






论文基本信息
- 标题:YOLO9000: Better, Faster, Stronger
- 作者:Joseph Redmon,Ali Farhadi
- 机构:University of Washington
- 来源:CVPR
- 时间:2017
- 论文地址:https://openaccess.thecvf.com/content_cvpr_2017/papers/Redmon_YOLO9000_Better_Faster_CVPR_2017_paper.pdf
论文概要
YOLIO v2是对YOLOv1的改进版本,作者依然后Joseph Redmon。这是发表在CVPR2017上的一篇文章,引用量9000+。是目标检测领域的一篇重要的文章。是后面YOLO v3、v4、v5的基础。
解决问题
- 提出了一系列的措施,解决YOLO v1的一些缺陷。
- 数据集的标注是很贵的,计算机是觉得研究又需要大量的标注数据。为了缓解这个问题,作者提出了一种联合训练的思路。
YOLO v1的缺陷
- 准确性较差,mAP较其他two-stage的检测算法来说比较低。
- 定位性能比较差
- recall 比较低
- 检测小目标和密集目标的能力比较差。
YOLO V2对v1存在的缺陷进行了改进。
创新点
- 提出了一系列的改进YOLO v1的措施,具体见后文论文细节中的描述。
- YOLO v2算法的无论在精度还是在速度上,都达到了当时较高的水平。
- 提出了一种联合训练机制,将不同的数据集放在一块训练,使得训练出的模型更加鲁棒。为解决数据不足问题提出了一种新的解决思路。
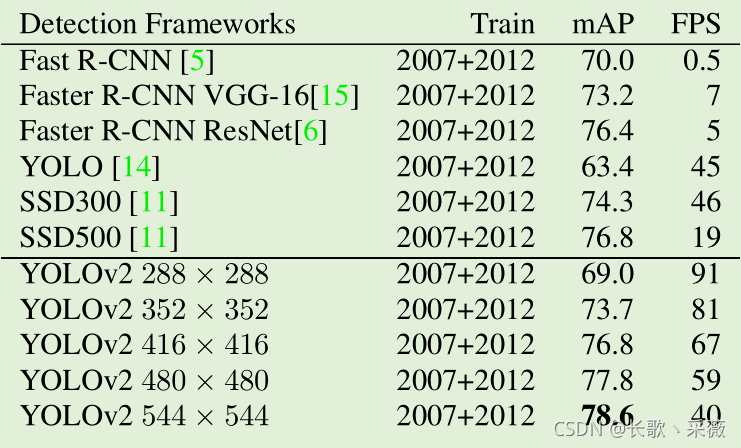
效果
- YOLO v2在VOC数据集上在FPS为67的情况下达到了76.8%的map,在FPS为40的时候,map达到了78.6%,超过了当时的SOTA。
- YOLO 9000能够检测超过9000个不同的类别的物体。
论文细节
Better
作者在YOLO v1的基础上增加了batch normalization、hi-res classifier、convolutional、anchor boxes、new network、dimension priors、location prediction、passthrough、multi-scale、hi-res detector。效果如下表。
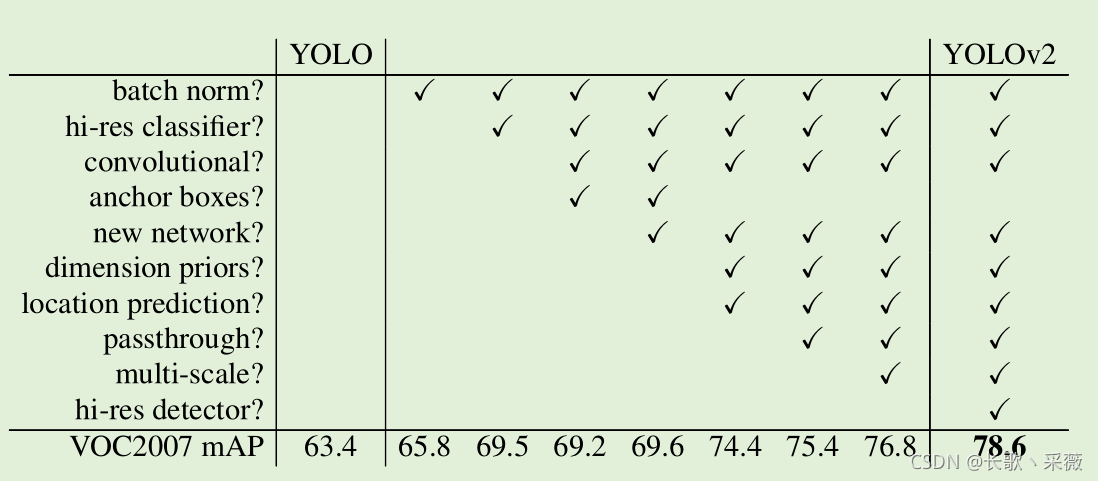
Batch Normalization
在卷积层后加入batch normalization可以避免过拟合,、加快收敛、改善梯度。加入后高了%2的map。
High Resolution Classifier
YOLOv2是要在分类网络上预训练的时候就采用了448448的分辨率(之前是224224),训练10个epochs在ImageNet。然后在检测任务上微调。这样通过高分辨率的分类网络提高了接近4%的map。
Convolutional With Anchor Boxes
- 在YOLO v1中,将图片划分成了7*7的grid cell。由每个grid cell预测两个bbox。此时的bbox是不加限制地,也就会导致模型会不是很稳定。
- 在YOLO v2中,首先是将图片划分成了13*13的grid cell,每个grid cell 有固定数量的anchor,不同的anchor的长宽比和大小是不同的,由每个anchor来预测bbox的偏移量和类别。这样就增加了模型的稳定性。
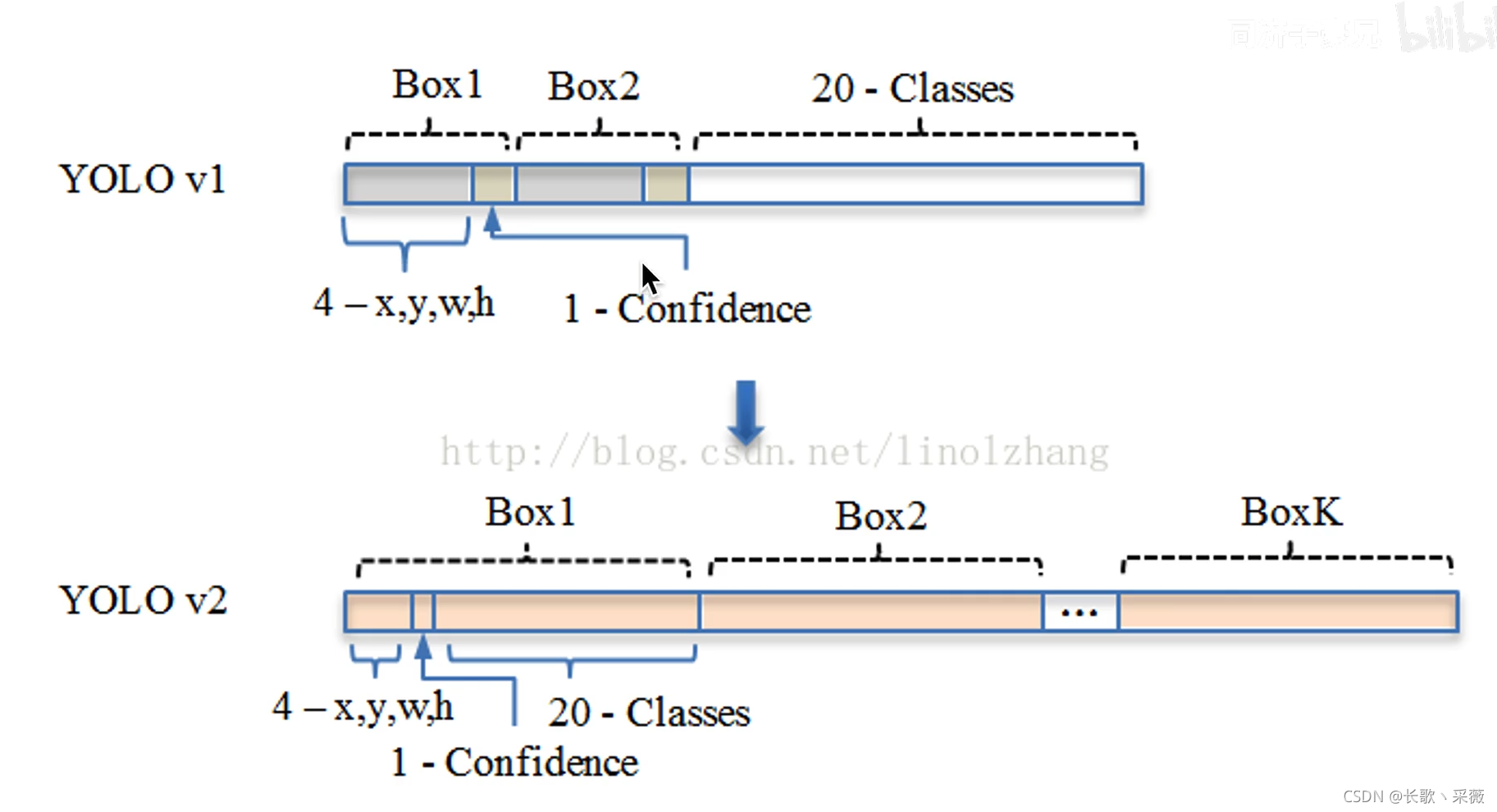
- 如下图所示,YOLO v2最后每个grid cell 会生成一个更大维度的向量,首先是每个anchor对应一个box,k个anchor就对应k个box。类别也是由anchor来确定,也就是每个anchor要产生 4+1+20=25维度的向量,4是位置信息,1是置信度,20是每个类别的置信度。k个anchor就是每个grid cell生成k*25维的信息。
Dimension Clusters
在选择多少个anchor的时候,不同于faster rcnn手动确定anchor的方式,YOLO v2采用了k -mens聚类的方式对VOC数据集和COCO数据集的bbox的大小进行聚类,结果如图
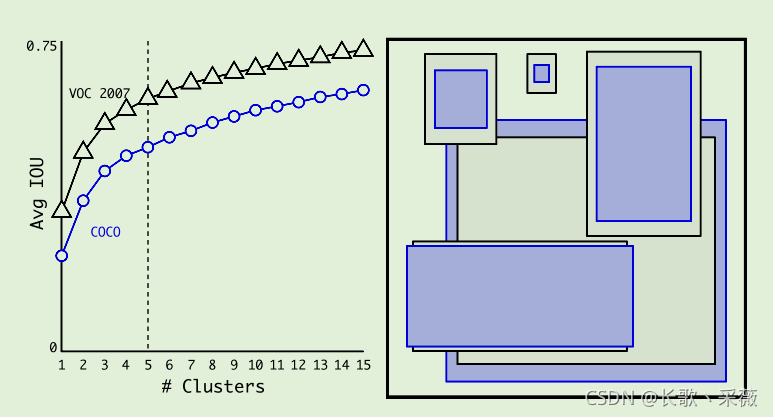
聚类的种类越多肯定IOU 越大,但是模型的复杂度也会加大,最后采用了5种不同大小的anchor如上图中右图所示。采用该种方法来确定anchor的大小比手动确定anchor的大小在性能上有了较大的提升。
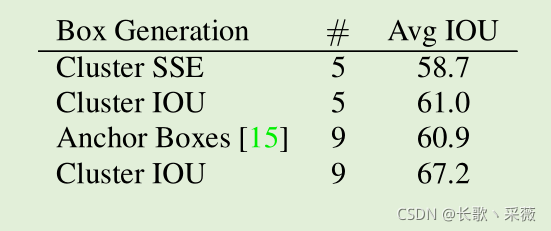
由图中可以看到,采用聚类的方法5类anchor就能达到61.0的IOU,而手动确定要9类才能得到差不多的效果。
Direct location prediction
-
解决问题:
对于每一个anchor,会输出一组(tx,ty,tw,th,to,c1,…c20),只对定位的(tx,ty,tw,th,to)进行讨论。对预测值进行解码回得到框的位置,在通常的region proposal Network中的解码方式如下:其中xa,ya,wa,ha。是anchor的中心位置和高宽。这就会导致一个问题,
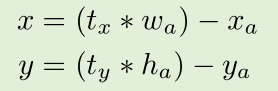
其中xa,ya,wa,ha。是anchor的中心位置和高宽。这就会导致一个问题,就是x,y可以跑到任意位置,就是我们解码出来的预测框的中心点可能到图中的任意一个位置。YOLO v2做了一些限制。使得预测的中心点的位置不会有太大的偏移。 -
具体思路
对预测的值的解码方式进行改变。
其中tx,ty,tw,th是预测的四个值,cx,cy是grid cell左上角的坐标,pw,ph是anchor的宽和高。σ表示sigmod函数,将tx,ty都变到0-1之间,然后交加上cx,cy就将bx,by限制到grid cell里面了。
bx,by,bw,bh是预测框的中心点和w,h。
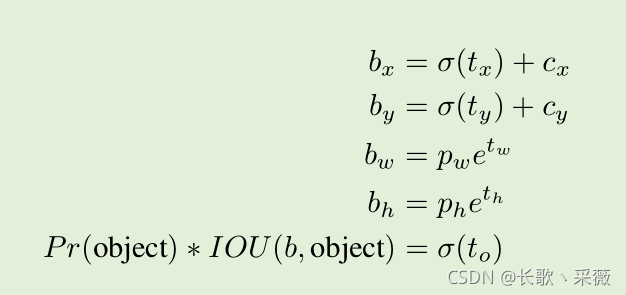
Multi-Scale Training
为了让YOLO模型能够适应不同分辨率的图片,能够让训练出来的模型更加鲁棒。不同于固定输入图片的尺寸,作者在迭代一段时间后更改一下输入图片的尺寸。每10个batch就随机从{320,352,。。。608}中选择一个输入图片的尺寸。
不同尺寸的效果如图,可以看到,图片越小肯定模型越小,FPS越高。图片越大,精度度越高。
Faster
该部分包含很多的训练细节,详情还得看论文内容。
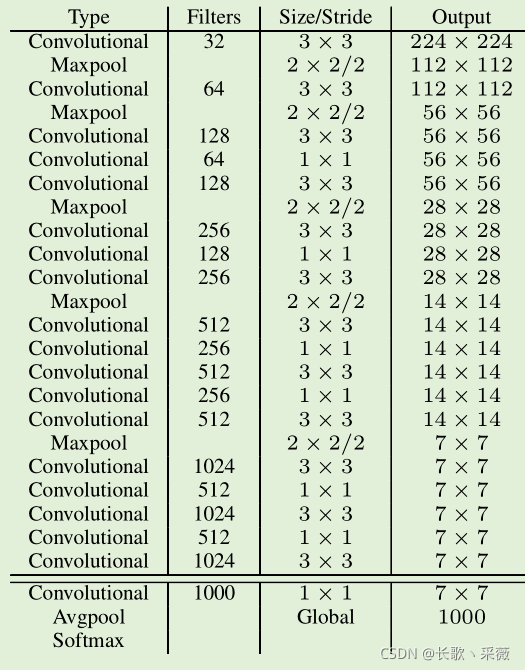
- backbone采用Darknet-19,为什么采用这个骨干网络呢?因为参数量少,推理一张图片的速度更快,darknet的网络架构如图。
- 首先在分类数据集ImageNet上训练,先用小尺寸224224的训练160个epoch,再在大尺寸448448上进行微调。
- 分类数据集上训练好的模型,改变一下最后的输出部分,再在目标检测集上进行训练。
- 加入各种数据增强的方法以增加模型的鲁棒性。
具体训练细节参考论文。
Stronger
该部分主要讲了作者提出了一种基于分类和检测数据集的联合训练机制,大概意思呢就是同时使用分类和检测的数据集来训练模型,当碰到的label是检测的,就执行检测的损失,当碰到的label是分类的,就执行分类的损失函数。
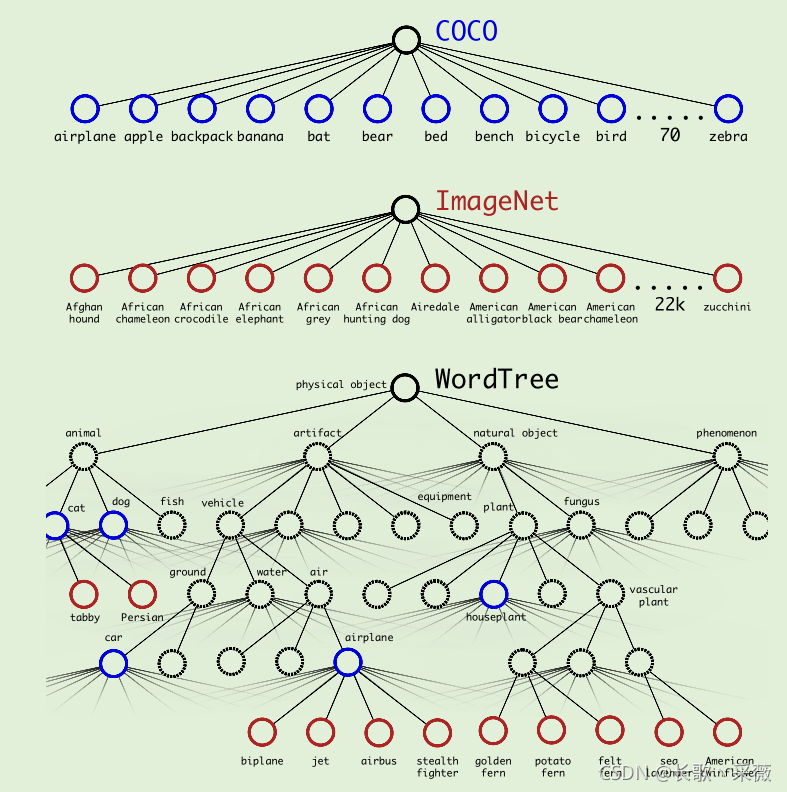
提出了WordNet,是物体类别分类的一棵树。为了解决不同数据集上物体类别不一大小不一,且具有重叠的问题,比如coco中的dog就是狗,但是Image中确具体到了各种类别的狗。
由于这一部分跟检测算法的关系不是很大,我也没仔细阅读。
参考:https://www.bilibili.com/video/BV1Q64y1s74K?p=1
CV领域的小白,若有讲的不对的地方,欢迎批评指正。














 872
872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









