









感谢
孙裕道 深度之眼 2022-06-01 18:00 发表于上海
GAN原理介绍
Generative adversarial networks 生成对抗神经网络
G-Generator 生成器
D-Discriminator 判别器

有一个临摹假画的大神,有一天他对蒙娜丽莎的微笑进行临摹。
有一个鉴别名画的大师,有一天他对假画大神的蒙娜丽莎的微笑进行鉴别。
最初:大神的画太过粗糙,一眼就被大师鉴别为假画
经过:经过一次又一次的临摹,一次又一次的别鉴别为假
终于:有一天,大神他成功了,他临摹的画,终于骗过了大师,连大师也分别不出来蒙娜丽莎的微笑真迹与假画了
术语:
GAN是由生成器G和判别器D组成,通过大量样本数据训练使得生成器的生成能力和判别器的判别能力在对抗中逐步提高,最终目的是让生成器G输入到生成器中生成假的样本。
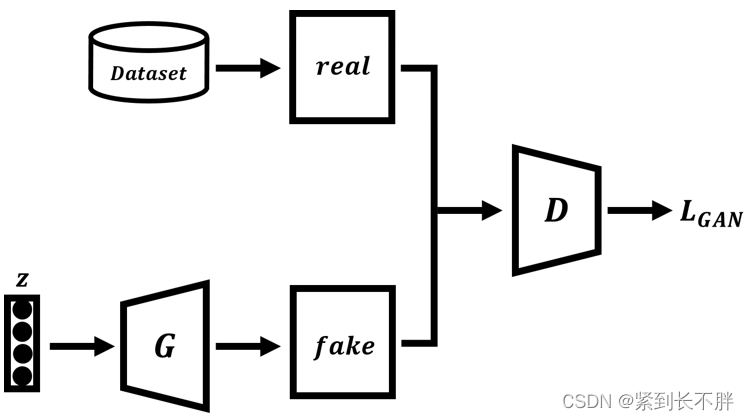
训练过程
- 首先在真实数据集中采样出一批真实样本
- 同时从某个分布中随机生成一些噪声向量
- 接着将噪声向量输入到生成器中生成假的样本数据
- 最后把真实样本与等量的假的样本输入到判别器中进行判别
GAN训练的过程可以描述为求解一个二元函数极小极大值的过程,具体的公式如下所示:
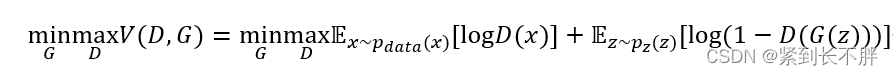
优化对抗损失
V
(
D
,
G
)
V(D,G)
V(D,G)可以同时达到两个目的,第一个目的是让生成器G能够生成真实的样本,第二个目的是让判别器D能更好地区分开真实样本和生成样本。
生成器G的Loss function
训练生成器的损失函数其实是对抗损失
V
(
D
,
G
)
V(D,G)
V(D,G)中关于噪声z的项,其损失函数为:
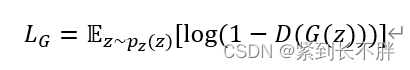
生成器的目标是希望生成器生成的样本越像真的越好,具体体现在数学公式中为:
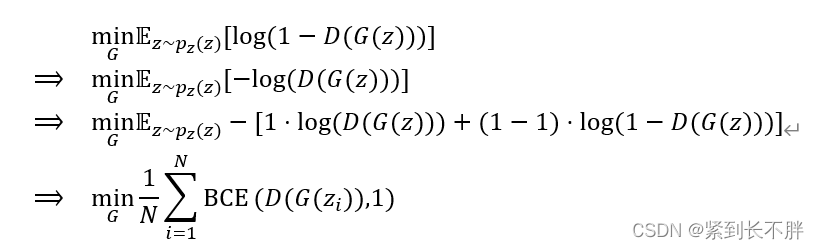
其中
B
C
E
(
.
,
.
)
BCE(.,.)
BCE(.,.)表示二元交叉熵函数。则由上可知,GAN中生成器最小化损失函数LG可以写成最小化二元交叉熵函数的形式。
判别器D的Loss function
训练生成器的损失函数其实是对抗损失
V
(
D
,
G
)
V(D,G)
V(D,G)中关于样本x的项,其损失函数为:
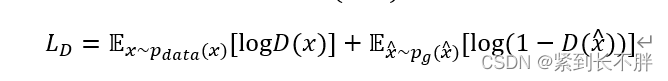
判别器的目标是希望判别器能够更好的区分出生成样本和真实样本,具体体现在数学公式中为:
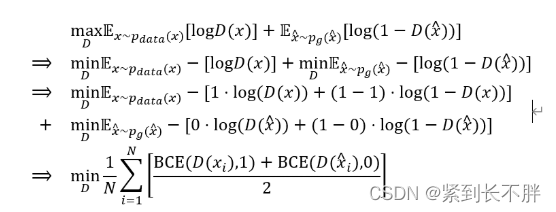
其中x表示真是的数据样本,x_hat表示生成器生成的样本,由上可以发现,GAN中判别器最大优化损失函数LD可以写成最小化两个二元交叉熵函数的形式。
GAN代码介绍
本节介绍用GAN和DCGAN生成mnist手写数据集,GAN和DCGAN的网络结构以及完整的实现代码分别如下所示:
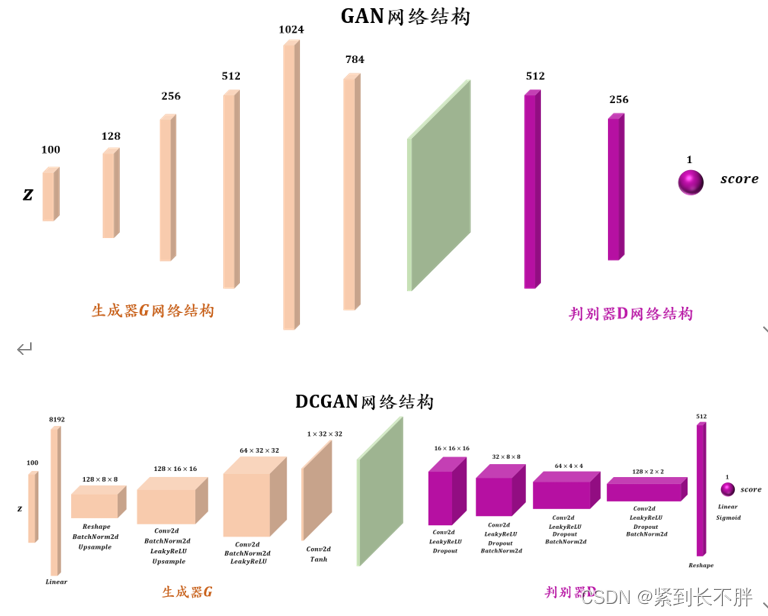
import argparse
from torchvision import datasets, transforms
import torch
import torch.nn as nn
import os
import numpy as np
from torchvision.utils import save_image
def args_parse():
parser = argparse.ArgumentParser()
parser.add_argument("--n_epoches", type=int, default=100, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=256, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--n_cpu", type=int, default=1, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=100, help="interval between image sampling")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--type", type=str, default='GAN', help="The type of GAN")
return parser.parse_args()
class Generator(nn.Module):
def __init__(self, latent_dim, img_shape):
super(Generator, self).__init__()
self.img_shape = img_shape
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), self.img_shape[0], self.img_shape[1], self.img_shape[2])
return img
class Discriminator(nn.Module):
def __init__(self, img_shape):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
class Generator_CNN(nn.Module):
def __init__(self, latent_dim, img_shape):
super(Generator_CNN, self).__init__()
self.init_size = img_shape[1] // 4
self.l1 = nn.Sequential(nn.Linear(latent_dim, 128 * self.init_size ** 2)) # 100 ——> 128 * 8 * 8 = 8192
self.conv_blocks = nn.Sequential(
nn.BatchNorm2d(128),
nn.Upsample(scale_factor = 2),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.BatchNorm2d(128, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Upsample(scale_factor = 2),
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, img_shape[0], 3, stride=1, padding=1),
nn.Tanh()
)
def forward(self, z):
out = self.l1(z)
out = out.view(out.shape[0], 128, self.init_size, self.init_size)
img = self.conv_blocks(out)
return img
class Discriminator_CNN(nn.Module):
def __init__(self, img_shape):
super(Discriminator_CNN, self).__init__()
def discriminator_block(in_filters, out_filters, bn=True):
block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1),
nn.LeakyReLU(0.2,inplace=True),
nn.Dropout2d(0.25)]
if bn:
block.append(nn.BatchNorm2d(out_filters, 0.8))
return block
self.model = nn.Sequential(
*discriminator_block(img_shape[0], 16, bn=False),
*discriminator_block(16, 32),
*discriminator_block(32, 64),
*discriminator_block(64, 128),
)
ds_size = img_shape[1] // 2 ** 4
self.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1), nn.Sigmoid()) # 128 * 2 * 2 ——> 1
def forward(self, img):
out = self.model(img)
out = out.view(out.shape[0], -1)
validity = self.adv_layer(out)
return validity
def train():
opt = args_parse()
transform = transforms.Compose(
[
transforms.Resize(opt.img_size),
transforms.ToTensor(),
transforms.Normalize([0.5],[0.5])
])
mnist_data = datasets.MNIST(
"mnist-data",
train=True,
download=True,
transform = transform
)
train_loader = torch.utils.data.DataLoader(
mnist_data,
batch_size=opt.batch_size,
shuffle=True)
img_shape = (opt.channels, opt.img_size, opt.img_size)
# Construct generator and discriminator
if opt.type == 'DCGAN':
generator = Generator_CNN(opt.latent_dim, img_shape)
discriminator = Discriminator_CNN(img_shape)
else:
generator = Generator(opt.latent_dim, img_shape)
discriminator = Discriminator(img_shape)
adversarial_loss = torch.nn.BCELoss()
cuda = True if torch.cuda.is_available() else False
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Loss function
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
print(generator)
print(discriminator)
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
for epoch in range(opt.n_epoches):
for i, (imgs, _) in enumerate(train_loader):
# adversarial ground truths
valid = torch.ones(imgs.shape[0], 1).type(Tensor)
fake = torch.zeros(imgs.shape[0], 1).type(Tensor)
real_imgs = imgs.type(Tensor)
############# Train Generator ################
optimizer_G.zero_grad()
# sample noise as generator input
z = torch.tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))).type(Tensor)
# Generate a batch of images
gen_imgs = generator(z)
# G-Loss
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
############# Train Discriminator ################
optimizer_D.zero_grad()
# D-Loss
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G Loss: %f]"
% (epoch, opt.n_epoches, i , len(train_loader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(train_loader) + i
os.makedirs("images", exist_ok=True)
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % (batches_done), nrow=5, normalize=True )
if __name__ == '__main__':
train()```














 1217
1217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









