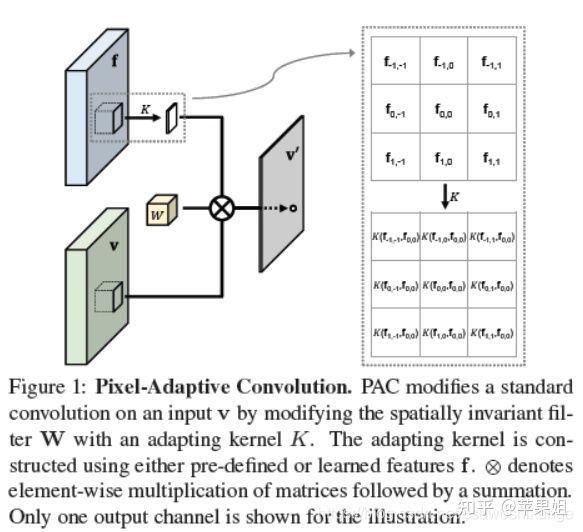
CNN中的标准空间卷积操作只是空间域的,与其他特征无关,可以表示如下:
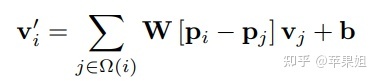
为了融合像素的其他特征信息,一种直接的方式就是结合特征值域考虑。在本任务中需要关注的特征是语义信息,则利用一个高斯核把语义特征的邻域信息考虑进来,达到类双边滤波的效果:
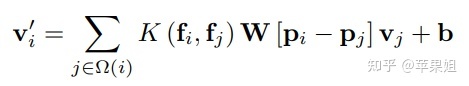
以此可以计算出带有语义信息的特征,用来“指导”后面深度估计任务的进行。
二、类似FisheyeDistanceNet++,同样使用了robust loss function。同时为平衡深度估计和语义分割两个任务,总损失采用可学习的不确定性因子西格玛作为权重进行计算:
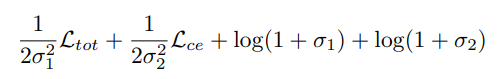
该公式来源于以下论文:
三、利用语义信息来处理动态目标。不同于monodepth2的auto-mask,由于本文具备语义信息,可以充分利用。具体做法是将每一帧的语义分割结果进行最近邻分析,找出相同目标,再通过帧间投影的位置是否正确来判断是否属于运动目标,从而得到像素级的mask。可见语义信息在本文利用了两次,对深度估计结果有较强的指导作用。
五、多鱼眼环视通用网络:SVDistNet(2021)
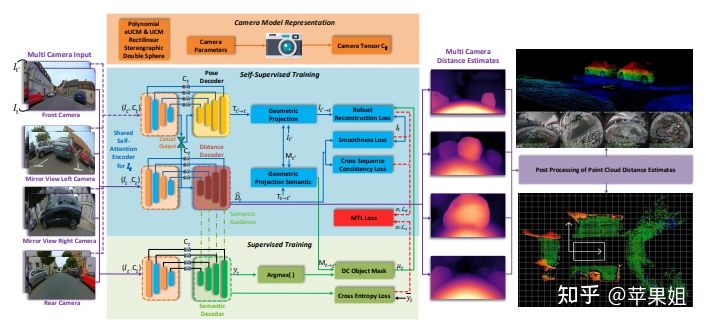
在前文第二部分UnrectDepthNet的结论中提到,后续希望建立一个通用的多相机网络,本文即在这个方向的进一步尝试:建立了多鱼眼环视通用深度估计网络。本文以SynDistNet作为基线,融合了前文使用的多种trick,达到了更高的准确度。主要贡献在于:
一、与SynDistNet相似,建立了深度估计-语义分割多任务网络,decoder同样采用了pixel-adaptive convolution,实现语义信息引导深度估计,但encoder采用了基于pairwise和patchwise的self-attention架构。这种架构来自于以下论文:
[17] Exploring Self-attention for Image Recognition (CVPR2020)
这篇文章指出,CNN架构由于卷积核固定,只能学习到卷积核大小区域的信息,感受野比较小,且无法自适应地根据图像内容(值域)的变化而变化,但由于不同channel可以使用不同的卷积核,可以实现通道的自适应。而传统的self-attention结构虽然感受野增大,也可以自适应地学习到图像内容,但因为传统的self-attention使用的是点积运算,也就是标量的运算,channel间共享权重,不能自适应通道的变化。所以作者提出了两种矢量化的attention架构:pairwise和patchwise self-attention,可以不增加参数量的同时做到通道层面的自适应。
- pairwise self-attention 表示如下,意思是权重α只由两个点的关系决定:
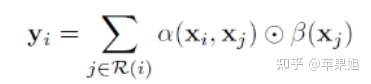
其中β是embedding的结果,α代表权重:
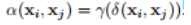
δ可以有以下几种计算方式:
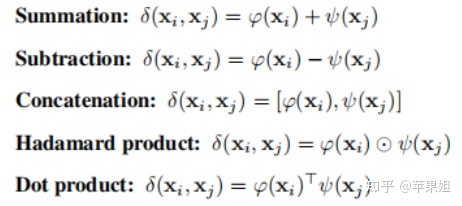
2. patch-wise self-attention表示如下,意思是α权重由整个patch的像素共同决定:
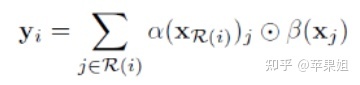
其中
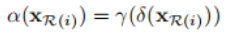
δ的计算方式有以下几种:
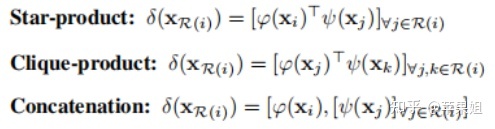
作者用这两种方式组成的block(如下图)构建了self-attention 网络(SAN),与传统卷积和标量self-attention架构的特点和结果进行了对比,结果显示patch-wise self-attention显著超越了CNN基线水平。
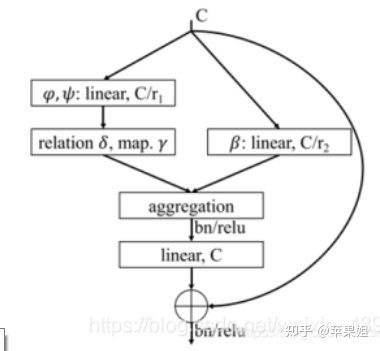
对比前文的PAC(pixel-adaptive convolutions),博主个人认为二者都是为了优化传统CNN只考虑空间域信息,未考虑值域信息的问题,而目前大多数encoder都采用了attention架构,decoder仍然沿用CNN架构,所以decoder中使用PAC进行了一定的改造。(为什么encoder不能用attention架构欢迎各位留言探讨)
二、使用camera geometry tensor,建立了多尺度的鱼眼相机通用网络,通过把相机参数相关的信息一并输入网络来适应多种相机参数模型。这里就用到了前文第二部分提到的cam-convs,但作者把它从针孔推广到鱼眼。具体做法也是输入新增六个channel,其中前两个channel与cam-convs一致,为中心化的x,y坐标,然后FOV map的两个channel使用鱼眼投影模型计算(支持六种模型),最后两层是归一化的坐标,与cam-convs一致,相当于学习到了鱼眼模型的畸变参数和光心偏移。通过新的camera geometry tensor,建立了支持多鱼眼相机同时输入的单模型训练和推理框架。
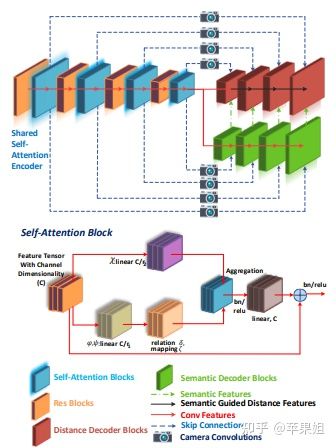
另外,本文还采用了前文所提到的robust loss(鲁棒损失)、语义信息引导的动态目标mask等,并对每个trick进行了ablation study,结果显示使用patch-wise self-attention架构和全部trick的网络表现最好。而且同时使用12个不同参数鱼眼相机的结果比单个相机的结果也要好。只是目前还没有同时兼容鱼眼和针孔相机的尝试。
六、环视鱼眼多任务王炸:OmniDet(2021)
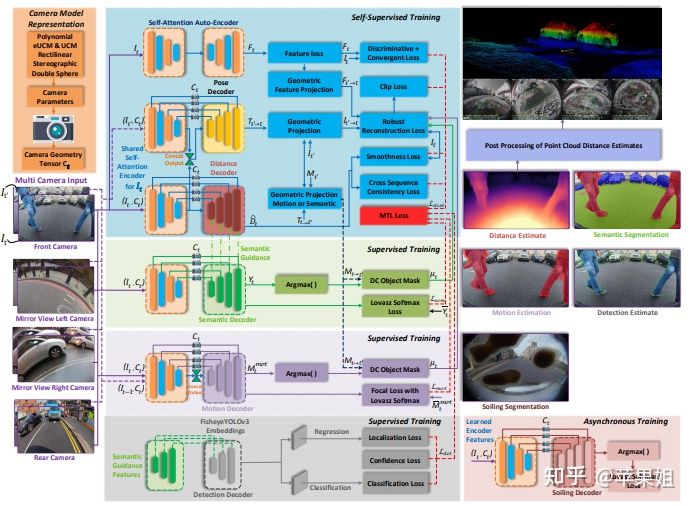
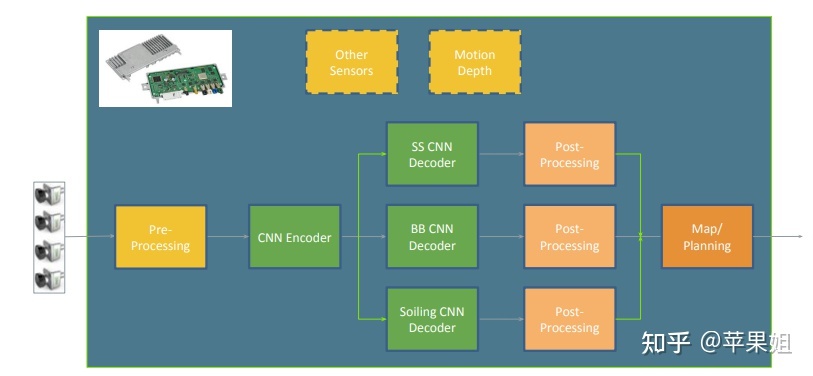
关于多任务的探索,Valeo其实早在2019年的FisheyeMultiNet就开始了,论文如下:
只是这篇文章仅有三个任务:目标检测、语义分割和污染检测,三个任务公用CNN encoder,各自独立的decoder,四路相机独立运行,结构如下:
而我们最后要介绍的OmniDet是在SVDistNet12个鱼眼相机,深度估计和语义分割基线的的基础上,扩展到六种任务,新增了视觉里程计(visual odometry),运动分割(motion segmentation),目标检测(object detection),污染检测(soiling detection)四种任务,并在多个数据集上取得了优异的成绩。
一、对于和SVDistNet相似的深度估计-语义分割任务,大部分沿用之前的架构,只是在损失函数设计上有了进一步地扩充,即在图像重构过程中加入了feature-metric loss,这个loss来自于以下论文:
[20] Feature-metric loss for self-supervised learning of depth and egomotion(ECCV 2020)
这篇文章在我之前的博客中曾非常详细的介绍过,即在monodepth2的基础上加入了特征级的重构损失,和单帧重构的网络auto-encoder。具体内容可参见以下博客:
苹果姐:单目深度估计自监督模型Featdepth解读(上)——论文理解和核心源码分析3 赞同 · 0 评论文章3 赞同 · 0 评论文章3 赞同 · 0 评论文章正在上传…重新上传取消
所以深度估计部分的总loss变成以下形式:
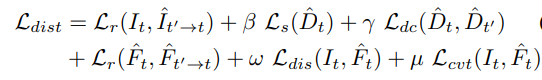
二、在多任务协同方面,作者设计了一种新的VarNorm用来平衡多个任务的loss权重,每个任务的loss权重根据各自的方差和epoch个数进行自适应调整,公式如下:
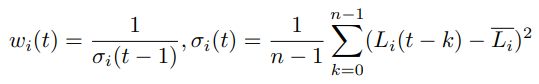
作者还对比了其他的多任务协同方法如Kendall,DWA,GradNorm, DTP, geometric loss等,实验结果显示VarNorm得到的结果是最优的。
三、在其他任务方面,例如目标检测任务,由于鱼眼图像的畸变非常严重,矩形框已经不再适合作为目标的包络,而应该使用多边形polygon,作者对YOLOv3的输出做了一个polygon的改造。在soiling detection任务中,由于数据集是独立的,无法与其他五个任务同时训练,所以训练时冻结了encoder,单独对head进行了训练。
四、证明了基于SAN(self-attention network)的encoder和基于PAC(pixel-adaptive convolution)的decoder在多特征融合、多任务协同方面进一步发挥了作用。
五、再次证明了SynDistNet中首次提出的Camera Geometry Tensor和语义信息引导的动态目标MASK,以及从fisheyedistancenet沿用至今的cross-sequence distance consistency loss对结果作用显著。
至此,我们对Valeo在鱼眼-环视-多任务方面的一系列文章做了比较全面的总结,由于知识点太多,难以一一详尽表述,欢迎留言交流。后续将对丰田研究院的系列文章再做一个类似的介绍,欢迎关注。
最后膜拜一下Varun Ravi Kumar大神,以上六篇大作的第一作者















 2749
2749











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









