







本文主要介绍CaDDN模型设计,对多视图进行特征空间构造可以参考另外两篇论文的解读:
1.Lift, Splat, Shoot
2.FIERY
3D感知任务是自动驾驶中必不可少的一部分,相较于依赖价格较高的lidar的3D感知,基于摄像机2D图像的3D视觉工作已经有了很多不错的方法,虽然准确度还处于一个较低的水平,但是随着算法的改进,仍有很高的提升空间。
本文中提出的CaDDN模型(Categotical Depth Distribution Network),主要通过为每个像素预测出深度分布,将图像特征(2D特征)投影到3D空间适当的深度区间。然后使用鸟瞰图(BEV)投影和单级检测器产生最终输出检测结果,测试效果提升较为明显。
1.CaDDN模型理解
单目3D检测通常会生成中间的特征表示形式,主要可以划分为以下三类:
- 直接法(Direct Methods): 结合2D图像平面和3D空间的几何关系从图像中估计出3D检测框。直接法的缺点也比较明显,由于检测框直接从2D图像中获取,没有明确的深度信息,因此定位能力相对较差。
- 基于深度的方法(Depth-Based Methods): 利用深度估计网络估计出图像的中每个像素对应的深度图,再将深度图直接作为输入or与原图结合or转换成3D点云数据(伪激光雷达Pseudo-LiDAR)用于3D目标检测任务。该方法的缺点是其深度和目标检测分离训练的结构,导致其可能会丢失一些隐含的信息。
- 基于网格的方法(Grid-Based Methods) : 通过预测出BEV网格表示替代通过深度估计作为3D检测输入的方法,通常转化步骤是通过利用体素网格把体素投影到图像平面上然后采样图像特征将其转换成BEV的形式。这种方法可能会导致大量体素和特征的重叠从而降低检测的准确性。
CaDDN 网络尝试结合以上方法的长处,整体网络同时训练深度预测和3D检测(jointly)以期待其能够解决方法2中的问题,同时利用也将图像平面转换成了BEV的形式来提高检测的准确性。
CaDDN整体网络设计如下:
 从上图可以清晰地看出,网络整体分为四个部分,具体的模块分解如下:
从上图可以清晰地看出,网络整体分为四个部分,具体的模块分解如下:
1.1 视锥特征生成(Frustum feature Network)
 因为是像素级的深度估计,因此对于特征提取网络借用分割网络DeepLabV3的设计,为每个像素预测深度网格分布。
因为是像素级的深度估计,因此对于特征提取网络借用分割网络DeepLabV3的设计,为每个像素预测深度网格分布。
该部分称其为Frustum feature Network,其输入是原始图像
I
∈
R
W
1
×
H
1
×
3
I \in R^{W_1\times H_1\times 3}
I∈RW1×H1×3 输出
G
∈
R
W
F
×
H
F
×
D
×
C
G \in R^{W_F\times H_F\times D \times C}
G∈RWF×HF×D×C 其中 W和H是特征的宽高,D 是用以深度预测的深度块(depth
bins),C 是特征维度。图像特征被用以在每个像素上预测绝对的深度分布
D
∈
R
W
F
×
H
F
×
D
D \in R^{W_F\times H_F\times D}
D∈RWF×HF×D 网络对每个像素预测其落入D个深度块(深度离散化)的概率。
上方的Image Channel Reduce部分网络另一分支用1x1卷积 + BN + ReLU 把特征的维数从256降到了64。
经过这两个分支后,将预测出来的深度块和特征像素做外积得到了带有深度信息的特征图。
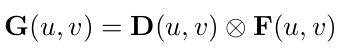
1.1.1 深度离散化方法选择
本文利用Depth bins完成对深度进行网格化的估计,作者给出了深度网格的监督,其实核心是将连续值离散化。本文提到3种常用离散方式:

- 均匀离散(UD):fixed bin size,即等间距离散;
- 间距增加的离散(SID):increasing bin sizes in
log space,即间距按对数值离散; - 线性增加的离散化(LID):linearly increasing bin sizes,即间距线性增加离散。
CaDDN中使用LID进行深度离散化,文中考虑到LID的离散化为不同深度提供了平衡的深度估计。
1.1.2 深度离散化的标签生成
深度离散化后还需要深度分布标签
D
^
\hat{D}
D^,以便监督预测的深度分布。通过将LiDAR点云投影到图像帧中生成深度分布标签,创建稀疏密集的地图。执行深度补全,生成图像中每个像素处的深度值。由于需要每个图像特征像素的深度信息,因此将尺寸为
W
I
×
H
I
W_I × H_I
WI×HI的深度图下采样为图像特征尺寸
W
F
×
H
F
W_F × H_F
WF×HF。使用上面描述的LID离散方法将深度图转换为bin索引,然后转换为one-hot编码以生成深度分布标签。一个one-hot编码确保深度分布标签是清晰准确的,这对于通过监督深度分布模型预测的清晰度至关重要。
使用深度块的设计保证模型在深度估计中具有较高的容错性,该部分的输出
G
G
G称为frustum features。
1.2 视锥特征到体素特征(Frustum to Voxel Trans)
 得到 frustum features 后需要将特征转换成体素的形式,在低分辨率的frustum features上进行体素采样会导致出现大量相同的体素特征,文中作者直接利用到降采样前的特征层进行。
得到 frustum features 后需要将特征转换成体素的形式,在低分辨率的frustum features上进行体素采样会导致出现大量相同的体素特征,文中作者直接利用到降采样前的特征层进行。
该部分主要完成从视锥到3D real world的映射,每个体素的中心生成体素采样点,并将其转换为视锥栅格以形成视锥采样点。使用带有trilinear interpolation的采样点对视锥体特征进行采样,以填充体素特征。
1.3 生成鸟瞰图(BEV)
直接压缩(合并,折叠)体素特征到同一个高度平面得到鸟瞰图,其中,体素特征维度为X×Y×Z×C’,将Z×C’折叠为C即可得到BEV。
1.4 3D检测(3D Detection)或其他任务头
文中指出增加卷积层的数量可以扩展BEV网络的学习能力,这对于从图像生成的低质量特征中学习非常重要,而不是从最初由激光雷达点云生成的高质量特征中学习。本文使用与PointPillars相同的检测头来生成最终检测。
1.5 训练损失函数
分类是通过预测类别分布来执行的,并鼓励分布的清晰度,以便选择正确的类别。在监测深度分布网络时,本文利用分类来鼓励一个正确的深度块,使用focal loss:
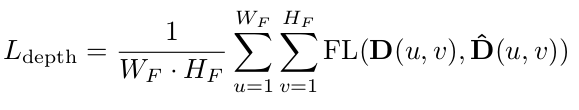 其中
D
^
\hat{D}
D^是深度分布的标签,
D
D
D是深度分布的预测
其中
D
^
\hat{D}
D^是深度分布的标签,
D
D
D是深度分布的预测
使用PointPillars[26]的分类损失
L
c
l
s
L_cls
Lcls、回归损失
L
r
e
g
L_reg
Lreg和方向分类损失
L
d
i
r
L_dir
Ldir进行三维目标检测。网络的总损失是深度和3D检测损失的结合:
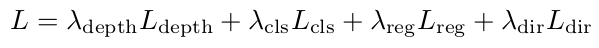
2. 预训练模型测试
对应说明文档:GETTING_STARTED
配置conda环境
下载代码,配置环境和依赖
# 1.克隆代码
git clone https://github.com/TRAILab/CaDDN.git
# 2.安装依赖库
pip install -r requirements.txt
# 3. nstall this pcdet
python setup.py develop
下载预训练模型caddn.pth,切换到tools目录下,其中tools/test.py中存放测试代码。
python test.py --cfg_file ${CONFIG_FILE} ./cfgs/kitti_models/CaDDN.yaml --batch_size 4 --ckpt ./caddn.pth
3. 模型训练
tools/train.py中存放训练代码。
python train.py

 代码解读将单独总结。
代码解读将单独总结。















 483
483











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









