







论文链接:All NLP Tasks Are Generation Tasks: A General Pretraining Framework
代码链接:https://github.com/THUDM/GLM
论文的主要贡献
1)该方法(GLM)可以在分类、无条件生成和条件生成三种任务上,仅通过预训练,就可以获得很好的效果。
2)通过使用预训练——微调一致性的方法,在分类任务上可以获得比BERT类模型更好的效果。
3)该方法可以很自然地处理可变长度的填空任务,非常有利于对下游任务的迁移。
下表展示了现有方法的适用范围及其不足

训练框架
模型结构
GLM使用类似于BERT的transformer架构。首先,将输入的token
[
x
1
,
x
2
,
⋯
,
x
n
]
[x_1,x_2,\cdots,x_n]
[x1,x2,⋯,xn],通过embedding table,投影到内嵌向量
H
0
=
[
h
1
0
,
h
2
0
,
⋯
,
h
n
0
]
\textbf{H}^0=[\textbf{h}_1^0,\textbf{h}_2^0,\cdots,\textbf{h}_n^0]
H0=[h10,h20,⋯,hn0]中。然后
L
L
L个transformer层被用来计算token的隐藏状态。每一层包含了一个多头注意力和一个位置级的全连接前馈网络。具体说来,
l
l
l层的自注意力头被定义为:
Q
l
=
H
l
W
Q
l
,
K
l
=
H
l
W
k
l
,
V
l
=
H
l
W
V
l
A
l
=
softmax
(
Q
l
(
K
l
)
T
d
k
+
M
)
V
l
\textbf{Q}^l=\textbf{H}^l\textbf{W}_{Q}^l,\textbf{K}^l=\textbf{H}^l\textbf{W}^l_k,\textbf{V}^l=\textbf{H}^l\textbf{W}^l_V \\ \textbf{A}^l=\text{softmax}(\frac{\textbf{Q}^l(\textbf{K}^l)^T}{\sqrt{d_k}}+\textbf{M})\textbf{V}^l
Ql=HlWQl,Kl=HlWkl,Vl=HlWVlAl=softmax(dkQl(Kl)T+M)Vl
这里,
W
Q
l
\textbf{W}_{Q}^l
WQl,
W
k
l
\textbf{W}^l_k
Wkl,
V
l
∈
R
d
h
×
d
k
\textbf{V}^l\in\mathbb{R}^{d_h\times d_k}
Vl∈Rdh×dk是模型参数。
M
\textbf{M}
M是自注意力掩码的矩阵,
M
i
j
=
0
M_{ij}=0
Mij=0表明token
x
i
\,x_i
xi可以访问token
x
j
\,x_j
xj,而
M
i
j
=
−
∞
M_{ij}=-\infty
Mij=−∞表明不允许访问。
对BERT的结构做了两点改动
1)重新安排了归一化层和残差连接层的顺序,当扩展到大型BERT风格模型时,这一点是很重要的。
2)使用线性层代替了预测token的前馈网络,输出位置
i
i
i可以被定义为:
p
i
=
softmax
(
h
i
L
W
o
)
\textbf{p}_i=\text{softmax}(\textbf{h}_i^L\textbf{W}_o)
pi=softmax(hiLWo)
这里,
W
o
∈
R
d
h
×
∣
V
∣
\textbf{W}_o\in \mathbb{R}^{d_h\times |\mathcal{V}|}
Wo∈Rdh×∣V∣,
∣
V
∣
|\mathcal{V}|
∣V∣是词汇的大小。
自回归空白填空
CLM通过优化自回归空白填空任务进行训练。考虑一段输入文本
x
=
[
x
1
,
⋯
,
x
n
]
x=[x_1,\cdots,x_n]
x=[x1,⋯,xn],乘上被采样的文本的跨度
{
s
1
,
⋯
,
s
m
}
\{\textbf{s}_1,\cdots,\textbf{s}_m\}
{s1,⋯,sm},这里,每一个跨度
s
i
\textbf{s}_i
si对应
x
\textbf{x}
x中一系列连续的token
[
s
i
,
1
,
⋯
,
s
i
,
l
i
]
[s_{i,1},\cdots,s_{i,l_i}]
[si,1,⋯,si,li]。文本跨度的数量和长度取决于预训练的目标。每个跨度都被替换为一个
[
M
A
S
K
]
[MASK]
[MASK]标记,形成损坏文本
x
c
o
r
r
u
p
t
\textbf{x}_{corrupt}
xcorrupt。改模型以自回归的方式从损坏的文本中跨度中缺失的标记,这意味着在预测一个跨度中缺失的标记时,模型可以访问损坏的文本以先前预测的跨度。为了充分捕捉不同跨度之间的关联,我们随机排列了这些跨度的顺序。定义
Z
m
Z_m
Zm为长度
m
m
m的可能排列的索引
[
1
,
2
,
⋯
,
m
]
[1,2,\cdots,m]
[1,2,⋯,m],
s
z
<
i
=
[
s
z
1
,
⋯
,
s
z
i
−
1
]
\textbf{s}_{\textbf{z}<i}=[\textbf{s}_{z_1},\cdots,\textbf{s}_{z_{i-1}}]
sz<i=[sz1,⋯,szi−1],预训练目标可以定义为:
max
θ
E
z
∼
Z
m
[
∑
i
=
1
m
log
p
θ
(
s
z
i
∣
x
c
o
r
r
u
p
t
,
s
z
<
i
)
]
\max_\theta\mathbb{E}_{\textbf{z}\sim Z_m}[\sum^m_{i=1}\log p_\theta(\textbf{s}_{z_i}|\textbf{x}_{corrupt},\textbf{s}_{{\text{z}<i}})]
θmaxEz∼Zm[i=1∑mlogpθ(szi∣xcorrupt,sz<i)]
就是通过损坏文本
x
c
o
r
r
u
p
t
\textbf{x}_{corrupt}
xcorrupt和已经预测出来的跨度
s
z
<
i
\textbf{s}_{\textbf{z}<i}
sz<i来预测
s
z
i
\textbf{s}_{\textbf{z}_i}
szi。
由于遵循从左到右的顺序,所示
s
i
\textbf{s}_i
si的概率可以被分解为:
p
θ
(
s
i
∣
x
c
o
r
r
u
p
t
,
s
z
<
i
)
=
∏
j
=
1
l
i
p
(
s
i
,
j
∣
x
c
o
r
r
u
p
t
,
s
z
<
i
)
p_\theta(\textbf{s}_i|\textbf{x}_{corrupt},\textbf{s}_{\textbf{z}<i})=\prod_{j=1}^{l_i}p(s_{i,j}|\textbf{x}_{corrupt},\textbf{s}_{\textbf{z}<i})
pθ(si∣xcorrupt,sz<i)=j=1∏lip(si,j∣xcorrupt,sz<i)
具体说来,为了实现自回归的填空任务,采用了如下的技巧。输入的token被分为两部分,如下图(b)所示
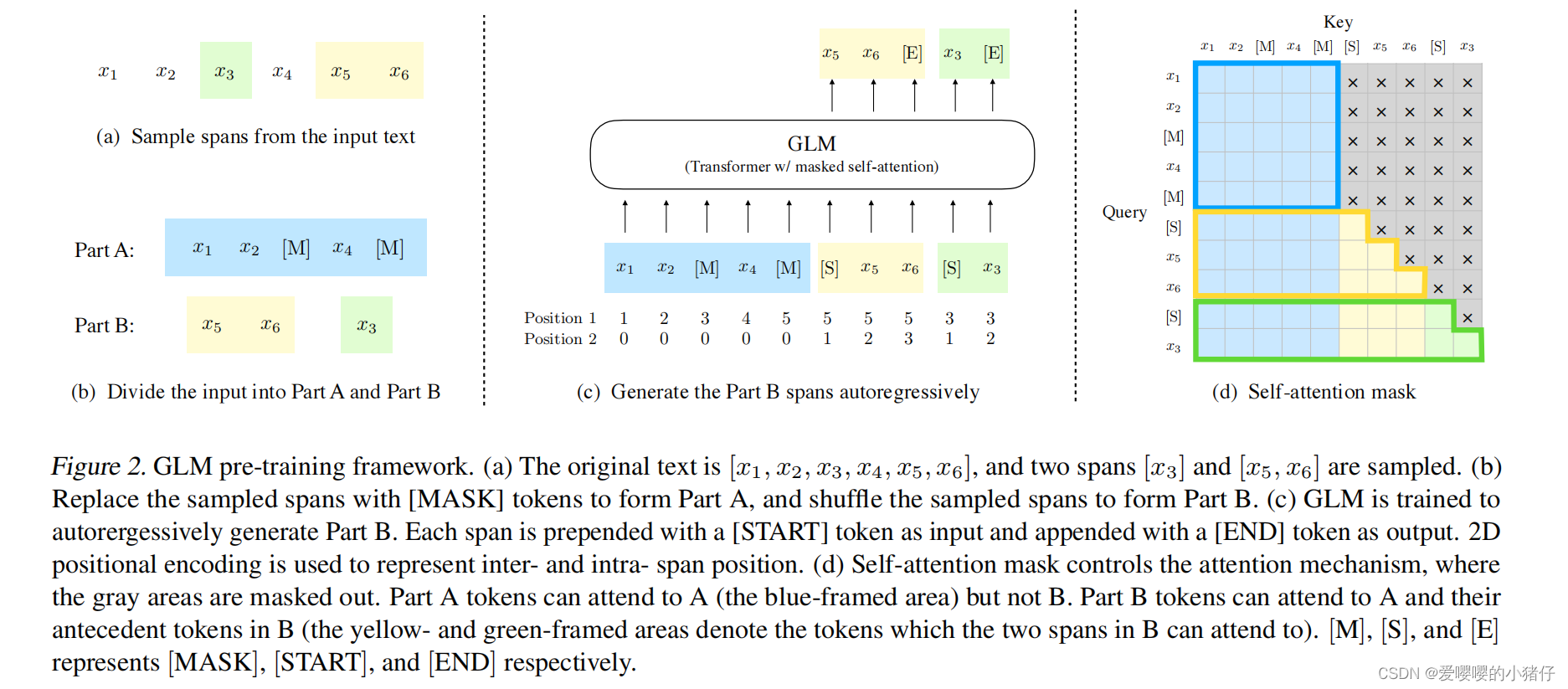
A部分包含了损坏文本
x
c
o
r
r
u
p
t
\textbf{x}_{corrupt}
xcorrupt,这里被采样的跨度被替换为
[
M
]
[M]
[M]。B部分包含了被覆盖的跨度所包含的token。A部分的token可以访问其他A部分的token,但是不能访问B部分的token,B部分的token可以关注A部分的token以及B部分在它之前的token,但是不能关注在它之后的token。与transformer中的解码器相似,每个跨度中的token在开始和结束时分别填充了两个特殊的token[START]和[END]。通过这种方式,我们的模型在一个模型中可以自动学习双向编码器(A部分)和单向解码器(B部分)。
2D位置编码
上述任务中的一个挑战就是如何编码位置信息。transformer依赖于加入到输入embedding中的位置编码来注入token的绝对和相对位置。
我们提出了一中新的2D位置编码方法,每一个token都被赋予了两个位置id。第一个位置id表示在损坏文本
x
c
o
r
r
u
p
t
\textbf{x}_{corrupt}
xcorrupt中的位置。对于B部分的token来说,它是相应的[MASK]token的位置。第二个位置id表示跨度内的位置。对A中的token来说,第二个位置id是0。对B中的token来说,第二个位置id取1到跨度长度中的值。这两个位置id通过两个单独的embedding表投影到两个位置向量中,并且添加到输入embedding中。
预训练目标
GLM的预训练目标定义为掩码跨度的自回归生成。掩码span占原始token的比例为15%。span长度来源于
λ
=
3
\lambda=3
λ=3的泊松分布。反复采用span,直到span的长度超过15%。
和BERT类似,GLM采用短距离的span。为了满足多任务的需求,还采样了一个原始token长度50%-100%的span,span的长度选取遵循均匀分布。
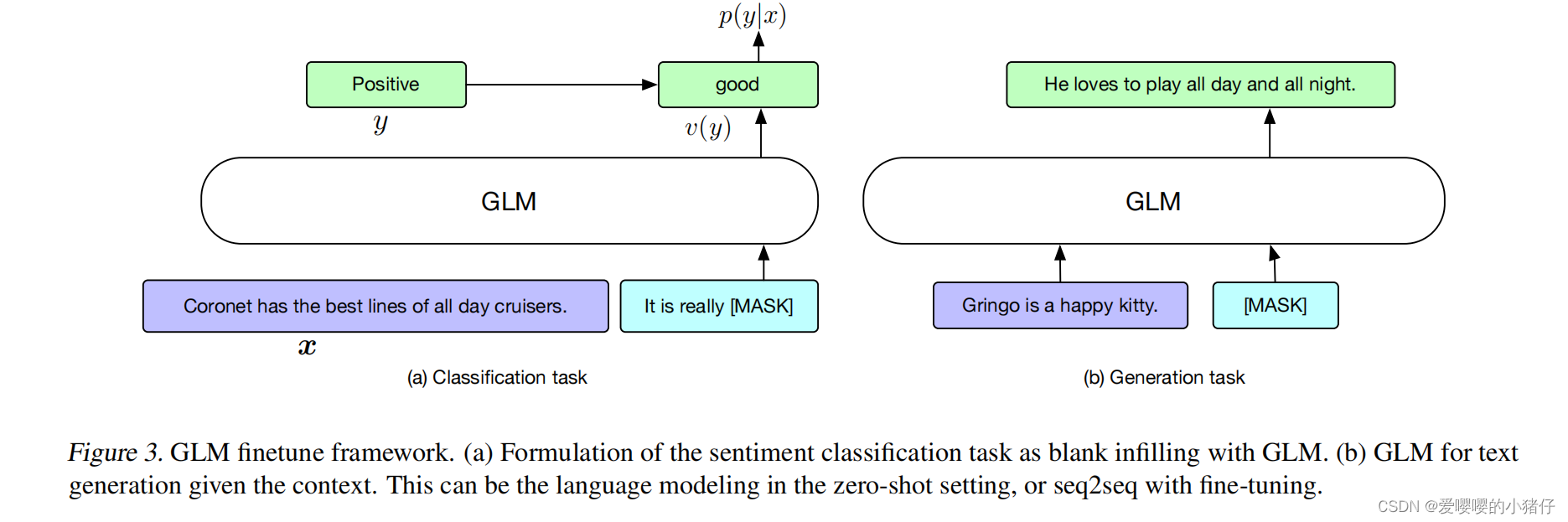
微调GLM
之前,对于下游的分类任务,一个线性分类器将预训练模型的产出作为输入,来预测正确的答案。对于序列分类任务,输入是[CLS]token的表示,测试时不同于训练时的填空任务,这会导致训练和微调不一致。
针对这个问题,我们将NLU(自然语言理解)中的分类任务也转化为填空任务。具体说来,对于
(
x
,
y
)
(\textbf{x},y)
(x,y),通过一个包含单个掩码token[MASK]的模式,将输入文本
x
\textbf{x}
x映射到一个问题
c
(
x
)
c(\textbf{x})
c(x)。这种模式应该与训练前数据集中的自然语言类似。举例说来:在一个情绪分类中的文本可以表述为“[句子],它真的[如何]”,标记
y
y
y被映射到答案中,称为表达器
v
(
y
)
v(y)
v(y)。在情绪分类任务中,标签“积极的”或者“消极的”被分别映射到待填空中的为“好的”或者“不好的”。句子是积极的还是消极的的概率和对空格预测为“好的”或者“不好的”概率成正比。因此,基于
x
\textbf{x}
x的
y
y
y的条件概率分布为:
p
(
y
∣
x
)
=
p
(
v
(
y
)
∣
c
(
x
)
)
∑
y
′
∈
Y
p
(
v
(
y
′
)
∣
c
(
x
)
)
p(y|\textbf{x})=\frac{p(v(y)|c(\textbf{x}))}{\sum_{y'\in\mathcal{Y}}p(v(y')|c(\textbf{x}))}
p(y∣x)=∑y′∈Yp(v(y′)∣c(x))p(v(y)∣c(x))
这里,
Y
\mathcal{Y}
Y是标记集合。然后就可以用交叉熵损失来微调GLM。
GLM特别适合这样的设置有两个原因。其一是GLM可以自然地处理位置长度的填空。其二,GLM打破了BERT在掩码tokrn之间的独立性假设,从而可以捕捉更多的依赖关系。
对于文本生成任务,我们直接将GLM作为自回归模型。给定文本构成的A部分,并且作为输入,该输入的最后有一个[MAKS]token。然后GLM自动回归出B部分的文本。可以直接将预训练模型用于无条件生成任务,或者微调一下GLM,部署到下游的有条件生成任务上。整个微调过程如下图所示
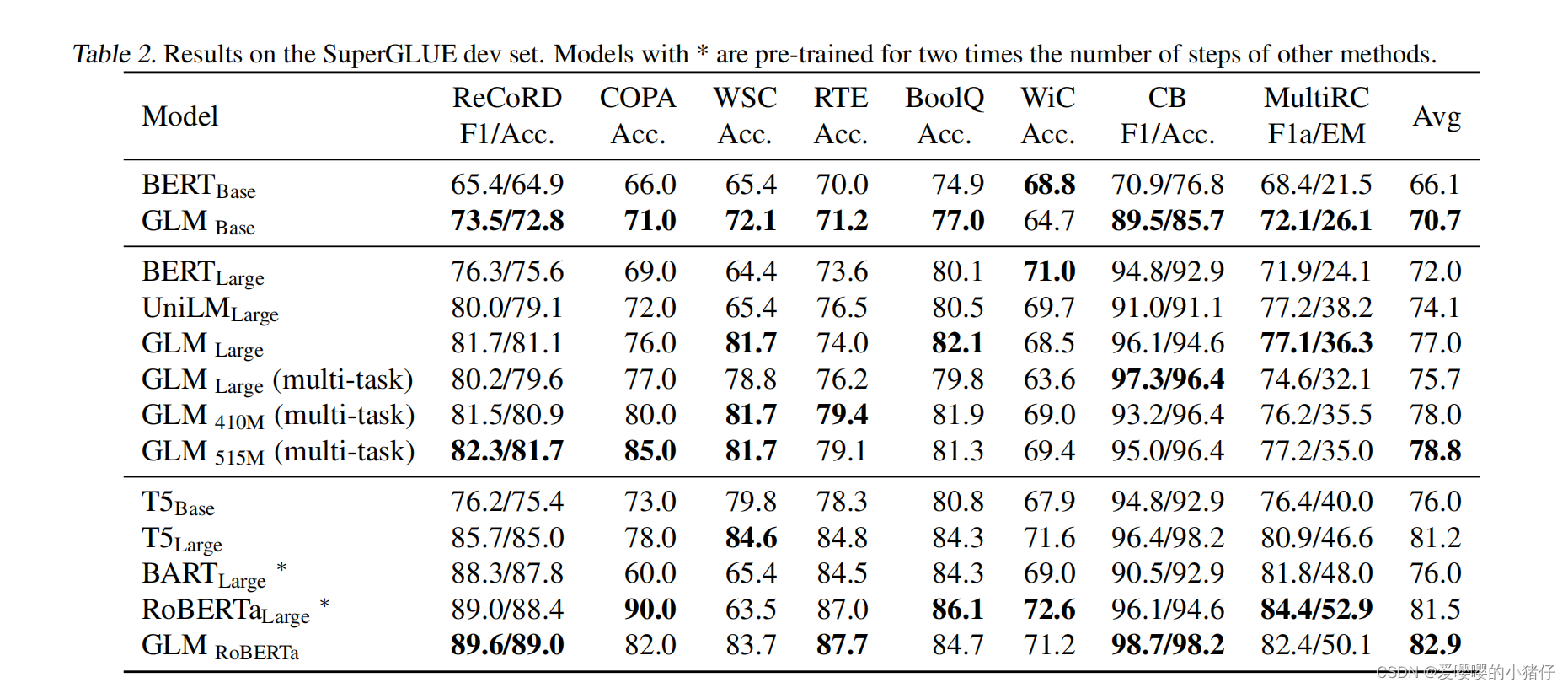
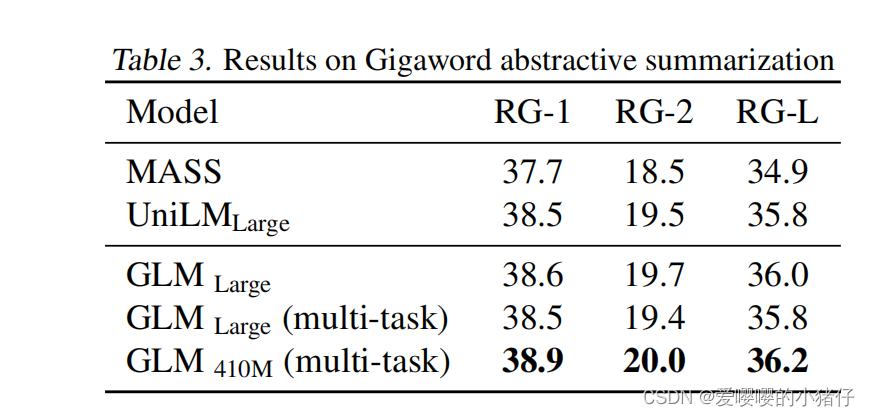
实验对比
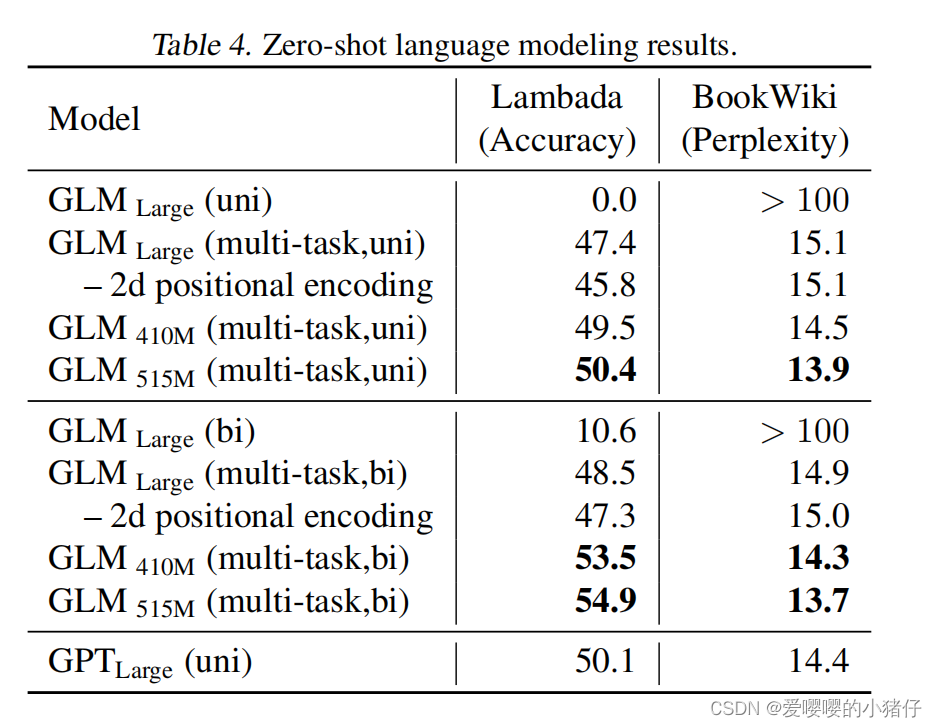
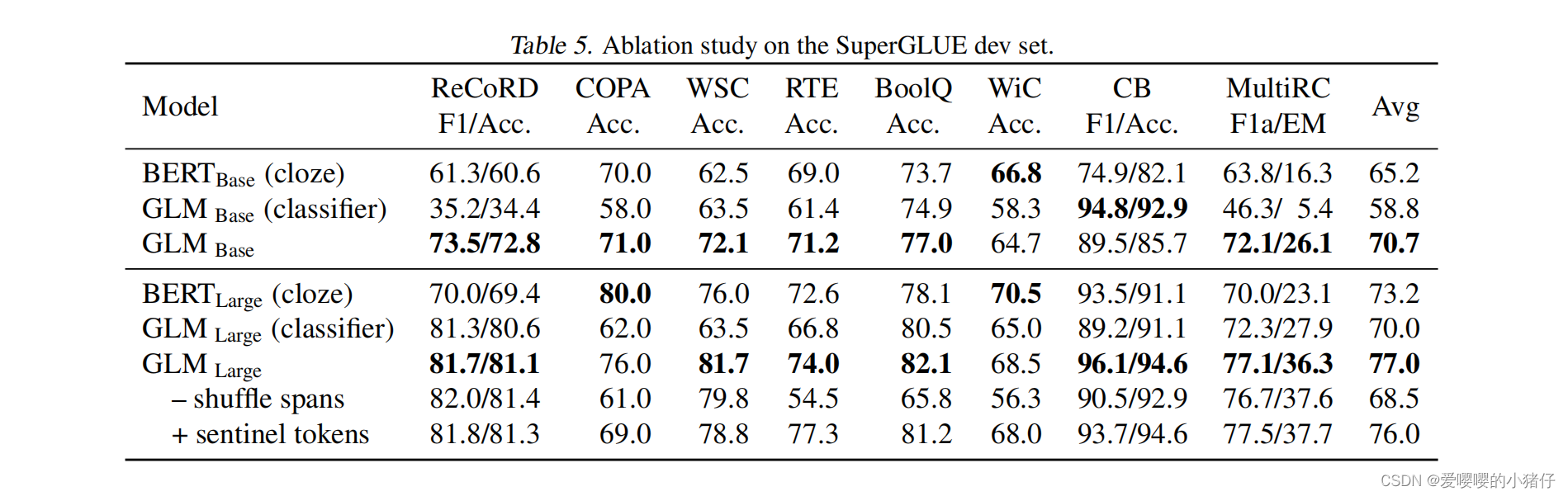















 509
509











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









