






 本文介绍了Toshiyuki Toshiyuki关于能源DEA的研究,探讨了期望产出(业务效率和规模报酬)与非期望产出(环境效率和规模损害)的模型,包括RAM模型的应用,以及RTS与DTS的区别和联合效率的计算。论文详细阐述了有效和无效DMU的效率计算,并强调了管理策略的规模效应指导原则。
本文介绍了Toshiyuki Toshiyuki关于能源DEA的研究,探讨了期望产出(业务效率和规模报酬)与非期望产出(环境效率和规模损害)的模型,包括RAM模型的应用,以及RTS与DTS的区别和联合效率的计算。论文详细阐述了有效和无效DMU的效率计算,并强调了管理策略的规模效应指导原则。
能源DEA--对于业务和环境评估的规模报酬与规模损害
文献介绍

这篇文献发表于
E
u
r
o
p
e
a
n
J
o
u
r
n
a
l
o
f
O
p
e
r
a
t
i
o
n
a
l
R
e
s
e
a
r
c
h
European\;Journal\;of\;Operational\;Research
EuropeanJournalofOperationalResearch,作者是
T
o
s
h
i
y
u
k
i
Toshiyuki
Toshiyuki。这位作者在能源DEA上真的是发表了很多很多的文章,每篇文章重复的太多了(当然,重复的都是自己的文章,查重不在怕的。)
这篇文章主要对期望产出与非期望产出进行深入。题目的翻译为:基于DEA的业务和环境评估的规模回报和规模损害的衡量:如何管理理想(好的)和不理想(坏的)产出?
其中,要先指出:1. 题目中的 R e t u r n s t o s c a l e Returns\;to\;scale Returnstoscale和 o p e r a t i o n a l a s s e s s m e n t operational\;assessment operationalassessment都是针对期望产出的;而 D a m a g e s t o S c a l e Damages\;to\;Scale DamagestoScale和 e n v i r o n m e n t a l a s s e s s m e n t environmental\;assessment environmentalassessment都是针对非期望产出。2. 这篇文献中用到的DEA模型是RAM模型( R a n g e − A d j u s t e d m e a s u r e Range-Adjusted\;measure Range−Adjustedmeasure)。
对于期望产出的业务效率(operational efficiency)以及规模报酬(RTS)
先介绍一下符号:投入
X
j
=
(
x
1
j
,
x
2
j
,
…
,
x
m
j
)
X_j=(x_{1j},x_{2j},\dots,x_{mj})
Xj=(x1j,x2j,…,xmj),期望产出
G
j
=
(
g
1
j
,
g
2
j
,
…
,
g
s
j
)
G_j=(g_{1j},g_{2j},\dots,g_{sj})
Gj=(g1j,g2j,…,gsj),非期望产出
B
j
=
(
b
1
j
,
b
2
j
,
…
,
b
h
j
)
B_j=(b_{1j},b_{2j},\dots,b_{hj})
Bj=(b1j,b2j,…,bhj),并且都是正数。
这一部分内容都是针对期望产出。
直接给出对应的模型公式model(1):
M a x ∑ i = 1 m R i x d i x + ∑ r = 1 s R r g d r g s . t . ∑ j = 1 n x i j λ j + d i x = s i k ( i = 1 , … , m ) , ∑ j = 1 n g r j λ j − d r g = g r k , ∑ j = 1 n λ j = 1 , λ j ≥ 0 ( j = 1 , … , n ) , d i x ≥ 0 ( i = 1 , … , m ) , a n d d r g ≥ 0 ( r = 1 , … , s ) Max\quad\sum_{i=1}^{m}R_{i}^{x}d_{i}^{x}\;+\;\sum_{r=1}^{s}R_{r}^{g}d_{r}^{g}\\s.t.\quad\sum_{j=1}^{n}x_{ij}\lambda_{j}+d_i^x=s_{ik}(i=1,\dots,m),\\\sum_{j=1}^ng_{rj}\lambda_j-d_r^g=g_{rk},\\\sum_{j=1}^n\lambda_j=1,\lambda_j\ge0(j=1,\dots,n),\\d_i^x\ge0(i=1,\dots,m),and\quad{}d_r^g\ge0(r=1,\dots,s) Maxi=1∑mRixdix+r=1∑sRrgdrgs.t.j=1∑nxijλj+dix=sik(i=1,…,m),j=1∑ngrjλj−drg=grk,j=1∑nλj=1,λj≥0(j=1,…,n),dix≥0(i=1,…,m),anddrg≥0(r=1,…,s)
其中上述的 R i x = 1 ( m + s ) ( m a x j x i j − m i n j x i j ) , R r g = 1 ( m + s ) ( m a x j g r j − m i n j g r j ) R_i^x=\frac{1}{(m+s)(\mathop{max}\limits_{j}{x_{ij}}-\mathop{min}\limits_{j}{x_{ij}})},\quad{}R_r^g=\frac{1}{(m+s)(\mathop{max}\limits_{j}{g_{rj}}-\mathop{min}\limits_{j}{g_{rj}})} Rix=(m+s)(jmaxxij−jminxij)1,Rrg=(m+s)(jmaxgrj−jmingrj)1
根据上述公式,可以得到 o p e r a t i o n a l e f f i c i e n c y operational\;efficiency operationalefficiency为 θ = 1 − ( ∑ i = 1 m R i x d i x + ∑ r = 1 s R r g d r g ) \theta=1-(\sum_{i=1}^{m}R_{i}^{x}d_{i}^{x}\;+\;\sum_{r=1}^{s}R_{r}^{g}d_{r}^{g}) θ=1−(∑i=1mRixdix+∑r=1sRrgdrg)
那么上述model(1)的对偶模型为model(2),如下:
M i n ∑ i = 1 m v i x i k − ∑ r = 1 s u r g r k + σ s . t . ∑ i = 1 m v i x i j − ∑ r = 1 s u r g r j + σ ≥ 0 ( j = 1 , … , n ) v i ≥ R i x ( i = 1 , … , m ) u r ≥ R r g ( r = 1 , … , s ) σ : U R S Min\quad\sum_{i=1}^mv_ix_{ik}-\sum_{r=1}^su_rg_{rk}+\sigma\\s.t.\quad\sum_{i=1}^mv_ix_{ij}-\sum_{r=1}^su_rg_{rj}+\sigma\ge0(j=1,\dots,n)\\v_i\ge{R_i^x}(i=1,\dots,m)\\u_r\ge{R_r^g}(r=1,\dots,s)\\\sigma:URS Mini=1∑mvixik−r=1∑surgrk+σs.t.i=1∑mvixij−r=1∑surgrj+σ≥0(j=1,…,n)vi≥Rix(i=1,…,m)ur≥Rrg(r=1,…,s)σ:URS
基于model(1)和(2),可以写出规模效率
S
E
(
s
c
a
l
e
e
f
f
i
c
i
e
n
c
y
)
SE(scale\;efficiency)
SE(scaleefficiency)。并且SE分两类进行讨论:
第一类,
D
M
U
0
DMU_0
DMU0是有效情况时,那么
S
E
=
∑
i
=
1
m
v
i
∗
x
i
k
∑
r
=
1
s
u
r
∗
g
r
k
SE=\frac{\sum_{i=1}^mv_i^*x_{ik}}{\sum_{r=1}^su_{r}^*g_{rk}}
SE=∑r=1sur∗grk∑i=1mvi∗xik,又因为
∑
r
=
1
s
u
r
∗
g
r
k
=
∑
r
=
1
s
v
r
∗
x
i
k
+
σ
∗
\sum_{r=1}^su_{r}^*g_{rk}=\sum_{r=1}^sv_r^*x_{ik}+\sigma^*
∑r=1sur∗grk=∑r=1svr∗xik+σ∗,所以:
S
E
=
∑
i
=
1
m
v
i
∗
x
i
k
∑
r
=
1
s
u
r
∗
g
r
k
=
∑
i
=
1
m
v
i
∗
x
i
k
∑
r
=
1
s
v
r
∗
x
i
k
+
σ
∗
=
1
1
+
σ
∗
/
∑
i
=
1
m
v
i
∗
x
i
k
SE=\frac{\sum_{i=1}^mv_i^*x_{ik}}{\sum_{r=1}^su_{r}^*g_{rk}}=\frac{\sum_{i=1}^mv_i^*x_{ik}}{\sum_{r=1}^sv_r^*x_{ik}+\sigma^*}=\frac{1}{1+\sigma^*/\sum_{i=1}^mv_i^*x_{ik}}
SE=∑r=1sur∗grk∑i=1mvi∗xik=∑r=1svr∗xik+σ∗∑i=1mvi∗xik=1+σ∗/∑i=1mvi∗xik1
第二类,
D
M
U
0
DMU_0
DMU0是非有效情况时,那么该
D
M
U
0
DMU_0
DMU0在前沿上的投影点为
(
x
i
k
−
d
i
x
∗
,
g
r
k
+
d
r
g
∗
)
(x_{ik}-d_i^{x*},g_{rk}+d_{r}^{g*})
(xik−dix∗,grk+drg∗):
S
E
=
∑
i
=
1
m
v
i
∗
(
x
i
k
−
d
i
x
∗
)
∑
r
=
1
s
u
r
∗
(
g
r
k
+
d
r
g
∗
)
SE=\frac{\sum_{i=1}^mv_i^*(x_{ik}-d_i^{x*})}{\sum_{r=1}^su_{r}^*(g_{rk}+d_{r}^{g*})}
SE=∑r=1sur∗(grk+drg∗)∑i=1mvi∗(xik−dix∗),又因为model(1)与(2)的目标函数的值是相等的,即
∑
i
=
1
m
v
i
∗
x
i
k
−
∑
r
=
1
s
u
r
∗
g
r
k
+
σ
∗
=
∑
i
=
1
m
R
i
x
d
i
x
∗
+
∑
r
=
1
s
R
r
g
d
r
g
∗
\sum_{i=1}^mv_i^*x_{ik}-\sum_{r=1}^su_r^*g_{rk}+\sigma^*=\sum_{i=1}^mR_i^xd_i^{x*}+\sum_{r=1}^sR_r^gd_r^{g*}
∑i=1mvi∗xik−∑r=1sur∗grk+σ∗=∑i=1mRixdix∗+∑r=1sRrgdrg∗,所以:
S
E
=
∑
i
=
1
m
v
i
∗
(
x
i
k
−
d
i
x
∗
)
∑
r
=
1
s
u
r
∗
(
g
r
k
+
d
r
g
∗
)
=
∑
i
=
1
m
v
i
∗
(
x
i
k
−
d
i
x
∗
)
∑
i
=
1
m
(
v
i
∗
x
i
k
−
R
i
x
d
i
x
∗
)
+
∑
r
=
1
s
(
u
r
∗
−
R
r
g
)
d
r
g
∗
+
σ
∗
=
1
1
+
σ
∗
/
∑
i
=
1
m
v
i
∗
(
x
i
k
−
d
i
x
∗
)
SE=\frac{\sum_{i=1}^mv_i^*(x_{ik}-d_i^{x*})}{\sum_{r=1}^su_{r}^*(g_{rk}+d_{r}^{g*})}=\frac{\sum_{i=1}^mv_i^*(x_{ik}-d_i^{x*})}{\sum_{i=1}^m(v_i^*x_{ik}-R_i^xd_i^{x*})+\sum_{r=1}^s(u_r^*-R_r^g)d_r^{g*}+\sigma^*}\\=\frac{1}{1+\sigma^*/\sum_{i=1}^mv_i^*(x_{ik}-d_i^{x*})}
SE=∑r=1sur∗(grk+drg∗)∑i=1mvi∗(xik−dix∗)=∑i=1m(vi∗xik−Rixdix∗)+∑r=1s(ur∗−Rrg)drg∗+σ∗∑i=1mvi∗(xik−dix∗)=1+σ∗/∑i=1mvi∗(xik−dix∗)1
对于非期望产出的环境效率(environmental efficiency)以及规模损害(DTS)
此时,模型公式变为(model3):
M
a
x
∑
i
=
1
m
R
i
x
d
i
x
+
∑
f
=
1
h
R
f
b
d
f
b
s
.
t
.
∑
j
=
1
n
x
i
j
λ
j
−
d
i
x
=
x
i
k
(
i
=
1
,
…
,
m
)
∑
j
=
1
n
b
f
j
λ
j
+
d
f
b
=
b
f
k
(
f
=
1
,
…
,
h
)
∑
j
=
1
n
λ
j
=
1
,
λ
j
≥
0
(
j
=
1
,
…
,
n
)
d
i
x
≥
0
(
i
=
1
,
…
,
m
)
a
n
d
d
f
b
≥
0
(
f
=
1
,
…
,
h
)
Max\quad\sum_{i=1}^mR_i^xd_i^x+\sum_{f=1}^hR_f^bd_f^b\\s.t.\quad\sum_{j=1}^nx_{ij}\lambda_j-d_i^x=x_{ik}(i=1,\dots,m)\\\sum_{j=1}^nb_{fj}\lambda_j+d_f^b=b_{fk}(f=1,\dots,h)\\\sum_{j=1}^n\lambda_j=1,\lambda_j\ge0(j=1,\dots,n)\\d_i^x\ge0(i=1,\dots,m)\;and\;d_f^b\ge0(f=1,\dots,h)
Maxi=1∑mRixdix+f=1∑hRfbdfbs.t.j=1∑nxijλj−dix=xik(i=1,…,m)j=1∑nbfjλj+dfb=bfk(f=1,…,h)j=1∑nλj=1,λj≥0(j=1,…,n)dix≥0(i=1,…,m)anddfb≥0(f=1,…,h)
并且
R
f
b
=
1
(
m
+
h
)
(
m
a
x
j
b
f
j
−
m
i
n
j
b
f
j
)
R_f^b=\frac{1}{(m+h)(\mathop{max}\limits_{j}b_{fj}-\mathop{min}\limits_jb_{fj})}
Rfb=(m+h)(jmaxbfj−jminbfj)1,
R
i
x
R_i^x
Rix与上文一样。
同理,此时的效率分数为 θ = 1 − ( ∑ i = 1 m R i x d i x + ∑ f = 1 h R f b d f b ) \theta=1-(\sum_{i=1}^mR_i^xd_i^x+\sum_{f=1}^hR_f^bd_f^b) θ=1−(∑i=1mRixdix+∑f=1hRfbdfb)
model(3)的对偶形式为model(4):
M
i
n
−
∑
i
=
1
m
v
i
x
i
k
+
∑
f
=
1
h
w
f
b
f
k
+
σ
s
.
t
.
−
∑
i
=
1
m
v
i
s
i
j
+
∑
f
=
1
h
w
f
b
f
j
+
σ
≥
0
(
j
=
1
,
…
,
n
)
,
v
i
≥
R
i
x
(
i
=
1
,
…
,
m
)
w
f
≥
R
f
b
(
f
=
1
,
…
,
h
)
σ
:
U
R
S
Min\quad-\sum_{i=1}^mv_ix_{ik}+\sum_{f=1}^hw_fb_{fk}+\sigma\\s.t.\quad-\sum_{i=1}^mv_is_{ij}+\sum_{f=1}^hw_fb_{fj}+\sigma\ge0(j=1,\dots,n),\\v_i\ge{R_i^x}(i=1,\dots,m)\\w_f\ge{R_f^b}(f=1,\dots,h)\\\sigma:URS
Min−i=1∑mvixik+f=1∑hwfbfk+σs.t.−i=1∑mvisij+f=1∑hwfbfj+σ≥0(j=1,…,n),vi≥Rix(i=1,…,m)wf≥Rfb(f=1,…,h)σ:URS
根据model(3)、(4),可以写出规模损害
S
D
(
s
c
a
l
e
d
a
m
a
g
e
)
SD(scale\;damage)
SD(scaledamage)。同样的,分为两类进行展开:
第一类,当
D
M
U
0
DMU_0
DMU0有效时,即松弛为0,model(3)、(4)的目标函数都为0,那么
∑
i
=
1
m
v
i
x
i
k
+
∑
f
=
1
h
w
f
b
f
k
+
σ
=
0
\sum_{i=1}^mv_ix_{ik}+\sum_{f=1}^hw_fb_{fk}+\sigma=0
∑i=1mvixik+∑f=1hwfbfk+σ=0,则:
S
D
=
∑
i
=
1
m
v
i
∗
x
i
k
∑
f
=
1
h
w
f
∗
b
f
k
=
∑
i
=
1
m
v
i
∗
x
i
k
∑
i
=
1
m
v
i
∗
x
i
k
−
σ
∗
=
1
1
−
σ
∗
/
∑
i
=
1
m
v
i
∗
x
i
k
SD=\frac{\sum_{i=1}^mv_i^*x_{ik}}{\sum_{f=1}^hw_f^*b_{fk}}=\frac{\sum_{i=1}^mv_i^*x_{ik}}{\sum_{i=1}^mv_i^*x_{ik}-\sigma^*}=\frac{1}{1-\sigma^*/\sum_{i=1}^mv_i^*x_{ik}}
SD=∑f=1hwf∗bfk∑i=1mvi∗xik=∑i=1mvi∗xik−σ∗∑i=1mvi∗xik=1−σ∗/∑i=1mvi∗xik1
第二类,当
D
M
U
0
DMU_0
DMU0无效时,那么此时投影点坐标为
(
X
k
+
d
x
∗
,
B
k
−
d
b
∗
)
(X_k+d^{x*},B_k-d^{b*})
(Xk+dx∗,Bk−db∗),根据model(3)、(4)的目标函数值相等,即
−
∑
i
=
1
m
v
i
∗
x
i
k
+
∑
f
=
1
h
w
f
∗
b
f
k
+
σ
=
∑
i
=
1
m
R
i
x
d
i
x
∗
+
∑
f
=
1
h
R
f
b
d
f
b
∗
-\sum_{i=1}^mv_i^*x_{ik}+\sum_{f=1}^hw_f^*b_{fk}+\sigma=\sum_{i=1}^mR_i^xd_i^{x*}+\sum_{f=1}^hR_f^bd_f^{b*}
−∑i=1mvi∗xik+∑f=1hwf∗bfk+σ=∑i=1mRixdix∗+∑f=1hRfbdfb∗,那么:
S
D
=
∑
i
=
1
m
v
i
∗
(
x
i
k
+
d
i
x
∗
)
∑
f
=
1
h
w
f
∗
(
b
f
k
−
d
f
b
∗
)
=
∑
i
=
1
m
v
i
∗
(
x
i
k
+
d
i
x
∗
)
∑
i
=
1
m
(
v
i
∗
x
i
k
+
R
i
x
d
i
x
∗
)
+
∑
f
=
1
h
(
R
f
b
−
w
f
∗
)
d
f
h
∗
−
σ
∗
=
1
1
−
σ
∗
/
∑
i
=
1
m
v
i
∗
(
x
i
k
+
d
i
x
∗
)
SD=\frac{\sum_{i=1}^mv_i^*(x_{ik}+d_i^{x*})}{\sum_{f=1}^hw_f^*(b_{fk}-d_f^{b*})}=\frac{\sum_{i=1}^mv_i^*(x_{ik}+d_i^{x*})}{\sum_{i=1}^m(v_i^*x_{ik}+R_i^xd_i^{x*})+\sum_{f=1}^h(R_f^b-w_f^*)d_f^{h*}-\sigma^*}\\=\frac{1}{1-\sigma^*/\sum_{i=1}^mv_i^*(x_{ik}+d_i^{x*})}
SD=∑f=1hwf∗(bfk−dfb∗)∑i=1mvi∗(xik+dix∗)=∑i=1m(vi∗xik+Rixdix∗)+∑f=1h(Rfb−wf∗)dfh∗−σ∗∑i=1mvi∗(xik+dix∗)=1−σ∗/∑i=1mvi∗(xik+dix∗)1
RTS与DTS之间的差别
RTS与DTS之间的区别有好几点,其中一点与
σ
\sigma
σ的符号相关,它们是相反的。(这里不展开详说,有兴趣可直接自己看这篇文献)。
我个人觉得最重要的一点,便是RTS与DTS所对应的实际意义(见表格)。

如果RTS是increasing,那么应该扩大规模;若是decreasing,那么应该缩小当前规模。但是对于DTS来说,如果是decreasing,反而应该扩大当前规模;若DTS是increasing的,首先,非期望产出增长的过快,肯定是要缩小当前规模的,同时可能隐含着管理问题和技术设备问题。
联合效率以及RTS/DTS
(敲不动公式,直接贴图了)
上述的model(1)-(4)都是只针对期望产出/非期望产出而言的,那么接下来,两者一起出现在模型中,即model(5):
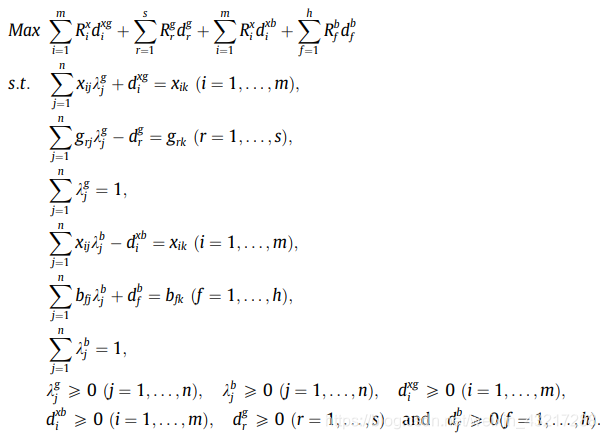
同理,此时的效率为:
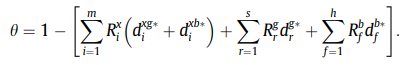
上述model(5)的对偶形式为,Model(6)如下:
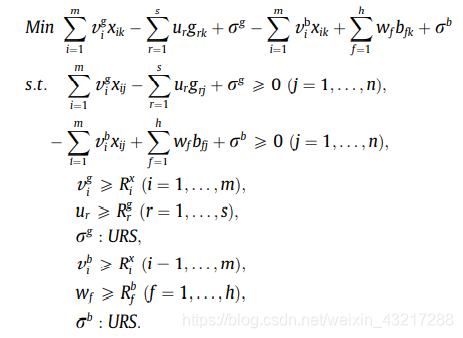
根据Model(5)和(6),同样的可以写出SE以及SD,同样的也是各分两种情况。
当
D
M
U
0
DMU_0
DMU0是有效时:
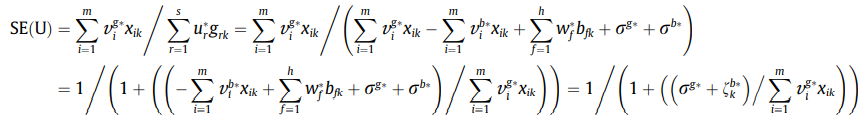
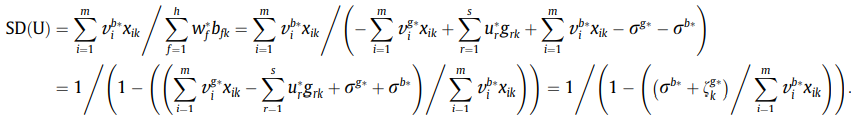
当
D
M
U
0
DMU_0
DMU0是非有效时,那么到前沿的投影点便会对应加减上各自的松弛:
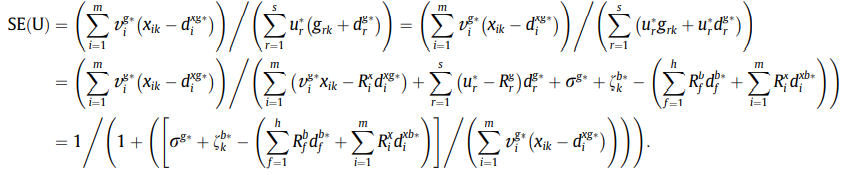
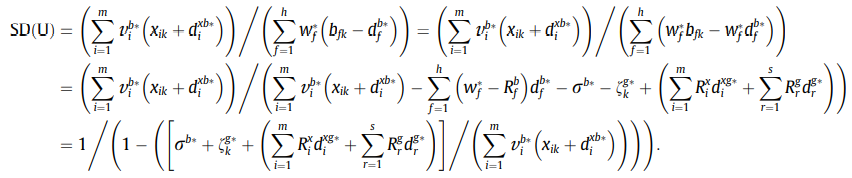

















 481
481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









