







GMM高斯混合模型
一、GMM简介
GMM 全称是高斯混合模型,顾名思义,其本质就是将n个高斯模型混合叠加在一起,主要用处是用来作异常检测,聚类等;优点就是可解释性好,在低维数据上有着不错的效果;
常见的异常检测算法,例如:KNN,Kmeans,通常在低维数据上有不错的效果,在高维数据上的表现就不是很好,原因如下:
1、传统方法对高维数据的处理分两步,先将高维数据降维到低维上面,再在低维数据上面作密度估计;
2、但高维数据降维之后,不容易保留足够多的关键信息;而且,降维后和密度估计是独立的,这样很容易陷入局部最优的境地,因为两部是相互独立的,所以不容易知道该保留哪些密度估计所要的关键信息;
二、GMM原理
1、GMM模型
每个 GMM 由 K 个 Gaussian 分布组成,每个 Gaussian 称为一个“Component”,这些 Component 线性加成在一起就组成了 GMM 的概率密度函数:
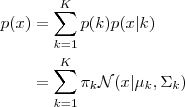
根据如上的公式,如果我们从GMM中取一个点的话,可以分为两步;1:先随机选一个component,component被选中的概率为p;2、选中之后再考虑从这个component中选取一个点,这就是回到gaussian的问题了;
2、求解GMM模型
求解GMM模型,其实本质就是求解每个compoment的概率P,以及gaussian分布中的各类均值Pmiu,和各类协方差Psigma(k)这些参数。
可以这么来思考,假设找到一组参数,它所确定的概率分布生成的这些给定的数据点的概率最大,为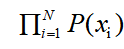 ,这个乘积称作似然函数(Likelihood Function)。通常单个点的概率很小,因此会取其对数,把乘积变为
,这个乘积称作似然函数(Likelihood Function)。通常单个点的概率很小,因此会取其对数,把乘积变为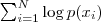 ,接下来只需要将这个函数最大化(通常是求导数,然后令导数为0),即找到这样一组参数值,它让似然函数取得最大值,我们就认为这是最合适的参数,这样就完成了参数估计的过程。
,接下来只需要将这个函数最大化(通常是求导数,然后令导数为0),即找到这样一组参数值,它让似然函数取得最大值,我们就认为这是最合适的参数,这样就完成了参数估计的过程。
GMM的log-likelihood-function:
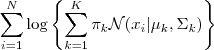
由于在对数函数里又有加和,我们没法直接求导解方程来直接求得最大值,为了解决这个问题我们分两步走,即EM算法;
三、求解过程
(1)估计数据由每个component生成的概率:对于每个数据Xi来说,它是由第k个component生成的概率为:

其中,N(xi | μk,Σk)就是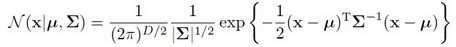
这就是EM算法中的E步,即确定Q函数,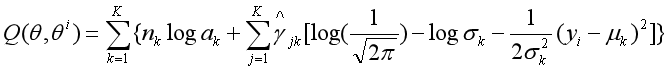
2、确定EM算法中的M步
迭代的M步时求函数Q对theta的极大值,即通过极大似然估计可以通过求到令参数=0得到参数pMiu,pSigma的值,
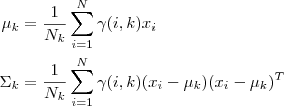
其中,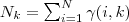
重复以上计算,知道对数似然函数值不再由明显的变化为止
最后的loss函数各参数估计计算如下:
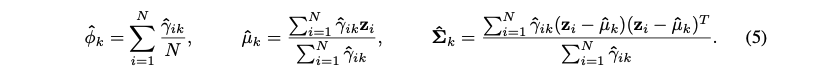
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









