







一些数据集包含类不平衡,并且在某些类中有比其他类多得多的实例。如果训练集中的不平衡没有反映在实际的数据流中,就会导致机器学习分类的平均精度较差。
在这篇文章中,我将描述数据准备和模型准备中几种技术的组合,这些技术可以帮助缓解类别不平衡,并在所有类别中产生更高的平均精度。
不平衡数据集
在本例中,我将通过一个理论项目为无人机镜头构建内容识别模型。作为样本数据,我有800张从谷歌地图随机抽取的图像。在50多个类中有1M对象。
数据集是数据不平衡的。有些类别的频率要高得多——高达100倍。
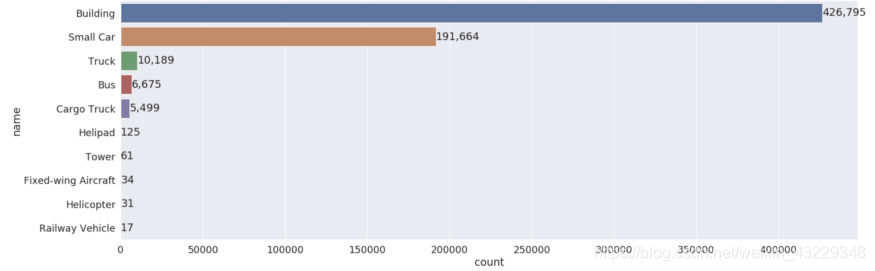
如果您直接预测数据集中的一个对象是一个“Building”,那么您有50%的几率是正确的。因此,这种类别不平衡会让你相信你的模型比实际情况要好。
这些设置对目标检测算法来说具有挑战性,因为模型试图减少整个数据集的分类错误。因此,许多模型更喜欢近似类别平衡的数据集。
这里有一些处理这种不平衡的方法。
1:切割而不是向下采样
简而言之,原始图像太大,无法放入神经网络的输入层。一幅1200万像素的无人机图像是4000 x 3000像素。输入到物体探测器的普通图像大小为512 x 512像素或更小。
虽然可以对原始图像进行下采样,但会丢失重要的信息,而且模型对小对象类的精度也会降低。
这个例子数据集中的少数类都比Building类要小得多,所以取样对少数族裔群体的影响不成比例。
将原始图像切成更小的块是向下采样的一种替代方法。通过保留完整的分辨率,我们可以确保较小的少数类不会变得更难识别。
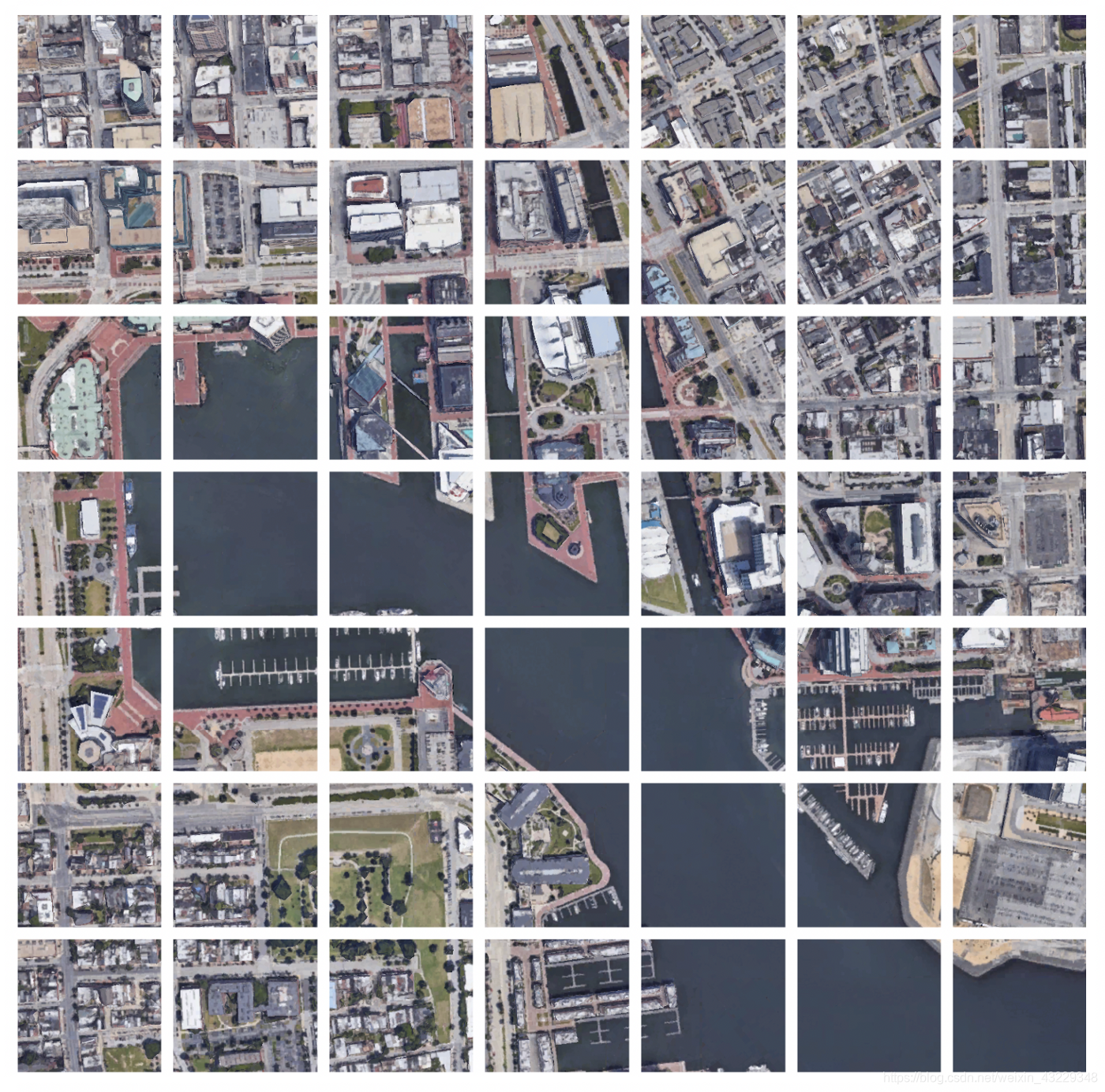
每个图像被切割成更小的方形单元,这些单元可以在保留原始图像分辨率的同时单独输入网络。为了确保切割边界的对象不会丢失信息,你可以在边界处保持一些重叠(例如25%的重叠)。
注意:一些数据集可能包含大尺寸视差的对象。你可能想要保留完整的原始分辨率,以便能够识别微小的物体,但也有一些物体太大,以至于无法放在一个贴图中。在这种情况下,可能需要使用一些全分辨率贴图和一些下采样的全图图像来构建训练数据集。
对使用切割方法的数据集进行训练所得到的模型mAP要高于对图像分辨率进行重新缩放的数据集进行训练所得到的模型mAP。
缺点:虽然模型可以在小对象类中表现得更好,但使用切割方法确实会导致更长的训练时间。例如,这种切割方法增加了30%的mAP,但也增加了60%的训练运行时间。
2:合并相似的类别
有些类别数目几乎相等,例如“Fixed wing aircraft”和“Cargo plane”。这两个类的平均边界框直径都是18个像素。对于低像素对象,这种级别的类细粒度对模型来说可能很难学习——特别是在每个类没有很多数据点的情况下。
我们决定将外观相似的对象合并到单个类中,这减少了类的数量,并稍微减少了类分布的不平衡。
注意:当合并标签时,最好是有领域专家的参与(我这里没有!)。它们不仅可以建议将哪些类分组在一起是有意义的,而且还可以描述最终用户工作流中必须绝对保留原始类的位置。例如,可能很容易将“Tank”重新分类为“Truck”,但用户工作流可能会对“Tank”类采取高度具体的操作。此外,为了帮助简化合并过程,您可以通过标识创建最多的类组来创建一个合并候选列表,以供人工审查。
在合并之后,我们有了16个新类别vs. 50个原来的类别-但是类别的不平衡有多好?让我们看看这两个分布。
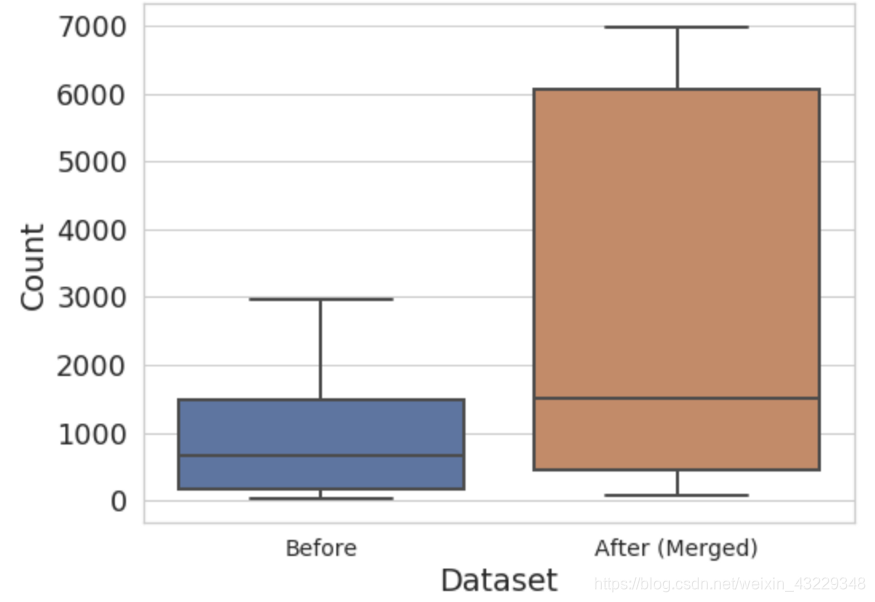
在合并之前,75%的类包含少于1,500个实例。类别合并后,每个类别的中位数超过1500。(图中没有显示异常值,包括拥有42.6万个目标的“Building”类)。
3:重采样特定类
传统的解决机器学习中大类别不平衡的方法是调整训练集中的类表示。
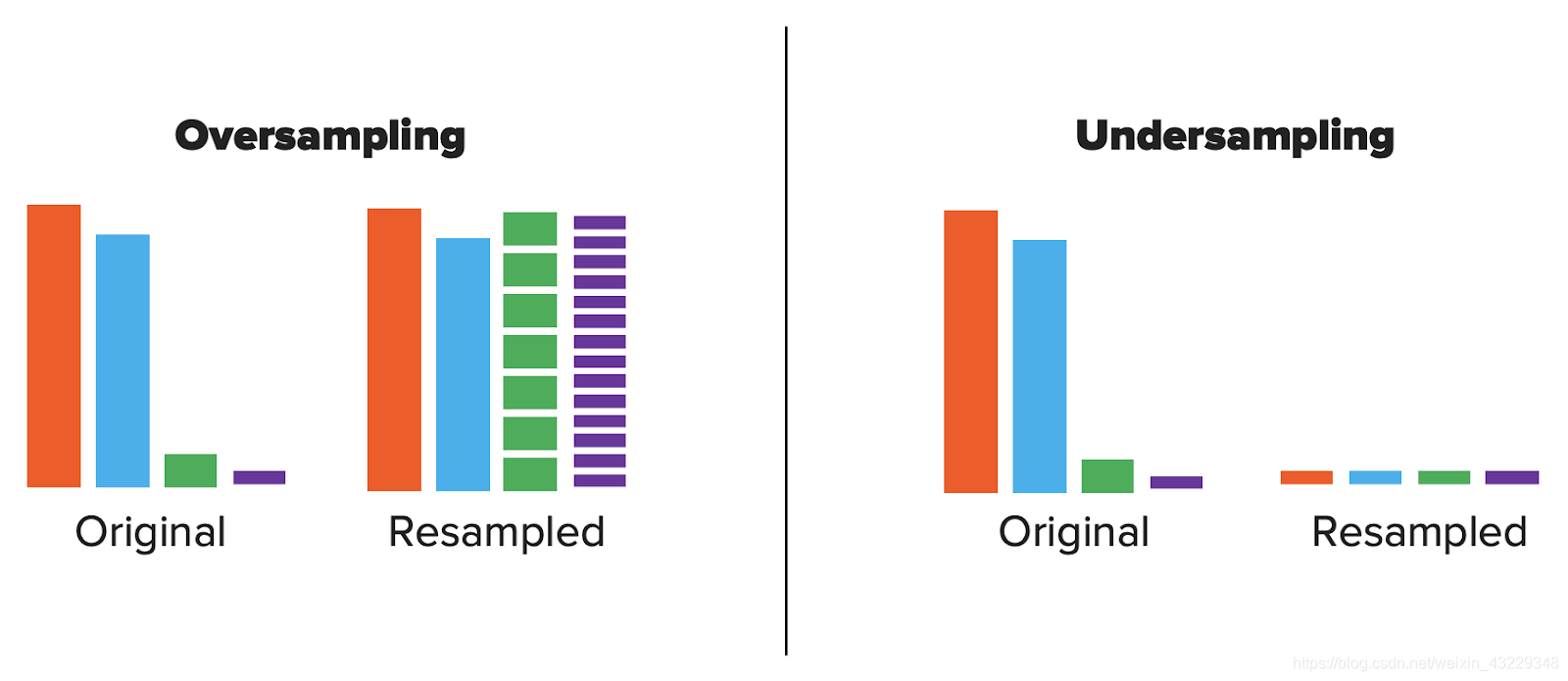
对不频繁的类进行过采样是增加少数类的数目,以匹配多数类的数量。这可以通过几种方式执行,例如生成合成数据或从少数类中复制对象。(例如通过sklearn的resample或TensorFlow的tf.data采样器或PyTorch的WeightedRandomSampler)。缺点是,它可能导致过度拟合采样过的类。
对欠采样是将多数类别的对象删除,以便与少数类别的数量相匹配。缺点是,通过删除数据点,您可能会删除有价值的信息,或者导致对真实数据的不好泛化。或者,不平衡可能非常糟糕,以致于采样不足的结果对数据集来说太小了。
注意:这两个更改都应该在将数据分为训练集和验证集之后进行,以确保验证集中的数据没有包含在训练集中。
对于这个示例数据集,我们通过在最终的训练数据集中有选择地欠采样。包含在每个贴图中的标签被计数并存储在一个数据帧中。然后我们创建了一个排序步骤来包含或丢弃贴图。所有包含至少一个少数标签实例的图像(除了“Building”和“Small Cars”)都包含在训练数据集中。然后,为了使数据集更完整,我们还包含了10%只包含最常见类的贴图。最终分布如下:
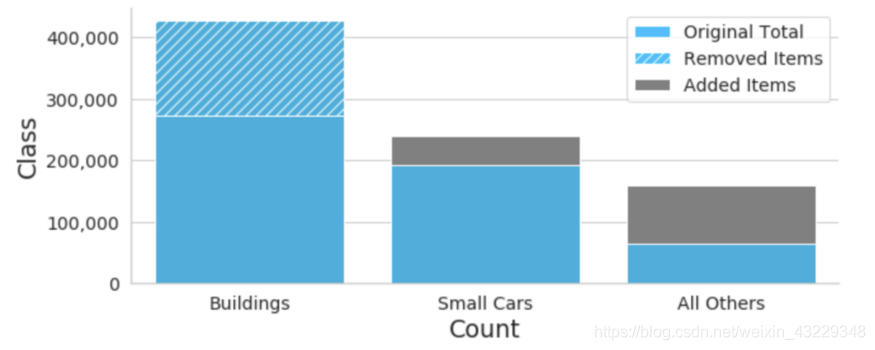
贴图策略也使训练更有效。
除了提高少数类的平均精度,我们还减少了训练时间(通过减少数据集大小),同时只删除了大部分冗余信息。
另一个好处是,你可以剔除那些包含零边界框的贴图。对于航空摄影,原始的全尺寸图像有时只包含5-10个注释,这导致大量的“空”贴图。在太多的空贴图上训练的模型可能会预测没有边界框作为最优解。
通过用例和内容类型,许多大型图像包含可以在训练前删除的死空间。例如,看看数字化的病理学幻灯片上有多少块是100%白色的:
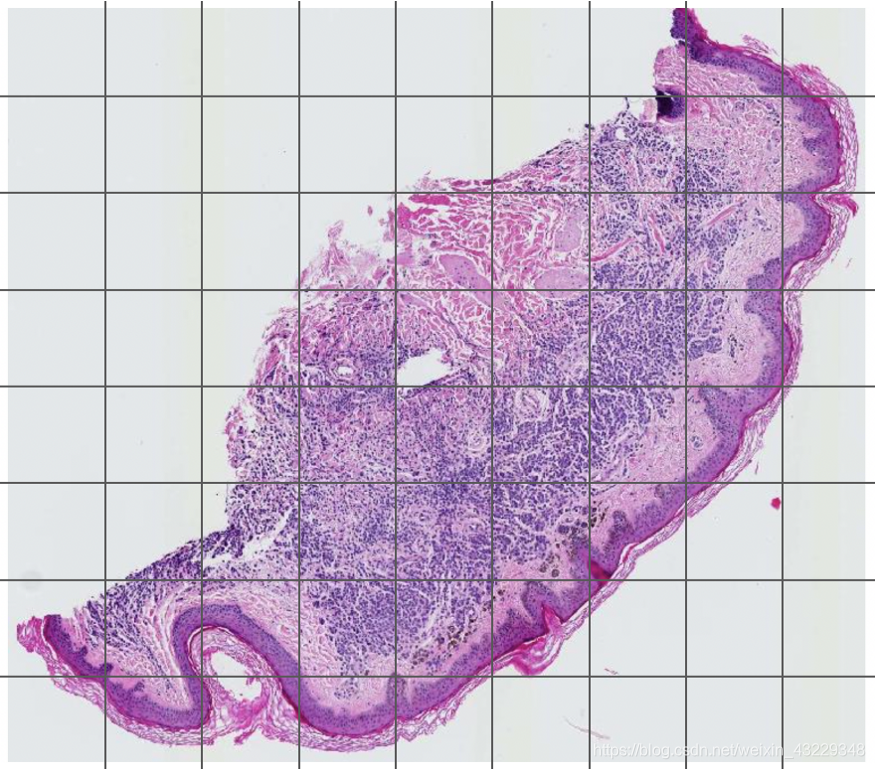
因此,当您有大的原始图像保证包含空白时,通常最好开始将贴图数据集视为新的训练数据。您可以开始使用更细粒度的控制来探索和清理它。
4.损失函数
除了“Building”类的对象比一些少数类多100倍之外,图片中空白的背景区域实际上是另一个主导的多数类。该模型将看到大量容易分类的背景区域——有时前景与背景区域的比例为1:1000。当多对象的类相对容易分类时,它们可以主导整体损失,这将引导梯度下降以优化那些多对象类的检测。
不要平等对待每一个错误,要把稀有类上的错误看得比普通类上的错误更重要。
因此,我们使用了FocalLoss。损失函数是基于每个对象的预测概率的动态函数。在[0,5]之间可调γ使分类良好的对象(p > 0.5)的损失趋近于零。这一变化降低了多样本类的损失在总损失中的主导地位。
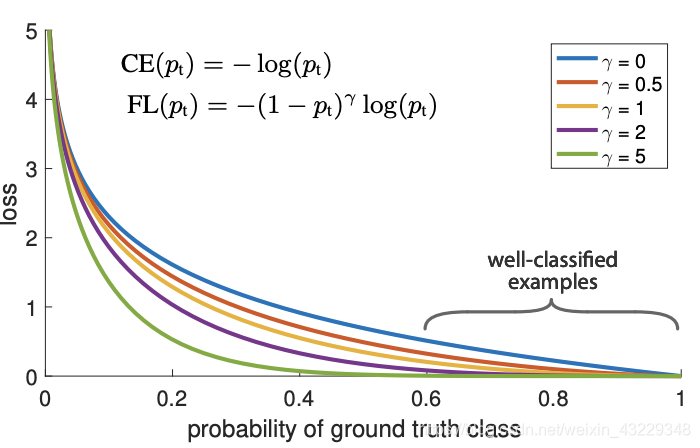
对于合并类数据集,实现focal loss提高了少数类的平均精度,并在多数类上保持了相对较好的平均精度。
总结
数据集一开始就有显著的类不平衡,这并不罕见,对于可能包含大量“空”(或背景)类的图像数据集,这可能会进一步加剧。
如果不考虑少数类,模型可以达到一个准确的上限,可以很容易地预测多数类,但整体模型的准确性可能不会提高,除非采取措施考虑类别不平衡和提高少数类的准确率。
通常情况下,这可能意味着数据准备技术(如重新采样)和模型准备技术(如调整损失函数)的组合。其中一些技术有缺点,如增加模型训练时间,但通常是值得的,因为它们最终会产生更高的mAP。
数据科学家应该1)准备花时间缓解类别不平衡2)期望迭代他们的训练数据集。
参考目录
https://towardsdatascience.com/4-ways-to-improve-class-imbalance-for-image-data-9adec8f390f1

















 293
293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









