







潜在结果模型的主要内容包括:定义、推理、假设
潜在结果模型,核心假设-没有操纵就没有因果(No Causation without Manipulation)
定义1: ACE average causal effect
总体的平均因果作用(average causal effect)定义为个体因果作用的期望:
A
C
E
=
C
(
I
C
E
)
=
E
(
Y
1
−
Y
0
)
=
E
(
Y
1
)
−
E
(
Y
0
)
ACE=C(ICE)=E(Y_1-Y_0)=E(Y_1)-E(Y_0)
ACE=C(ICE)=E(Y1−Y0)=E(Y1)−E(Y0)
平均因果作用定义为:假设所有个体都接受
X
=
1
X=1
X=1的平均结果
E
(
Y
1
)
E(Y_1)
E(Y1)于假设所有个体都接受
X
=
0
X=0
X=0的平均结果
E
(
Y
0
)
E(Y_0)
E(Y0),这只是理想状态,在现实中不可能让所有个体都做
X
=
1
X=1
X=1处理,在接受
X
=
0
X=0
X=0处理,及时这样处理之后,得到的Y可能也不一致。
这里可以用于某一个子总体的平均因果作用,比如:A药对于男性和女性群体的疗效如何?
定义2:
令
V
V
V为协变量,定义
V
=
v
V=v
V=v子总体的平均作用为
E
(
Y
1
−
Y
0
∣
V
=
v
)
E(Y_1-Y_0|V=v)
E(Y1−Y0∣V=v)
人们常常关心处理组的因果作用,例如, 流行病学家并不关心吸烟对整个人群的因果作用,而只关心吸烟对吸烟人群的因果作用.
定义3:
处理组的平均因果作用定义为
E
(
Y
1
−
Y
0
∣
X
=
1
)
E(Y_1-Y_0|X=1)
E(Y1−Y0∣X=1)
称平均因果作用
A
C
E
=
E
(
Y
1
−
Y
0
)
ACE=E(Y_1-Y_0)
ACE=E(Y1−Y0)为可识别的,如果ACE可以由观测变量的分布
p
r
(
X
,
Y
,
V
)
pr(X,Y,V)
pr(X,Y,V)唯一确定。如果ACE不可识别,则以为这只是存在两个不相等的
A
C
E
≠
A
C
E
ACE \neq ACE
ACE=ACE满足观测到的数据,可以识别性往往是因果推断中最棘手的问题. 为了得到因果作用的可识别性, 通常需要有额外的假定.随机化试验是识别因果作用最有效的方法.
随机化实验
统计学家Fisher给出了识别平均因果作用的方法:随机化实验设计,随机化处理分配
X
X
X给个体
i
i
i,例如,确定个体
i
i
i的处理
X
X
X,与潜在结果及协变量的取值无关,可以保证潜在结果
(
Y
1
,
Y
0
)
(Y_1,Y_0)
(Y1,Y0)与处理分配
X
X
X独立,即在随机化分配下,有
(
Y
1
,
Y
0
)
∐
X
(Y_1,Y_0) \coprod X
(Y1,Y0)∐X有,
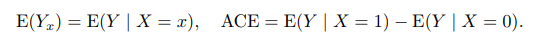
在随机化分配下, 平均因果作用表示为观测到的结果变量
Y
Y
Y在处理组
X
=
1
X=1
X=1与对照组
X
=
0
X=0
X=0中期望之差不再含有潜在结果变量
Y
1
Y_1
Y1和
Y
0
Y_0
Y0,因此,他是可识别的,通过分别估计
E
(
Y
∣
X
=
1
)
E(Y|X=1)
E(Y∣X=1)和
E
(
Y
∣
X
=
0
)
E(Y|X=0)
E(Y∣X=0),传统的统计推断方法可以用来推断平均因为作用。
在随机化试验中,例如,研究吸烟对肺癌的作用,不能随机化分配一个人吸烟或不吸烟。在实际经常面临的其他问题,如代价昂贵和个体不依从等也都限制了随机化试验的作用。















 416
416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











