






问题:
在计算线性回归最大似然估计的解的时候,最后的推导结果是
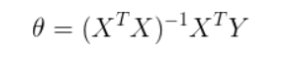
为什么不直接求出θ?而是一步步迭代求出θ?
原因

因此,梯度下降可以节省大量的计算时间。此外,它的完成方式允许一个简单的并行化,即在多个处理器或机器上分配计算。
此外,当您只将一部分数据保留在内存中时,会出现梯度下降的版本,从而降低了对计算机内存的要求。总的来说,对于特大问题,它比线性代数解决方案更有效。
当您有数千个变量(如机器学习)时,随着维度的增加,这变得更加重要。

问题:
在计算线性回归最大似然估计的解的时候,最后的推导结果是
为什么不直接求出θ?而是一步步迭代求出θ?
原因
因此,梯度下降可以节省大量的计算时间。此外,它的完成方式允许一个简单的并行化,即在多个处理器或机器上分配计算。
此外,当您只将一部分数据保留在内存中时,会出现梯度下降的版本,从而降低了对计算机内存的要求。总的来说,对于特大问题,它比线性代数解决方案更有效。
当您有数千个变量(如机器学习)时,随着维度的增加,这变得更加重要。
 1305
975
1305
975











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























