






视频内容
前言
这是AlphaFold2了,因为之前有一篇了,不要搞错
早在论文发表的5个月前,就已经写了博客,虽然文章还没写
同一天,2021 July 15,来自另一个团队也宣布了自己的工作RoseTTAFold,也是用深度神经网络来进行蛋白质结构的预测,将发表在科学杂志上面,同样上了封面!
所以基本上可以认为两个团队同时发表了文章,我们知道,在科学领域,谁先出来谁后出来当然是不一样的,先出来的人拿到了最大的荣耀。所以科学家也会不日不夜地第一时间将自己的工作做出来,在这一点上科学领域卷得不比人工智能领域差!
两篇工作同一天发表出来,我们多少见证了历史。
作者和大纲
长达50页的补充材料

摘要
- 蛋白质的结构预测:给你一串氨基酸的序列,然后预测它的3D结构长什么样子
- 接下来讲预测困难:已经知道10w左右的蛋白质结构,然后已知的有10亿种,所以目前了解的还是很少
- AlphaFold2预测精度在原子量级
- 这是一类应用型文章,主要目的是用机器学习这个工具解决这个领域重要的问题,你关心的是两点:1.什么样的问题,这个问题重不重要,对这个领域来说有什么意义;2.结果好坏,是不是解决了这个问题。
- 具体来说你用的模型好坏并不重要
- 上nature的两个办法:
-
- 找一个新的问题,别人都没有用机器学习来做过,你把它变成一个机器学习的问题,收集数据,可能用简单的模型就行了
-
- 数据已经摆在那里了,而且举办过竞赛了,大家都做了很多办法。这时候你需要用很不一样,很强大的算法创新才行了
- AlphaFold2就是这么出来的
导论
摘要的扩充
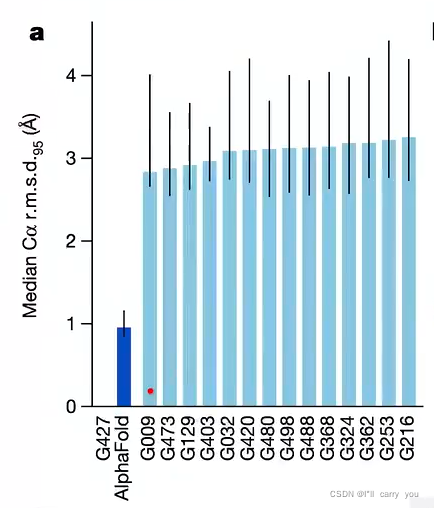
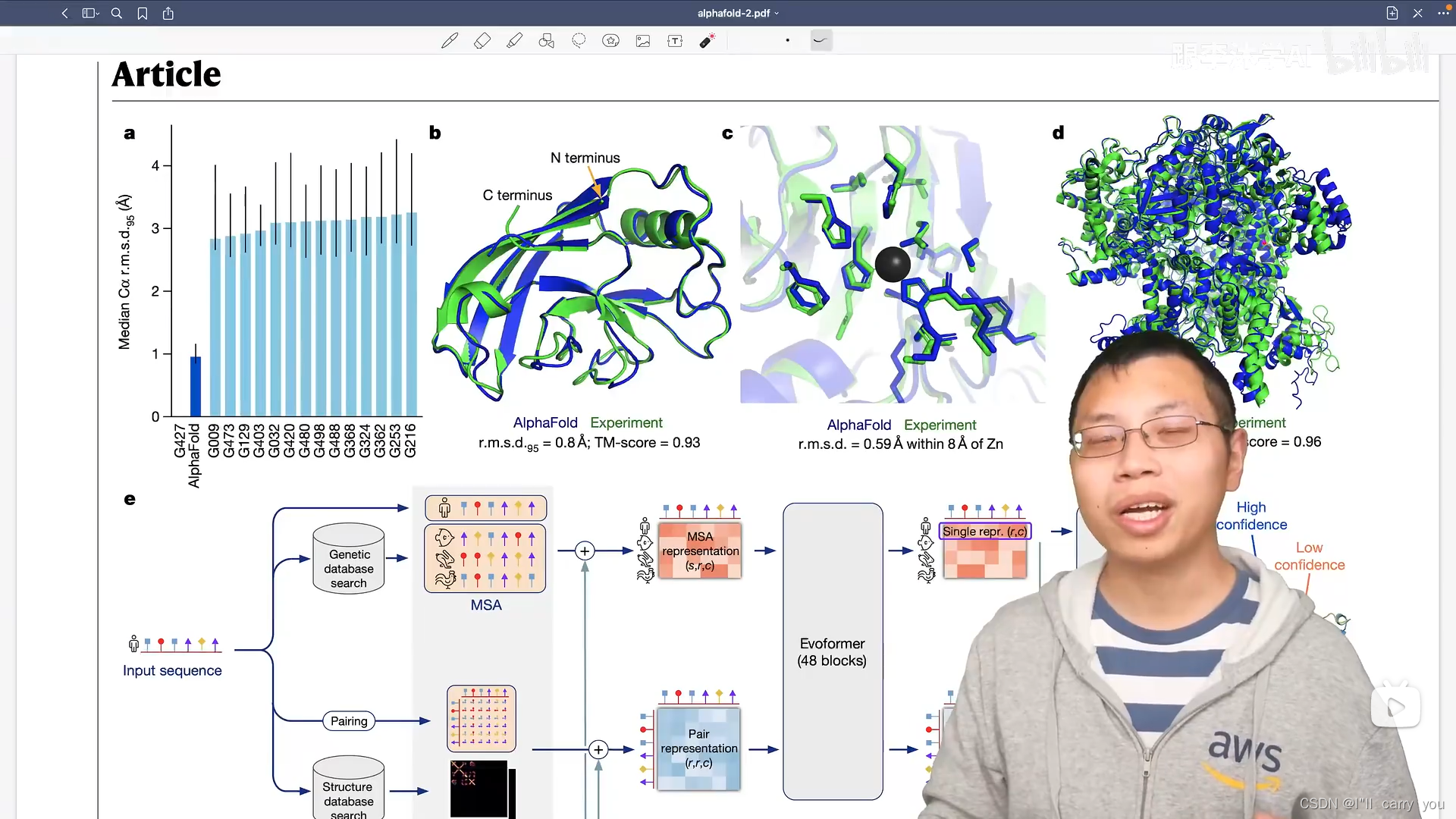
讲了一下问题,讲了实验结果具体数字,没有讲太多的算法,所以我们看一下图就行了
第一张图讲实验结果
这里学习的点是:你怎样表述你的结果?(论文写作)
表述1:我比别人的结果好3倍,极大改善别人结果(×)
表述2:达到原子精度(√)
原因:表述是绝对值,是我们理解的常用概念。你说我的图片识别比别人好10%,不重要,我说我的图片识别比人类识别精度还要高,那听上去就有意思了。把你的结果换算成别人能理解的概念,而不是纯数字的概念。
模型(我们关心重点)
正文太短,需要补充材料

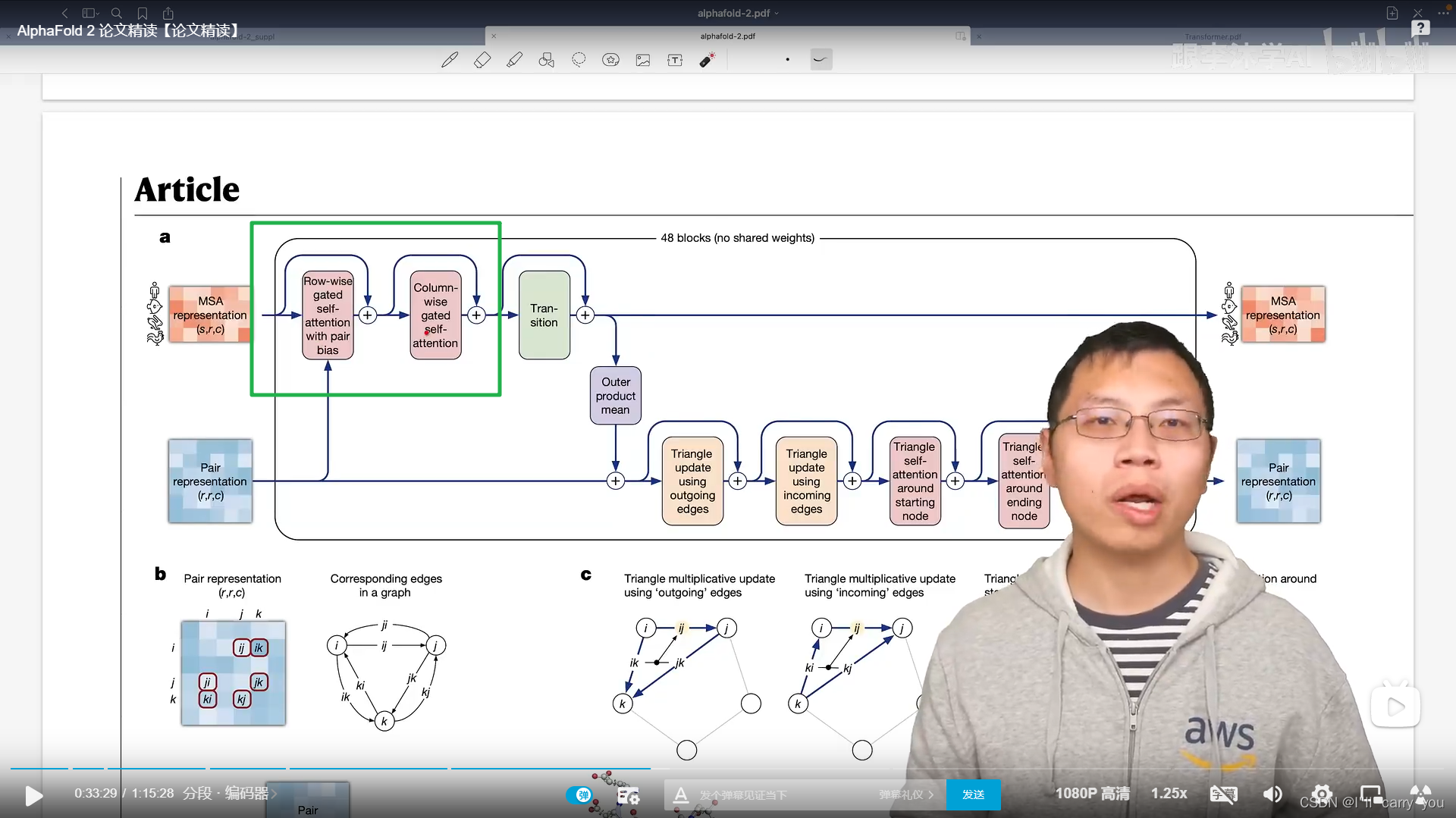
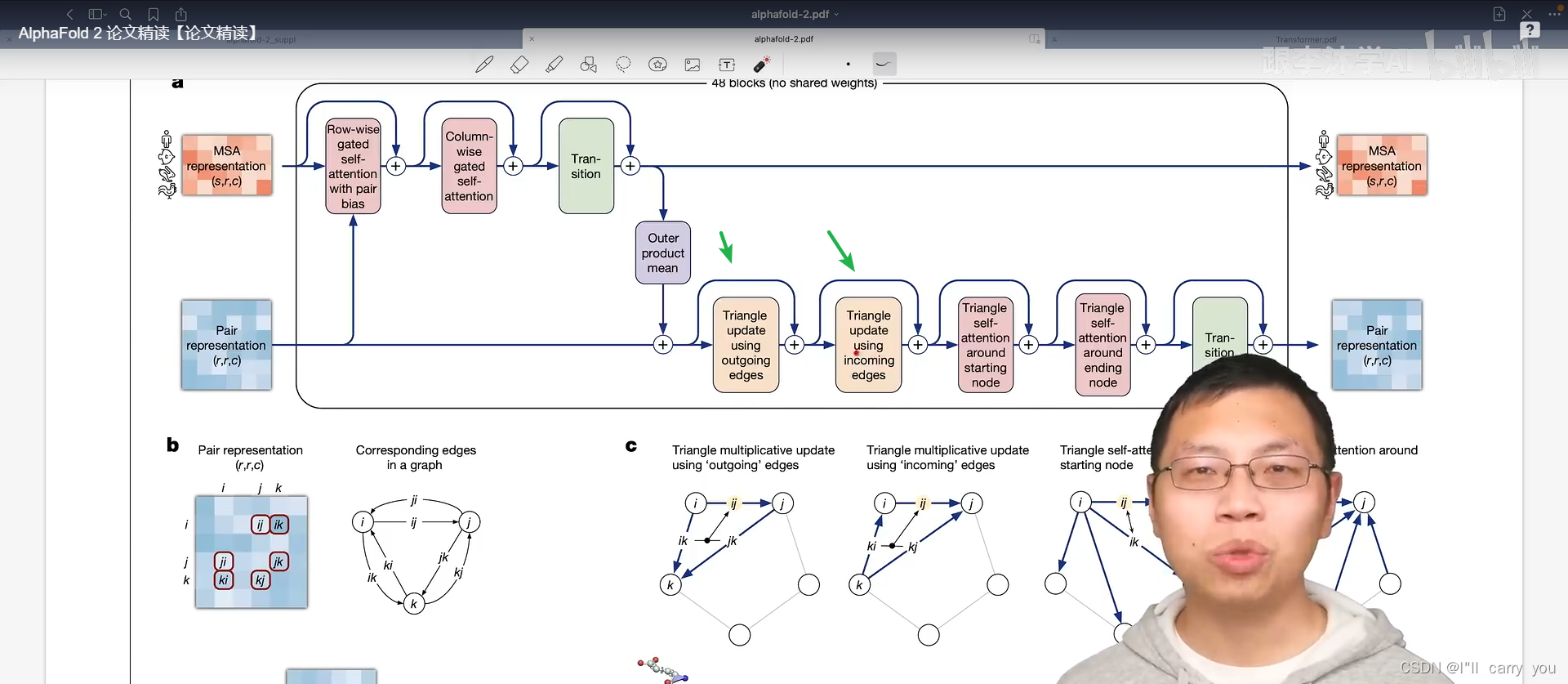
模型图
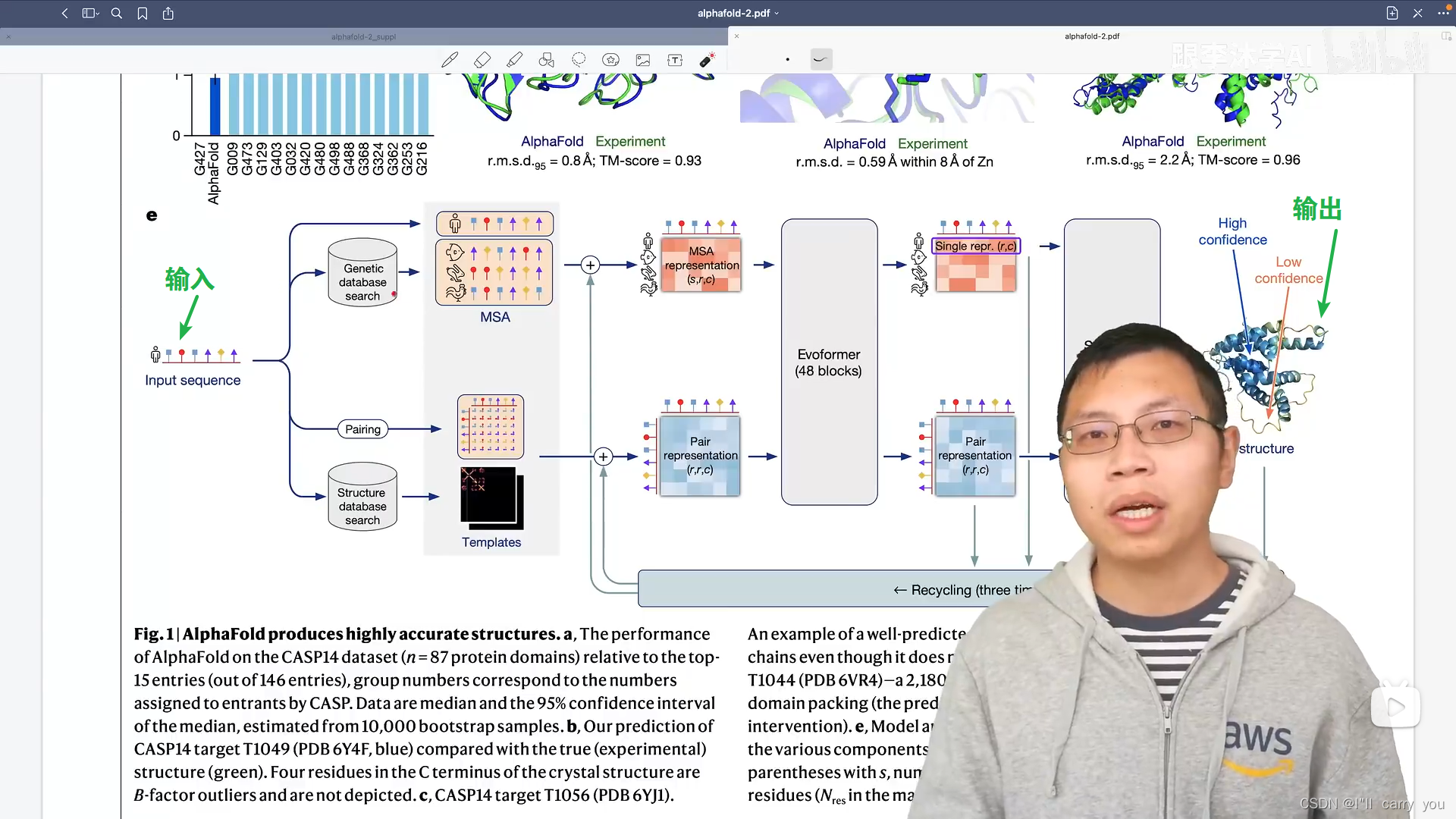
大概分为3部分
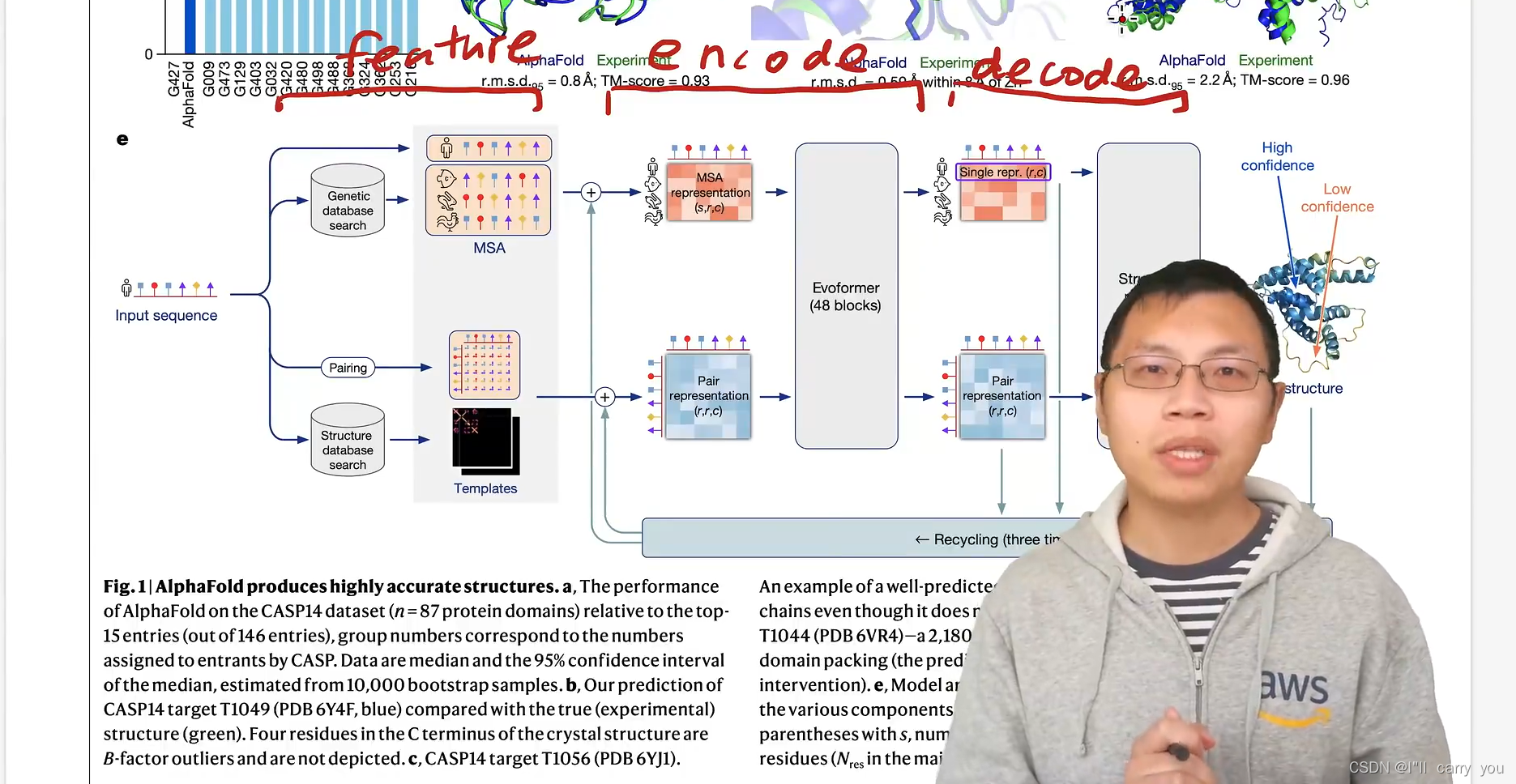

编码器
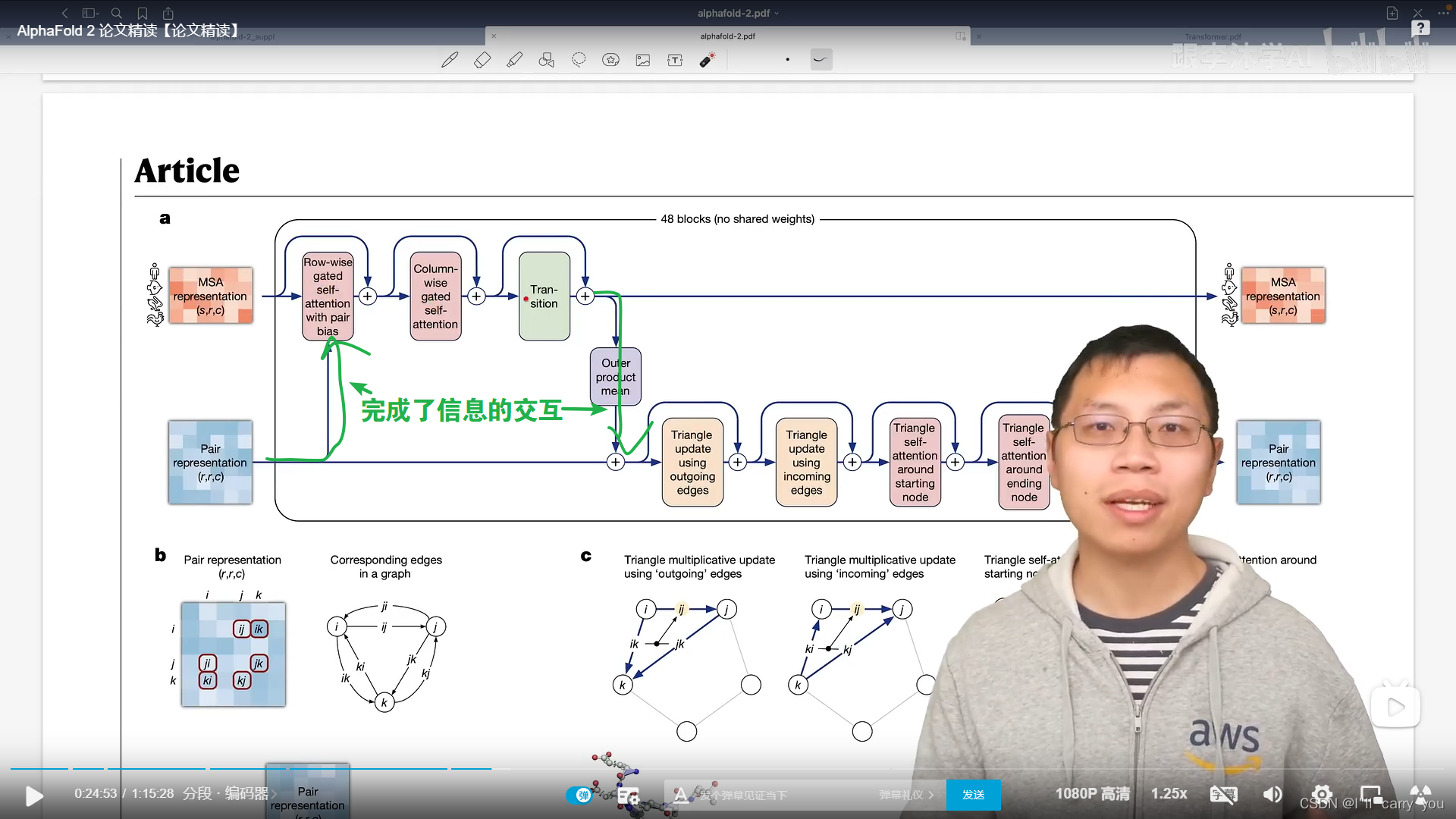
每个模块细节在补充材料里
既对每一行信息建模,也对每一列信息建模
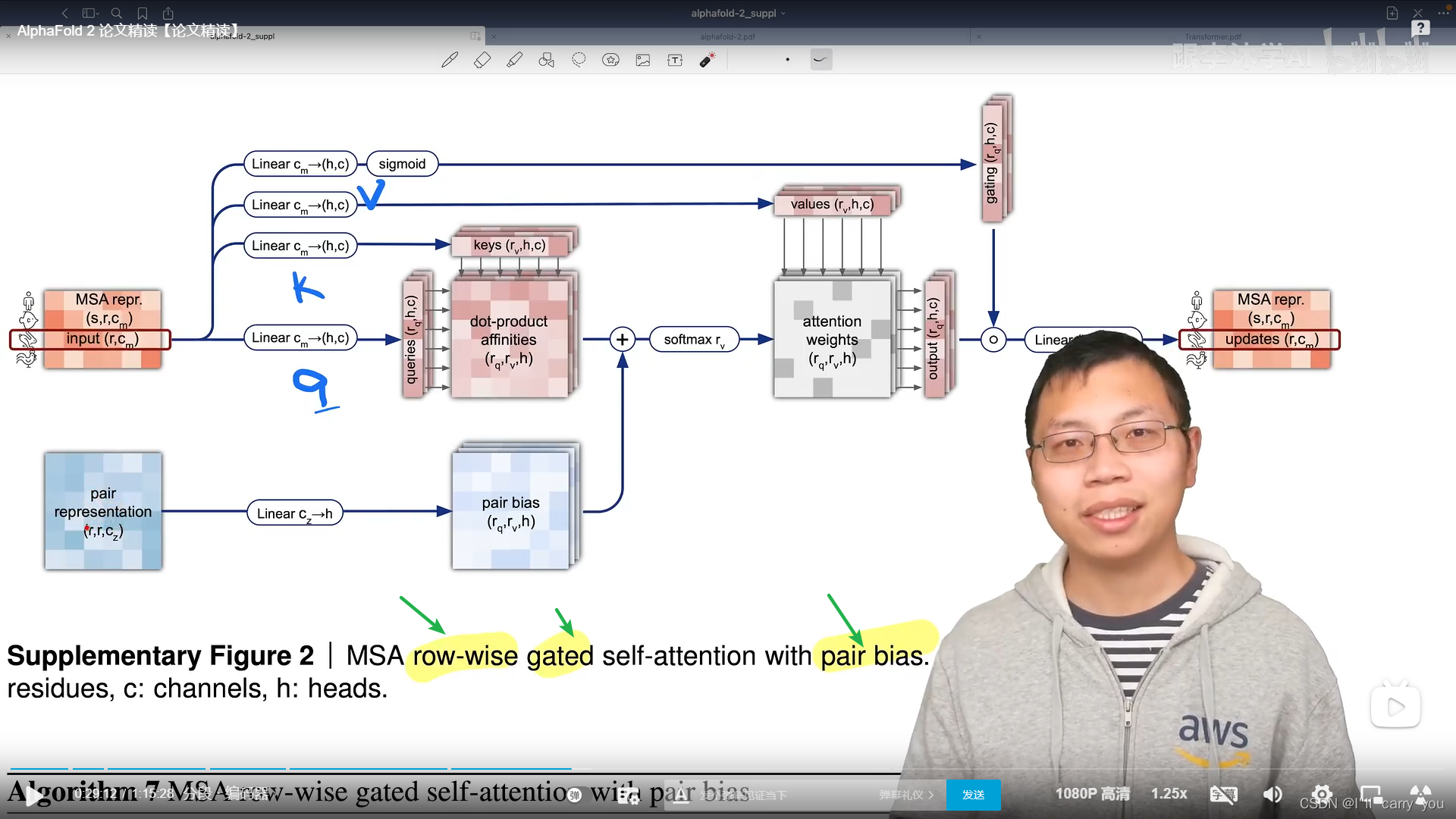
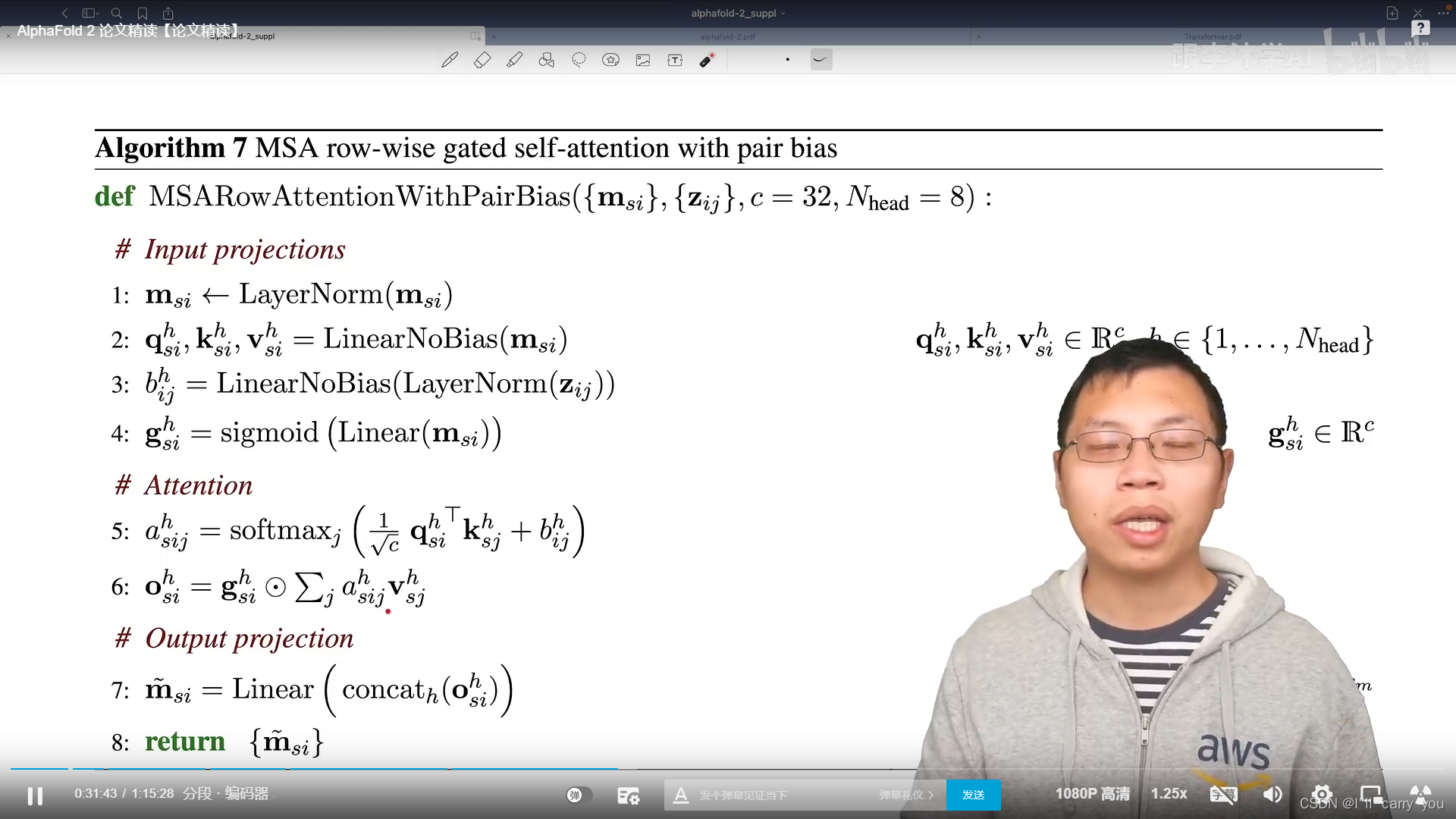
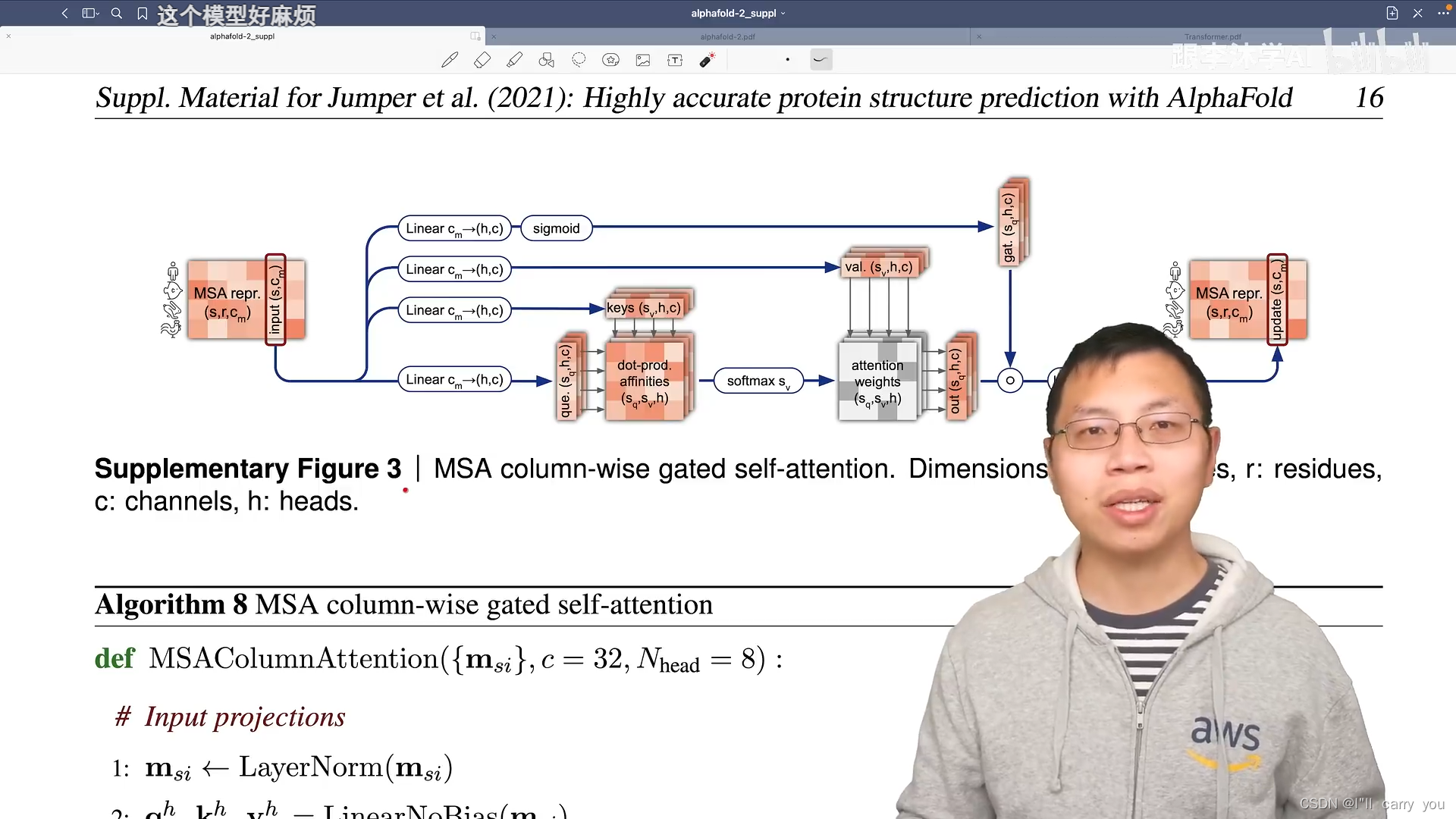
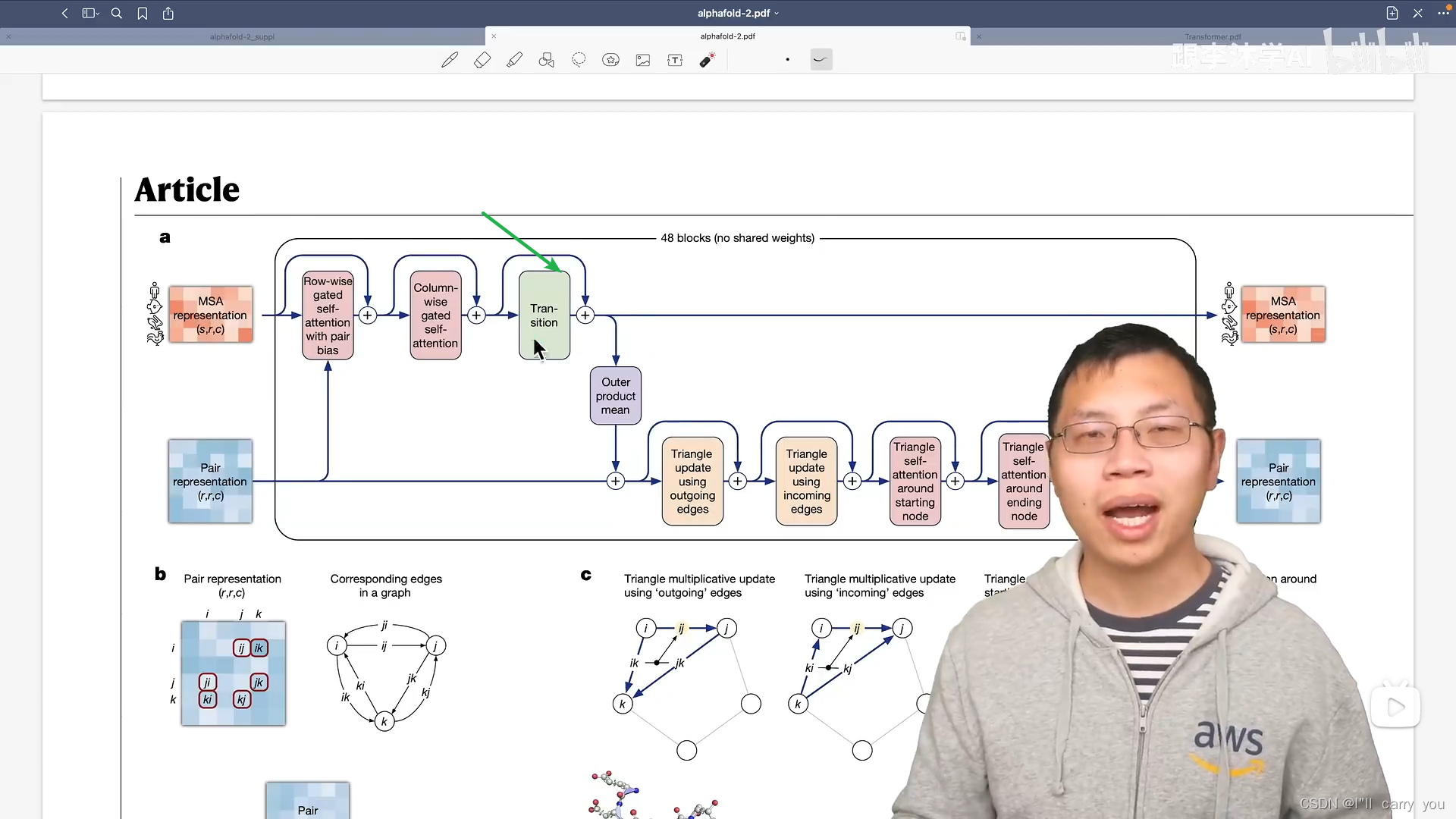
我们知道具体在Transfomer里面,具体的信息提取还是靠MLP
投影到4倍的空间,再投影回去

紫色模块
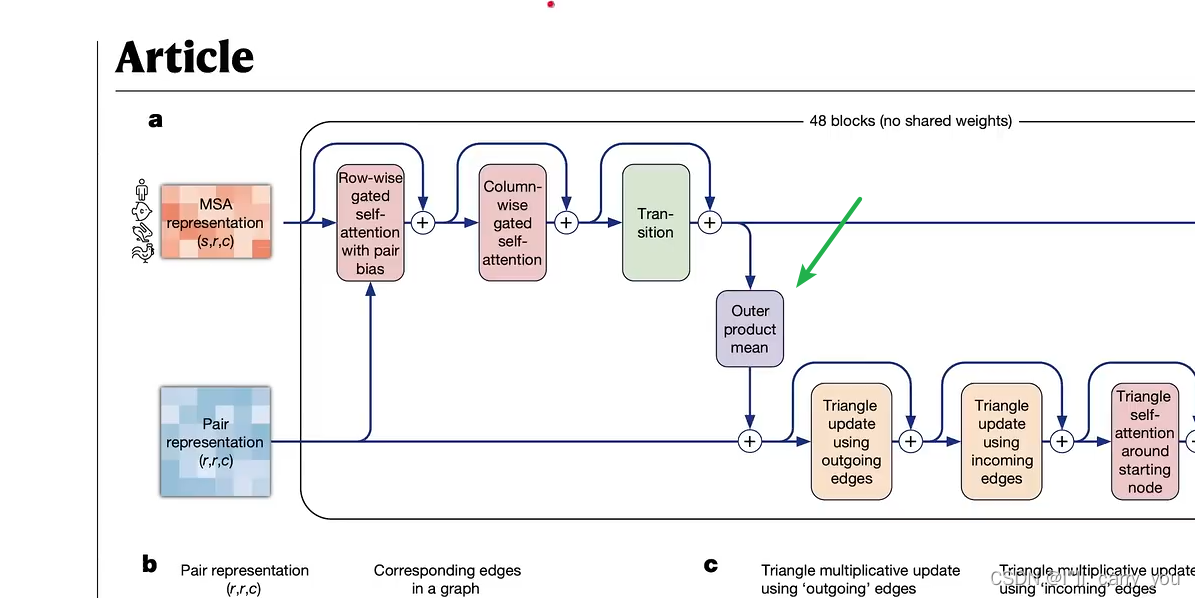
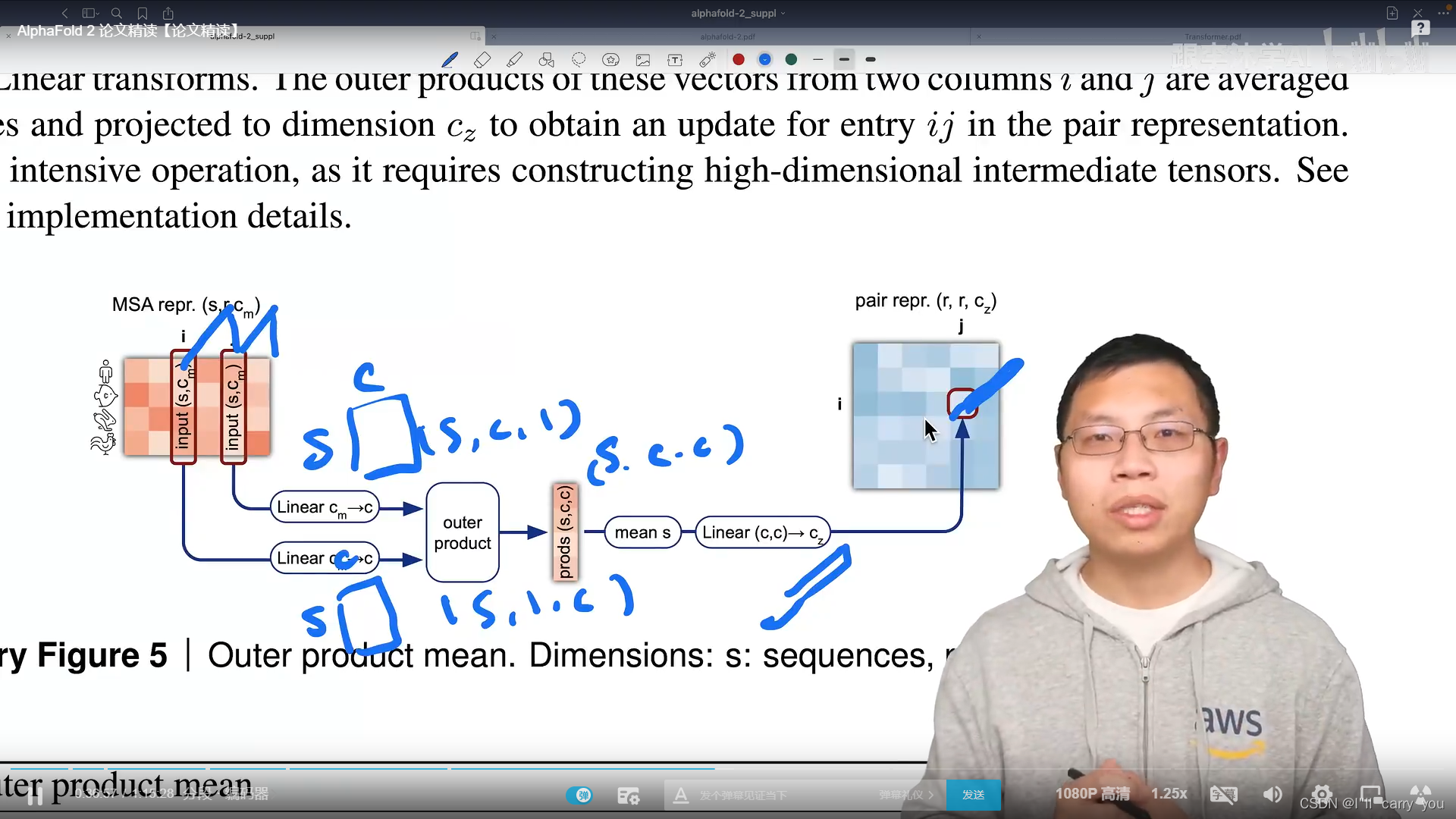
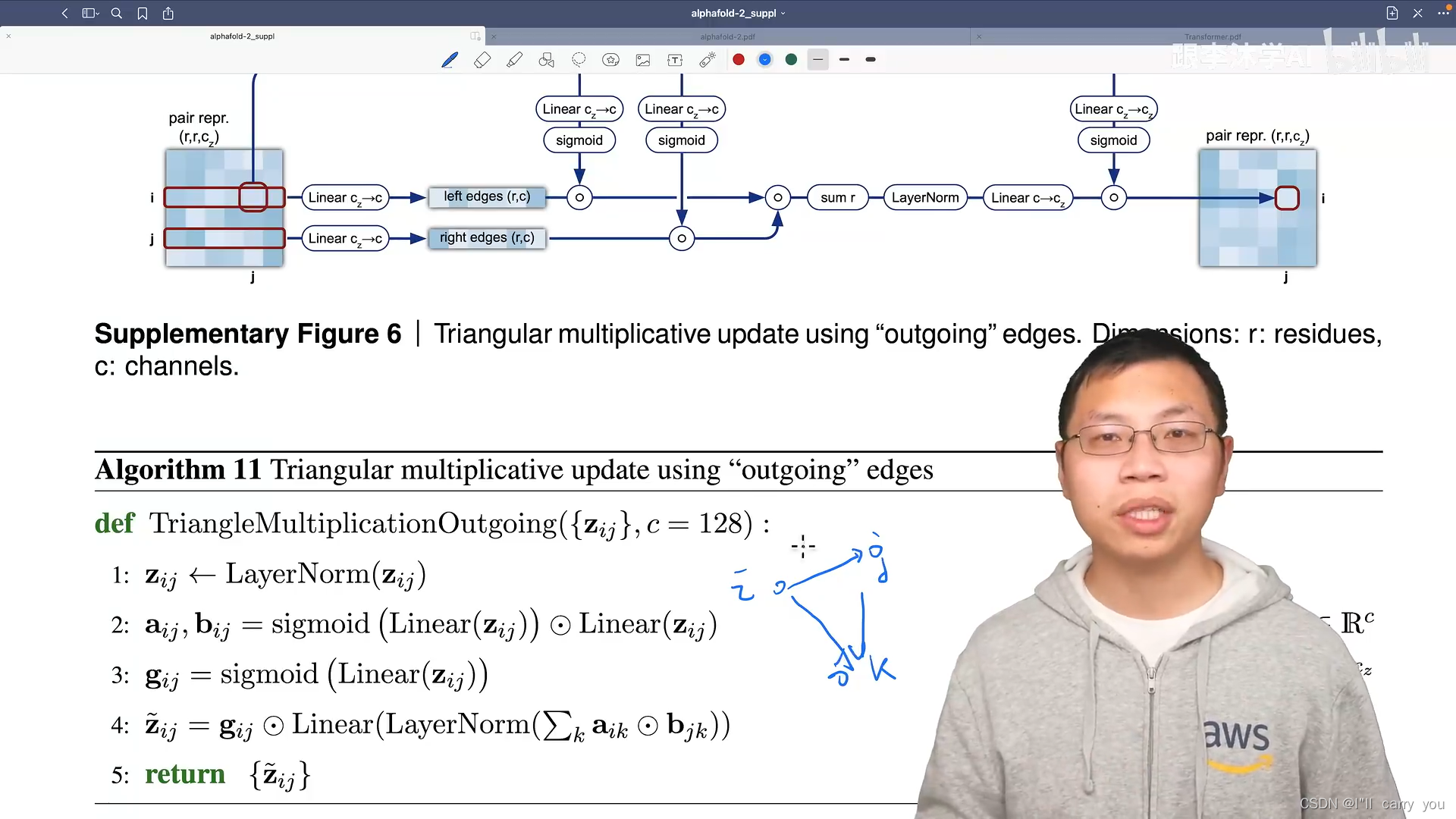
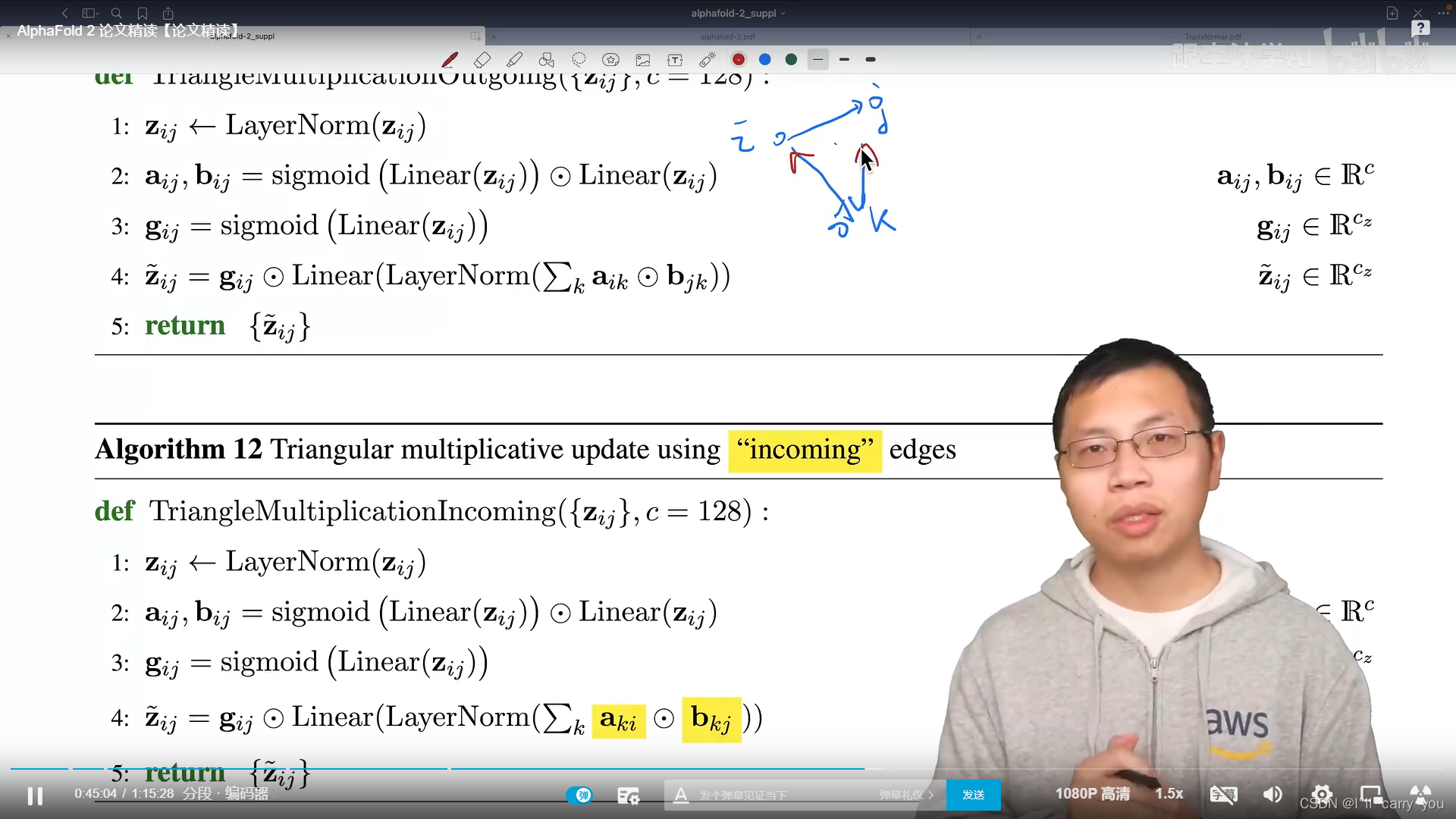
这四个模块对氨基酸对之间的关系建模,先看红色块

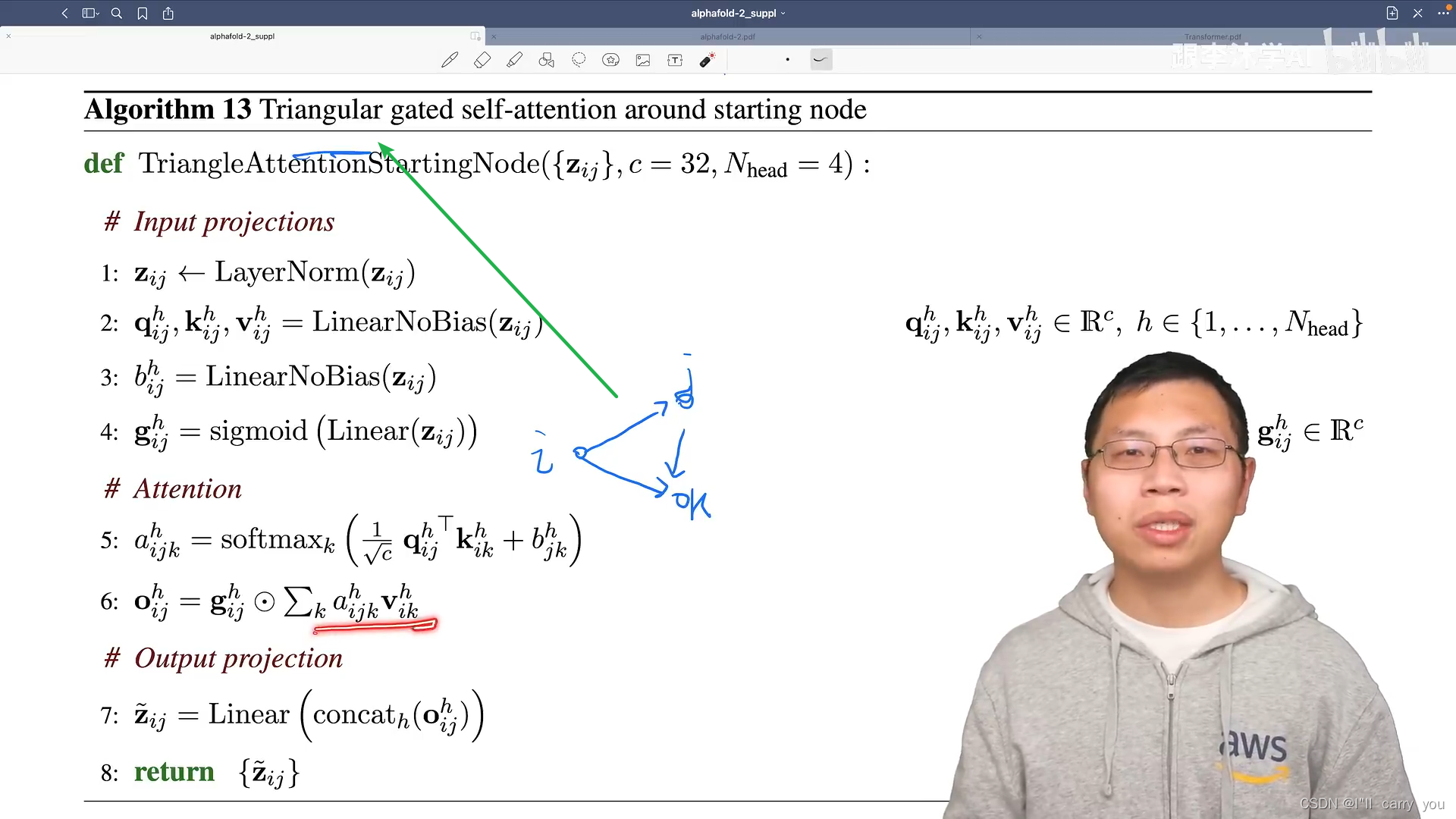
接下来看黄色的模块
细节看是复杂的,从整体看符合Transformer编码器块架构
通过自注意力模块来对每个元素之间的关系建模,然后通过一个全连接层进行信息的转换
不同的是,输入里面既有行的信息,又有列的信息,所以这些模块都是成对成对出现的(分别处理行和列),然后我们有两个输入,分别表示氨基酸在一个序列中的信息和氨基酸对之间的信息,需要做一些信息的传递,使得这两块能够做信息的融合,这就是对编码器的讲解。
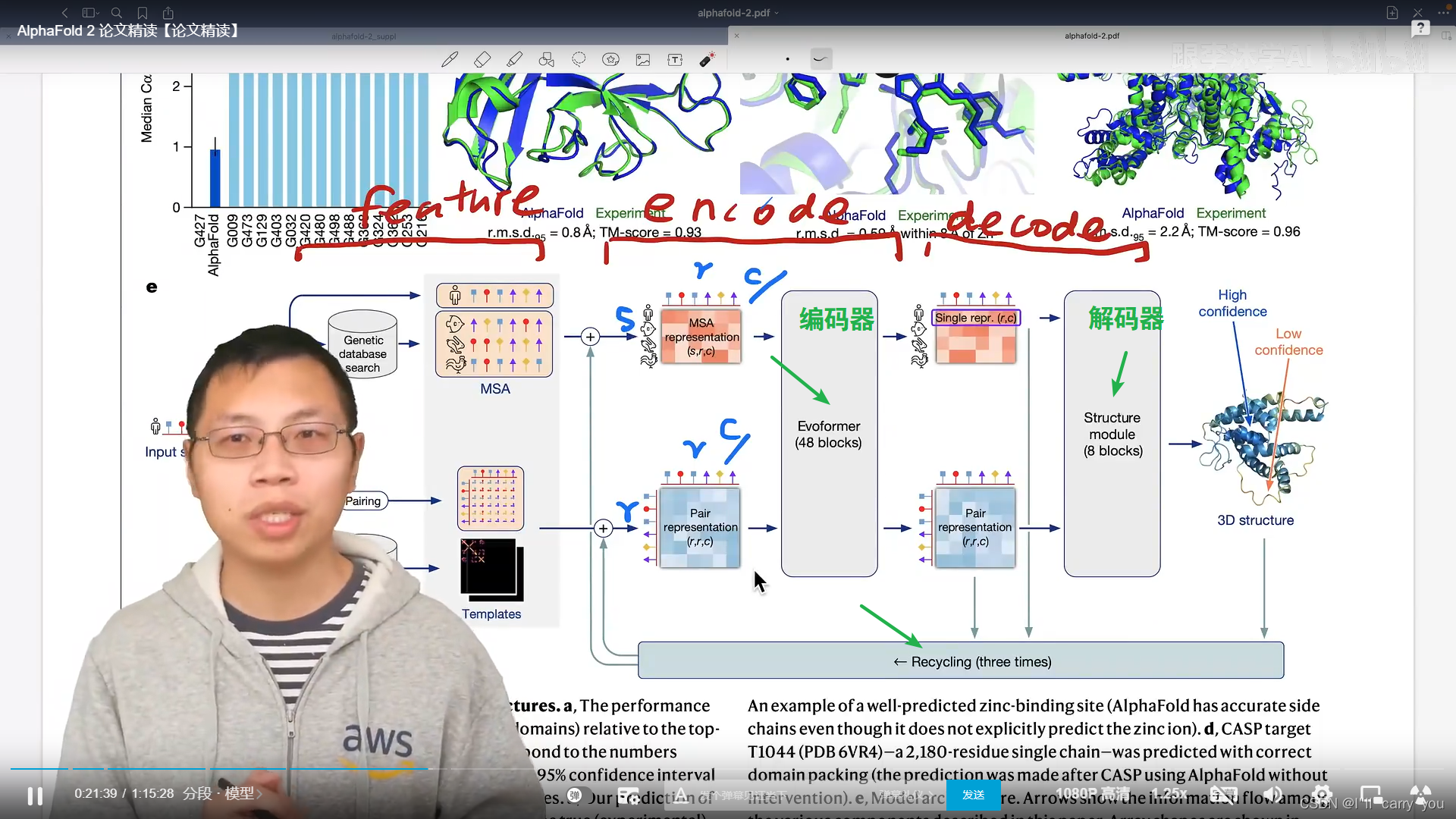
解码器
蛋白质的3D结构
用绝对位置对平移、旋转不友好,这里用相对位置
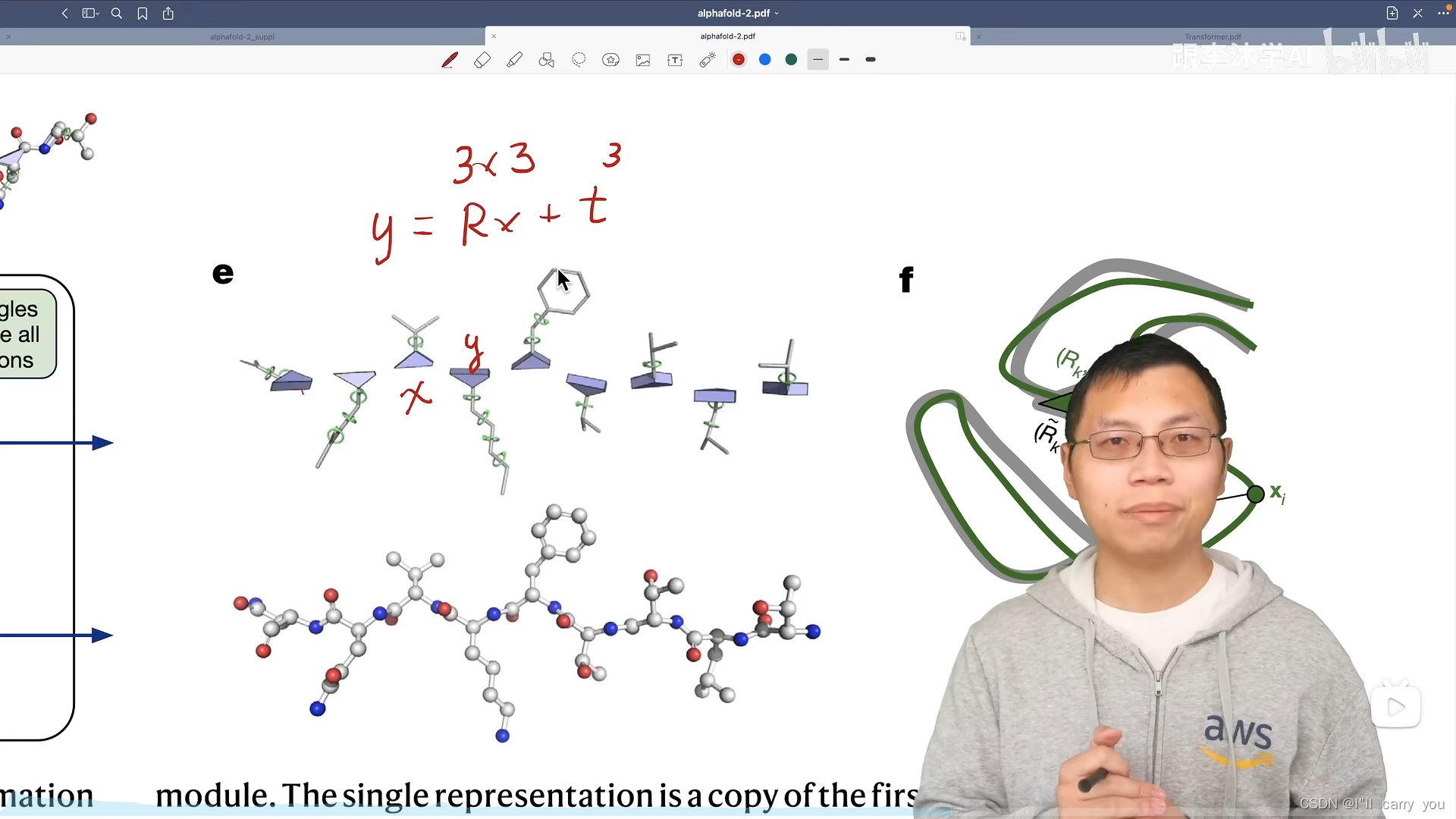
不断调整
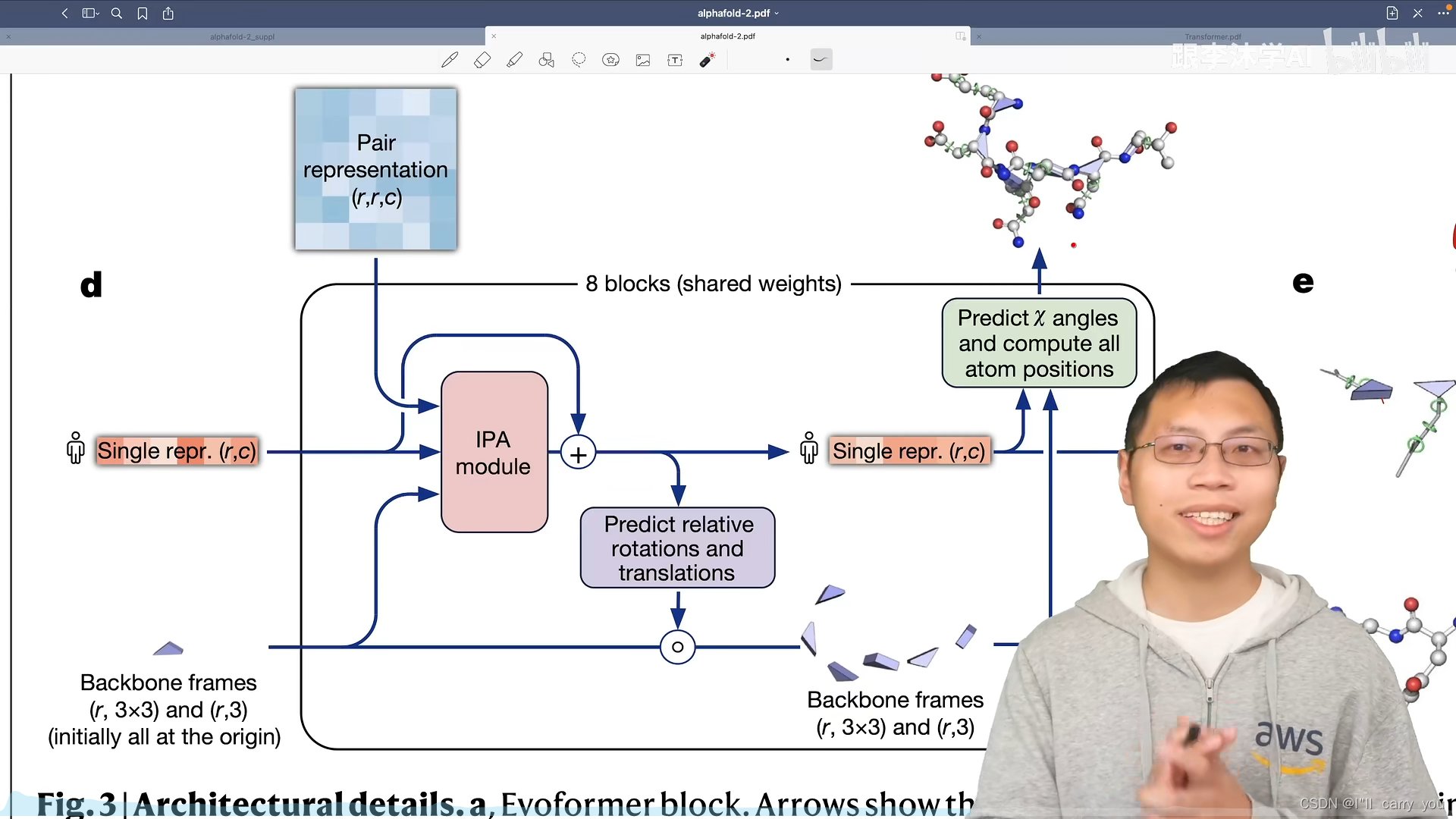
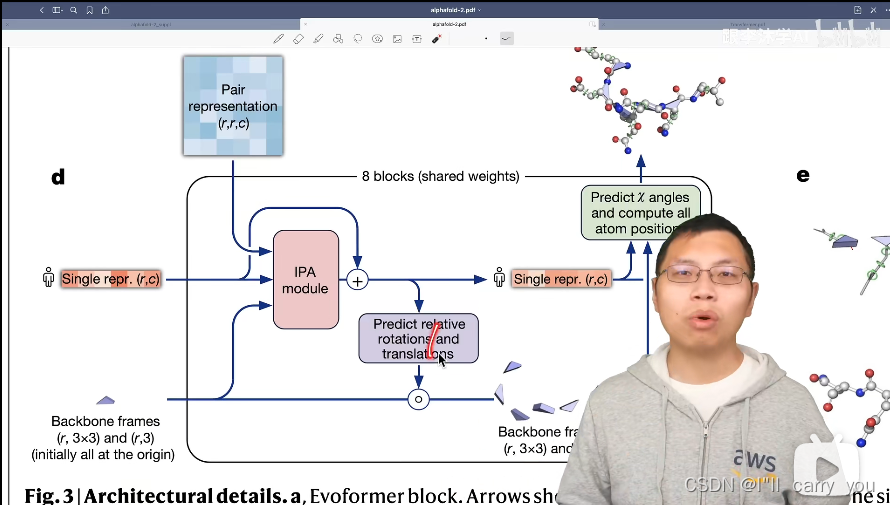
接下来是IPA module

以紫色模块为例,看看预测模块

训练
- 加噪音,先训练,再从从另一个没有标签的数据集上找出置信度高的,重新做成一个数据集
- 类似BERT,随机遮住一些,预测这些被遮住的氨基酸

结果
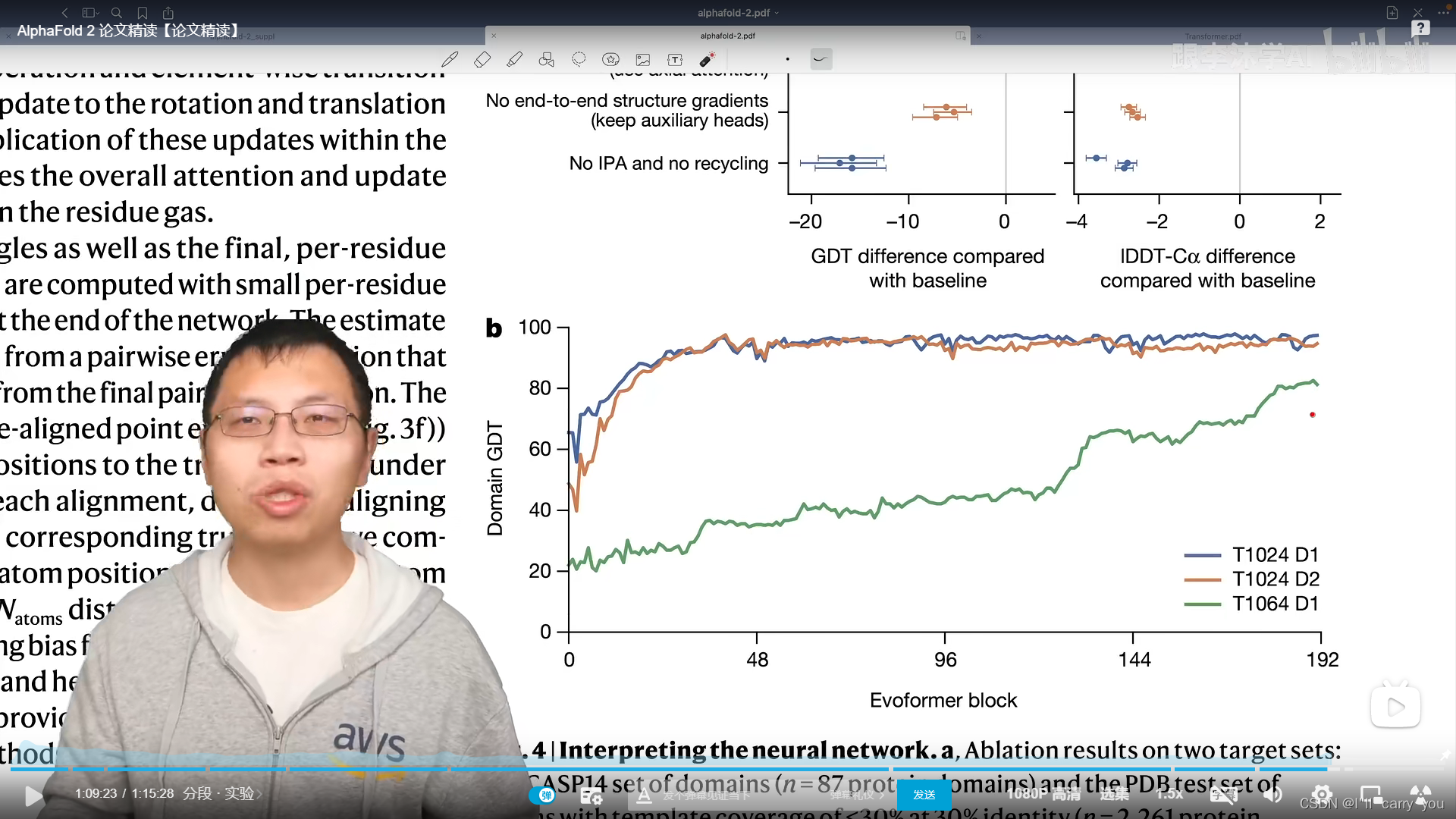
消融实验
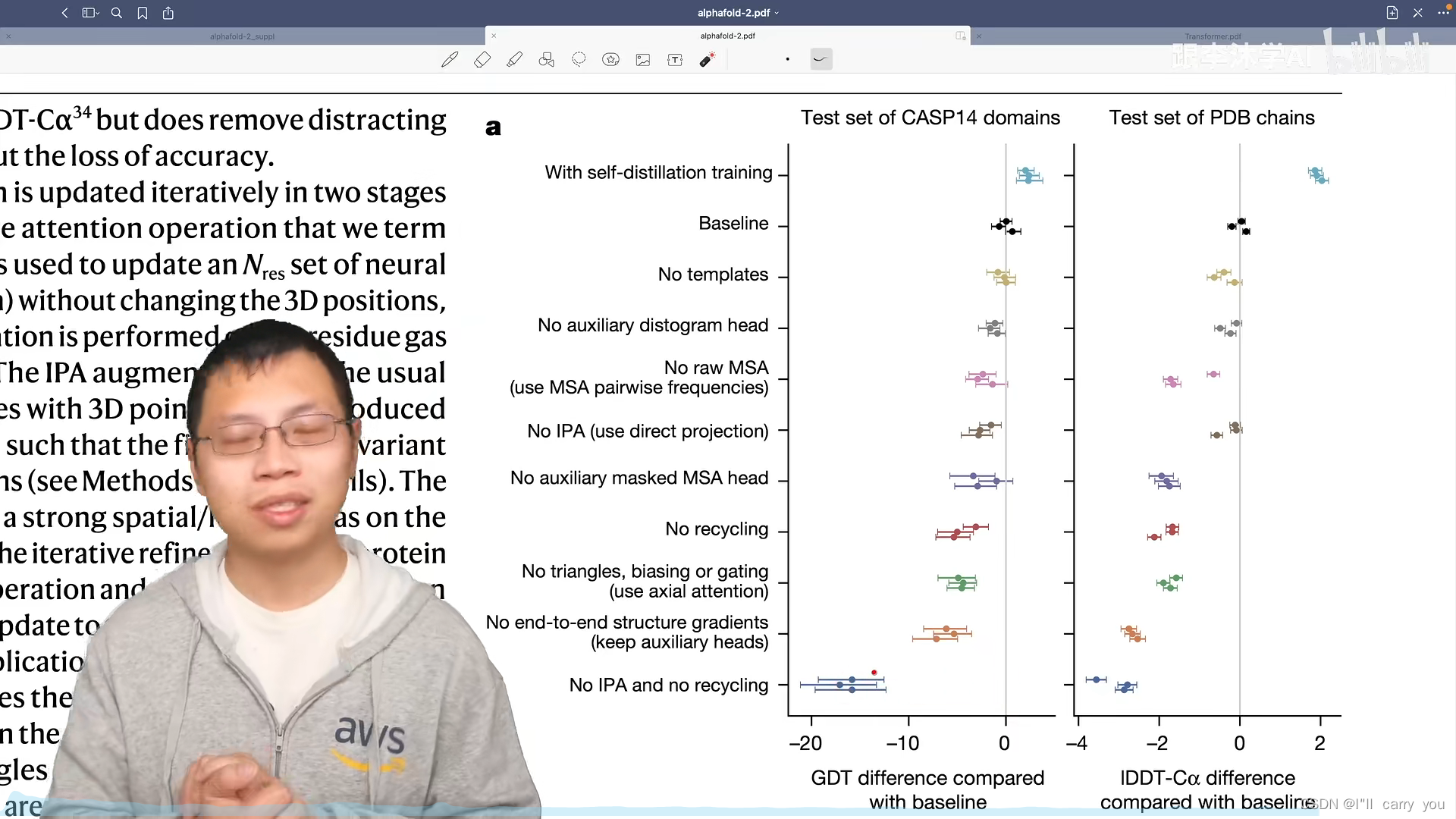
48个模块,4次回收,共计192块。
如果是简单氨基酸预测,差别不对,但如果复杂,192块还有上升趋势
评论
读正文读不到模型细节,需要到补充材料里
从前人工作细节揉在一起,做成一个大的系统,当然自己也提出了很多东西
一般来说,在前人的工作上做1,2,3点改进,然后就拿来写文章了。
读后感,奇思妙想?
-
蛋白质三维结构类似点云? 借鉴方法?
-
细节看是复杂的,从整体看符合Transformer编码器块架构
通过自注意力模块来对每个元素之间的关系建模,然后通过一个全连接层进行信息的转换
不同的是,输入里面既有行的信息,又有列的信息,所以这些模块都是成对成对出现的(分别处理行和列),然后我们有两个输入,分别表示氨基酸在一个序列中的信息和氨基酸对之间的信息,需要做一些信息的传递,使得这两块能够做信息的融合,这就是对编码器的讲解。

















 1523
1523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









